 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Fine-Tuning and Prompt Optimization: Two Great Steps that Work Better Together
Jul 15, 2024Natural Language Processing (NLP) systems are increasingly taking the form of multi-stage pipelines involving multiple distinct language models (LMs) and prompting strategies. Here we address the question of how to fine-tune such systems to improve their performance. We cast this as a problem of optimizing the underlying LM weights and the prompting strategies together, and consider a challenging but highly realistic scenario in which we have no gold labels for any intermediate stages in the pipeline. To address this challenge, we evaluate approximate optimization strategies in which we bootstrap training labels for all pipeline stages and use these to optimize the pipeline's prompts and fine-tune its weights alternatingly. In experiments with multi-hop QA, mathematical reasoning, and feature-based classification, we find that simple approaches for optimizing the prompts and weights together outperform directly optimizing weights alone and prompts alone by up to 65% and 5%, respectively, on average across LMs and tasks. We will release our new optimizers in DSPy at http://dspy.ai
Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Jan 07, 2024

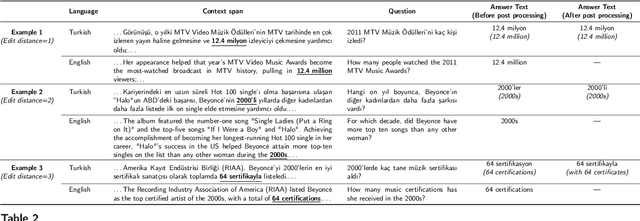

Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource languages. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA for Turkish. We obtain a performance improvement of 9-34% in the EM score and 13-33% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models by using two versions of Wikipedia dumps spanning two years. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available.
Ecosystem Graphs: The Social Footprint of Foundation Models
Mar 28, 2023Foundation models (e.g. ChatGPT, StableDiffusion) pervasively influence society, warranting immediate social attention. While the models themselves garner much attention, to accurately characterize their impact, we must consider the broader sociotechnical ecosystem. We propose Ecosystem Graphs as a documentation framework to transparently centralize knowledge of this ecosystem. Ecosystem Graphs is composed of assets (datasets, models, applications) linked together by dependencies that indicate technical (e.g. how Bing relies on GPT-4) and social (e.g. how Microsoft relies on OpenAI) relationships. To supplement the graph structure, each asset is further enriched with fine-grained metadata (e.g. the license or training emissions). We document the ecosystem extensively at https://crfm.stanford.edu/ecosystem-graphs/. As of March 16, 2023, we annotate 262 assets (64 datasets, 128 models, 70 applications) from 63 organizations linked by 356 dependencies. We show Ecosystem Graphs functions as a powerful abstraction and interface for achieving the minimum transparency required to address myriad use cases. Therefore, we envision Ecosystem Graphs will be a community-maintained resource that provides value to stakeholders spanning AI researchers, industry professionals, social scientists, auditors and policymakers.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022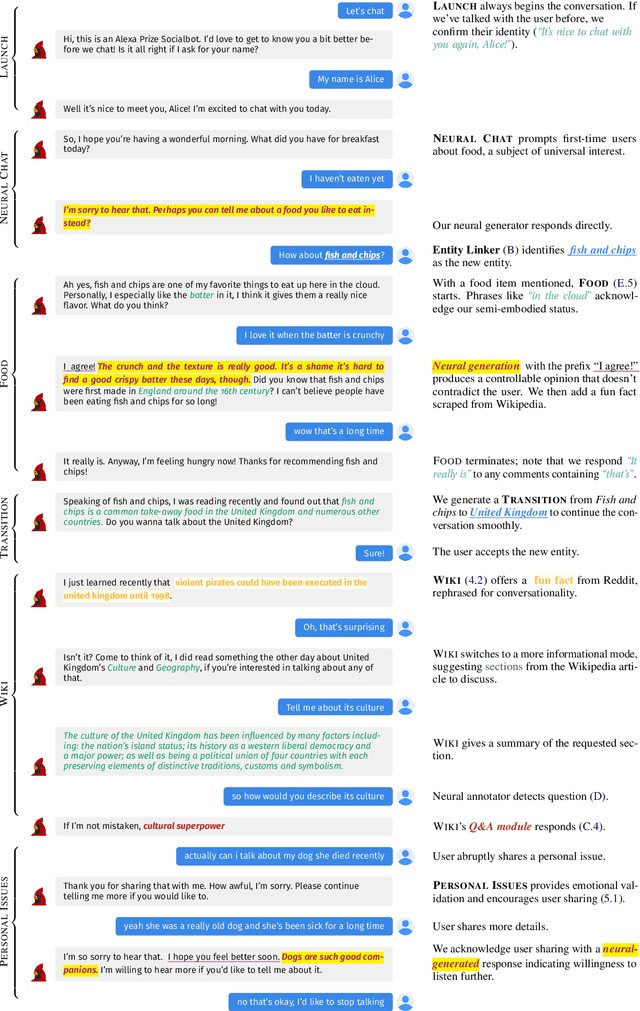


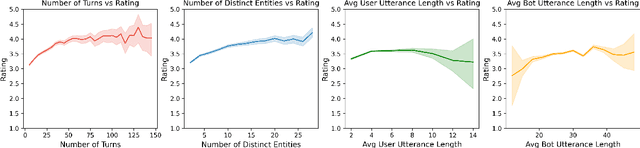
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Neural Generation Meets Real People: Towards Emotionally Engaging Mixed-Initiative Conversations
Sep 05, 2020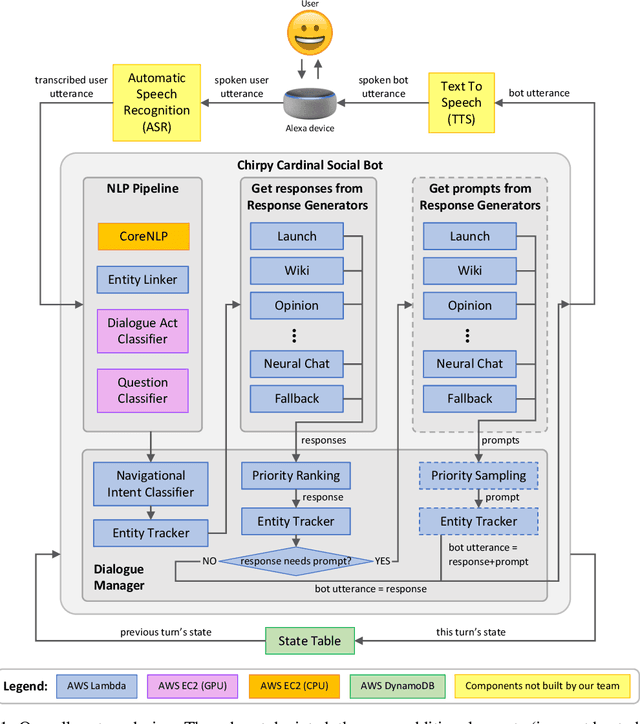
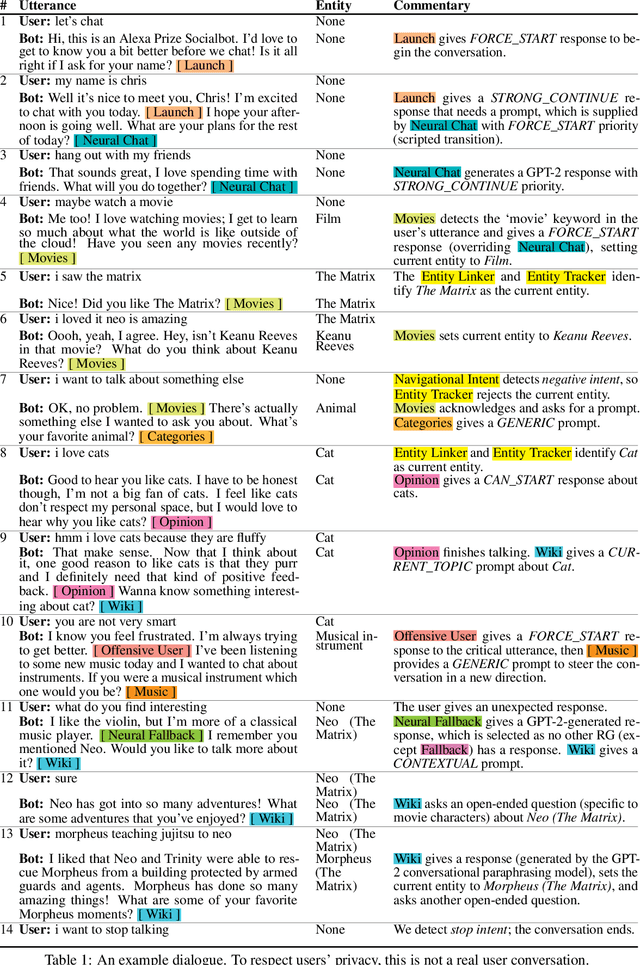

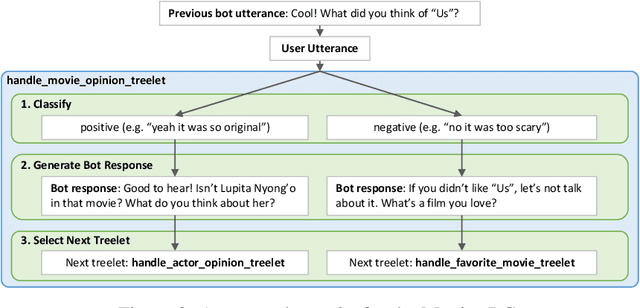
We present Chirpy Cardinal, an open-domain dialogue agent, as a research platform for the 2019 Alexa Prize competition. Building an open-domain socialbot that talks to real people is challenging - such a system must meet multiple user expectations such as broad world knowledge, conversational style, and emotional connection. Our socialbot engages users on their terms - prioritizing their interests, feelings and autonomy. As a result, our socialbot provides a responsive, personalized user experience, capable of talking knowledgeably about a wide variety of topics, as well as chatting empathetically about ordinary life. Neural generation plays a key role in achieving these goals, providing the backbone for our conversational and emotional tone. At the end of the competition, Chirpy Cardinal progressed to the finals with an average rating of 3.6/5.0, a median conversation duration of 2 minutes 16 seconds, and a 90th percentile duration of over 12 minutes.