 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Bridging the Gap: A Decade Review of Time-Series Clustering Methods
Dec 29, 2024Time series, as one of the most fundamental representations of sequential data, has been extensively studied across diverse disciplines, including computer science, biology, geology, astronomy, and environmental sciences. The advent of advanced sensing, storage, and networking technologies has resulted in high-dimensional time-series data, however, posing significant challenges for analyzing latent structures over extended temporal scales. Time-series clustering, an established unsupervised learning strategy that groups similar time series together, helps unveil hidden patterns in these complex datasets. In this survey, we trace the evolution of time-series clustering methods from classical approaches to recent advances in neural networks. While previous surveys have focused on specific methodological categories, we bridge the gap between traditional clustering methods and emerging deep learning-based algorithms, presenting a comprehensive, unified taxonomy for this research area. This survey highlights key developments and provides insights to guide future research in time-series clustering.
A Survey on Time-Series Distance Measures
Dec 29, 2024

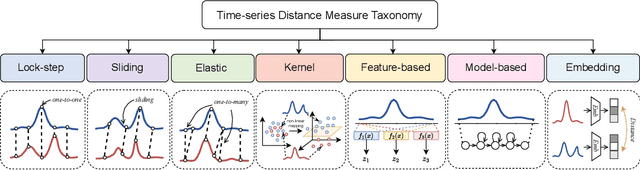
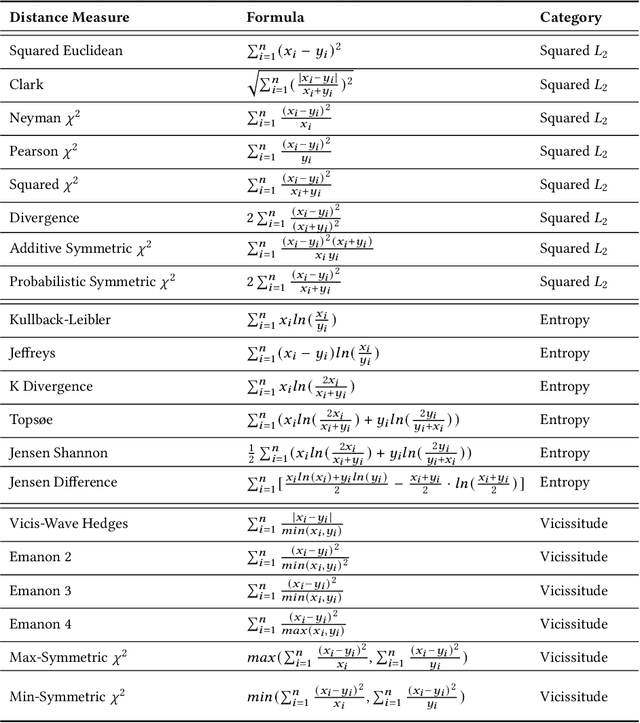
Distance measures have been recognized as one of the fundamental building blocks in time-series analysis tasks, e.g., querying, indexing, classification, clustering, anomaly detection, and similarity search. The vast proliferation of time-series data across a wide range of fields has increased the relevance of evaluating the effectiveness and efficiency of these distance measures. To provide a comprehensive view of this field, this work considers over 100 state-of-the-art distance measures, classified into 7 categories: lock-step measures, sliding measures, elastic measures, kernel measures, feature-based measures, model-based measures, and embedding measures. Beyond providing comprehensive mathematical frameworks, this work also delves into the distinctions and applications across these categories for both univariate and multivariate cases. By providing comprehensive collections and insights, this study paves the way for the future development of innovative time-series distance measures.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022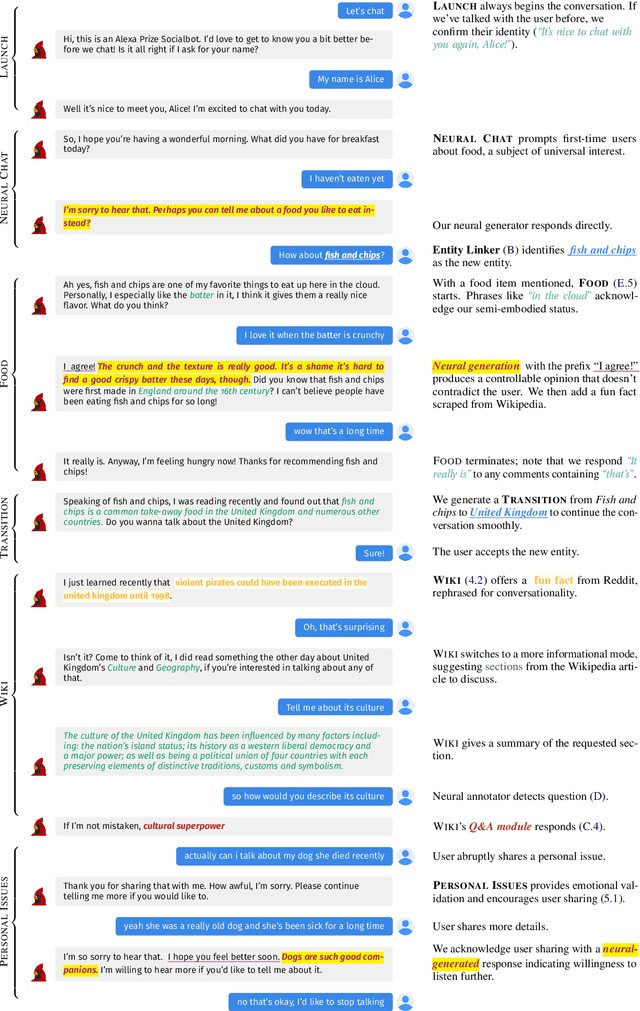


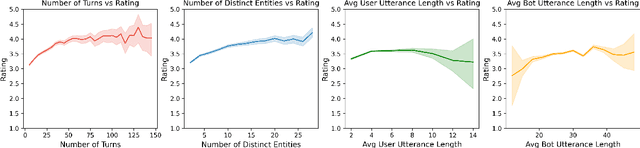
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Multimodal Reward Shaping for Efficient Exploration in Reinforcement Learning
Jul 19, 2021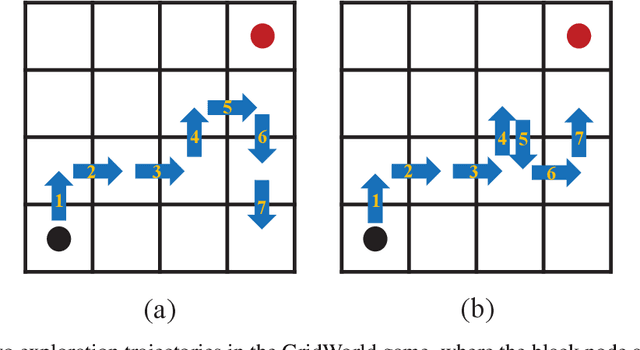
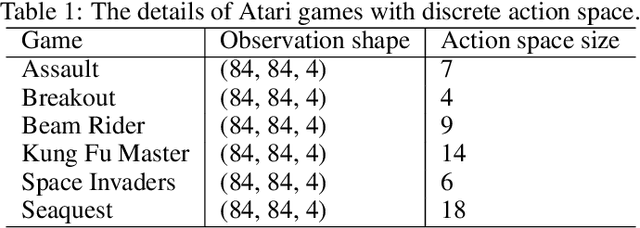
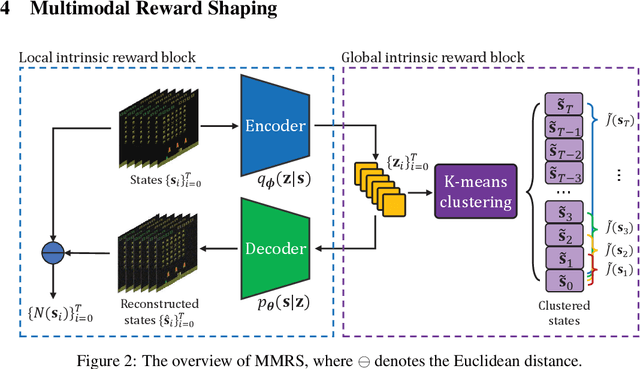
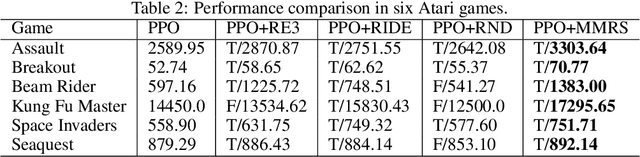
Maintaining long-term exploration ability remains one of the challenges of deep reinforcement learning (DRL). In practice, the reward shaping-based approaches are leveraged to provide intrinsic rewards for the agent to incentivize motivation. However, most existing IRS modules rely on attendant models or additional memory to record and analyze learning procedures, which leads to high computational complexity and low robustness. Moreover, they overemphasize the influence of a single state on exploration, which cannot evaluate the exploration performance from a global perspective. To tackle the problem, state entropy-based methods are proposed to encourage the agent to visit the state space more equitably. However, the estimation error and sample complexity are prohibitive when handling environments with high-dimensional observation. In this paper, we introduce a novel metric entitled Jain's fairness index (JFI) to replace the entropy regularizer, which requires no additional models or memory. In particular, JFI overcomes the vanishing intrinsic rewards problem and can be generalized into arbitrary tasks. Furthermore, we use a variational auto-encoder (VAE) model to capture the life-long novelty of states. Finally, the global JFI score and local state novelty are combined to form a multimodal intrinsic reward, controlling the exploration extent more precisely. Finally, extensive simulation results demonstrate that our multimodal reward shaping (MMRS) method can achieve higher performance in contrast to other benchmark schemes.
Neural Generation Meets Real People: Towards Emotionally Engaging Mixed-Initiative Conversations
Sep 05, 2020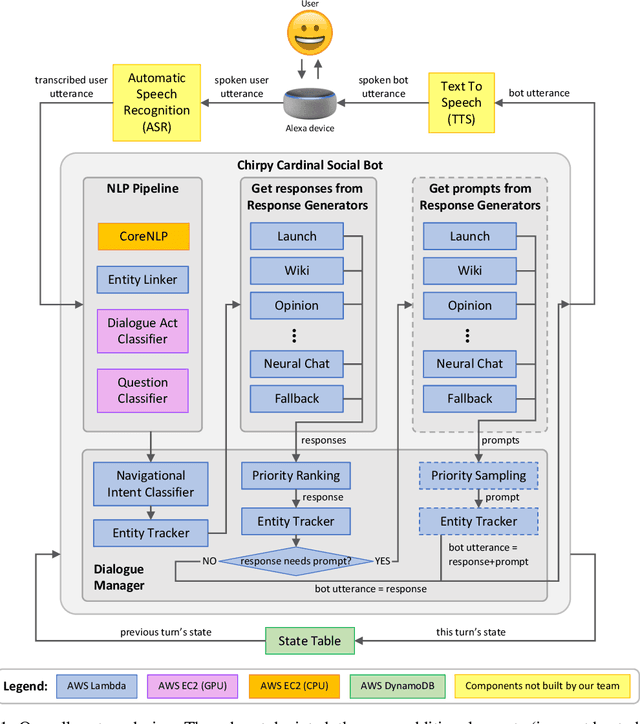
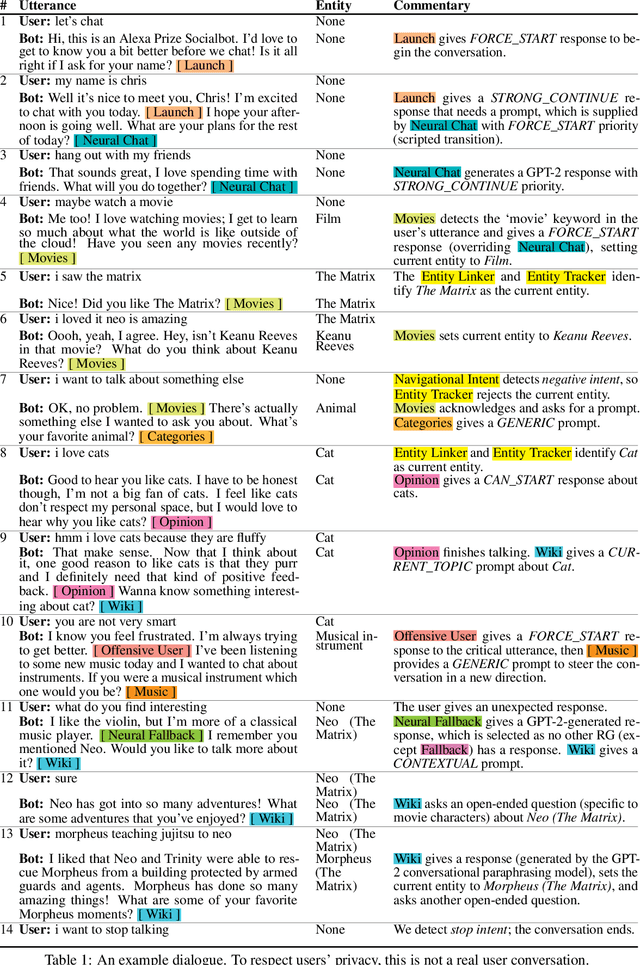

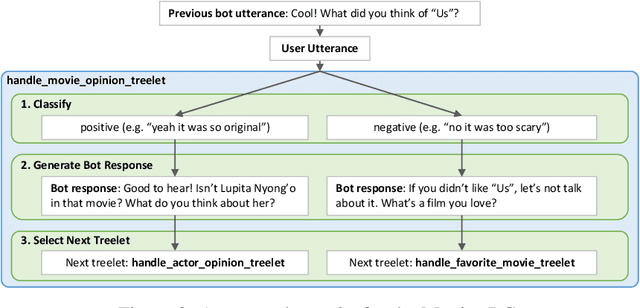
We present Chirpy Cardinal, an open-domain dialogue agent, as a research platform for the 2019 Alexa Prize competition. Building an open-domain socialbot that talks to real people is challenging - such a system must meet multiple user expectations such as broad world knowledge, conversational style, and emotional connection. Our socialbot engages users on their terms - prioritizing their interests, feelings and autonomy. As a result, our socialbot provides a responsive, personalized user experience, capable of talking knowledgeably about a wide variety of topics, as well as chatting empathetically about ordinary life. Neural generation plays a key role in achieving these goals, providing the backbone for our conversational and emotional tone. At the end of the competition, Chirpy Cardinal progressed to the finals with an average rating of 3.6/5.0, a median conversation duration of 2 minutes 16 seconds, and a 90th percentile duration of over 12 minutes.
A Gaussian Particle Filter Approach for Sensors to Track Multiple Moving Targets
Jan 11, 2015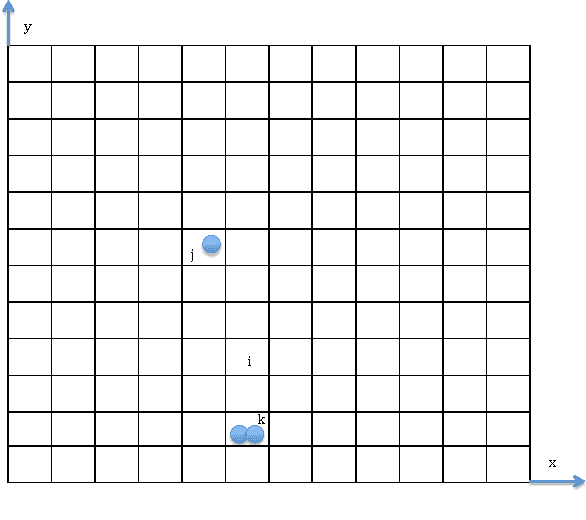
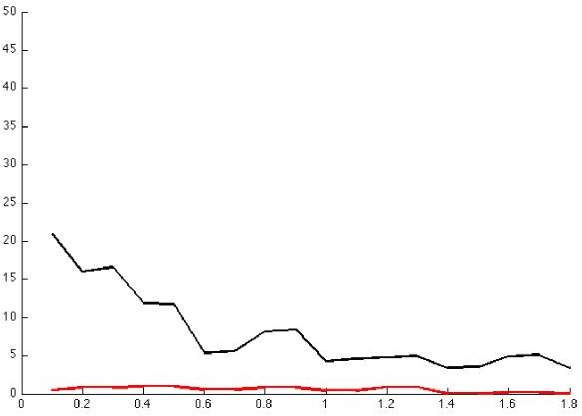
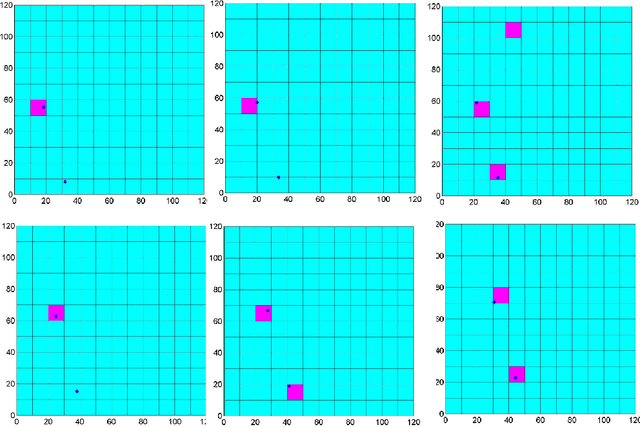
In a variety of problems, the number and state of multiple moving targets are unknown and are subject to be inferred from their measurements obtained by a sensor with limited sensing ability. This type of problems is raised in a variety of applications, including monitoring of endangered species, cleaning, and surveillance. Particle filters are widely used to estimate target state from its prior information and its measurements that recently become available, especially for the cases when the measurement model and the prior distribution of state of interest are non-Gaussian. However, the problem of estimating number of total targets and their state becomes intractable when the number of total targets and the measurement-target association are unknown. This paper presents a novel Gaussian particle filter technique that combines Kalman filter and particle filter for estimating the number and state of total targets based on the measurement obtained online. The estimation is represented by a set of weighted particles, different from classical particle filter, where each particle is a Gaussian distribution instead of a point mass.