 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Marketing? On the Information Value of AI Benchmarks for Practitioners
Dec 07, 2024Public AI benchmark results are widely broadcast by model developers as indicators of model quality within a growing and competitive market. However, these advertised scores do not necessarily reflect the traits of interest to those who will ultimately apply AI models. In this paper, we seek to understand if and how AI benchmarks are used to inform decision-making. Based on the analyses of interviews with 19 individuals who have used, or decided against using, benchmarks in their day-to-day work, we find that across these settings, participants use benchmarks as a signal of relative performance difference between models. However, whether this signal was considered a definitive sign of model superiority, sufficient for downstream decisions, varied. In academia, public benchmarks were generally viewed as suitable measures for capturing research progress. By contrast, in both product and policy, benchmarks -- even those developed internally for specific tasks -- were often found to be inadequate for informing substantive decisions. Of the benchmarks deemed unsatisfactory, respondents reported that their goals were neither well-defined nor reflective of real-world use. Based on the study results, we conclude that effective benchmarks should provide meaningful, real-world evaluations, incorporate domain expertise, and maintain transparency in scope and goals. They must capture diverse, task-relevant capabilities, be challenging enough to avoid quick saturation, and account for trade-offs in model performance rather than relying on a single score. Additionally, proprietary data collection and contamination prevention are critical for producing reliable and actionable results. By adhering to these criteria, benchmarks can move beyond mere marketing tricks into robust evaluative frameworks.
BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
Nov 20, 2024



AI models are increasingly prevalent in high-stakes environments, necessitating thorough assessment of their capabilities and risks. Benchmarks are popular for measuring these attributes and for comparing model performance, tracking progress, and identifying weaknesses in foundation and non-foundation models. They can inform model selection for downstream tasks and influence policy initiatives. However, not all benchmarks are the same: their quality depends on their design and usability. In this paper, we develop an assessment framework considering 46 best practices across an AI benchmark's lifecycle and evaluate 24 AI benchmarks against it. We find that there exist large quality differences and that commonly used benchmarks suffer from significant issues. We further find that most benchmarks do not report statistical significance of their results nor allow for their results to be easily replicated. To support benchmark developers in aligning with best practices, we provide a checklist for minimum quality assurance based on our assessment. We also develop a living repository of benchmark assessments to support benchmark comparability, accessible at betterbench.stanford.edu.
Evaluating Human-Language Model Interaction
Dec 20, 2022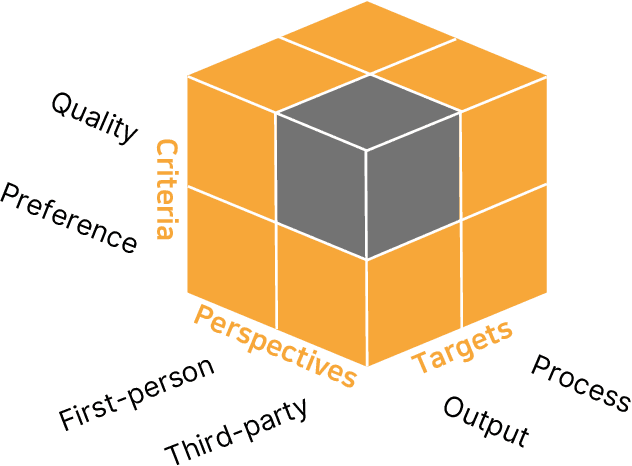
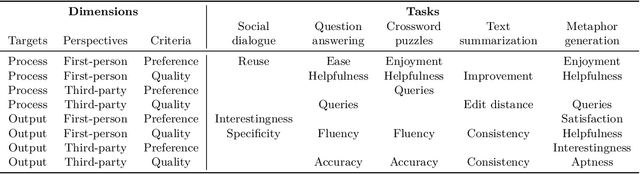
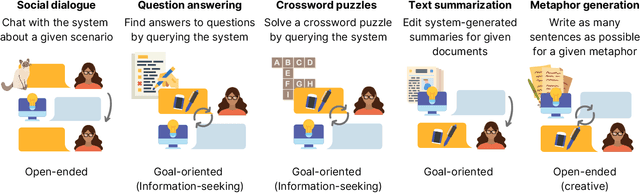

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022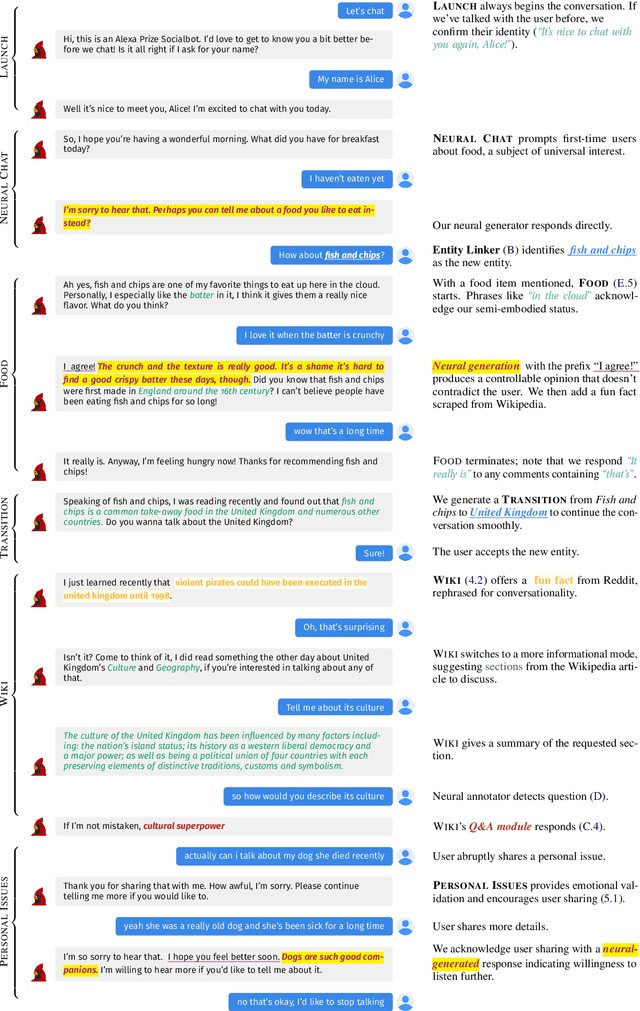


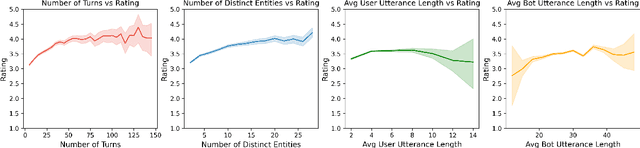
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Neural Generation Meets Real People: Towards Emotionally Engaging Mixed-Initiative Conversations
Sep 05, 2020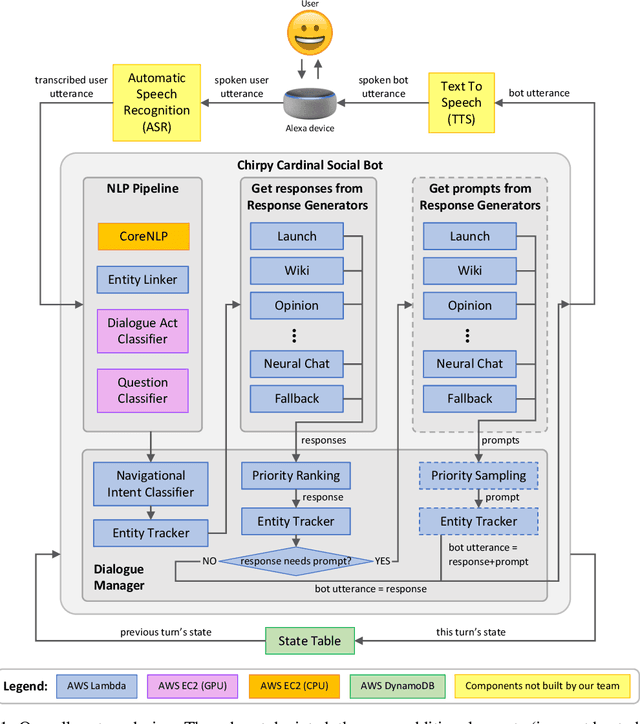
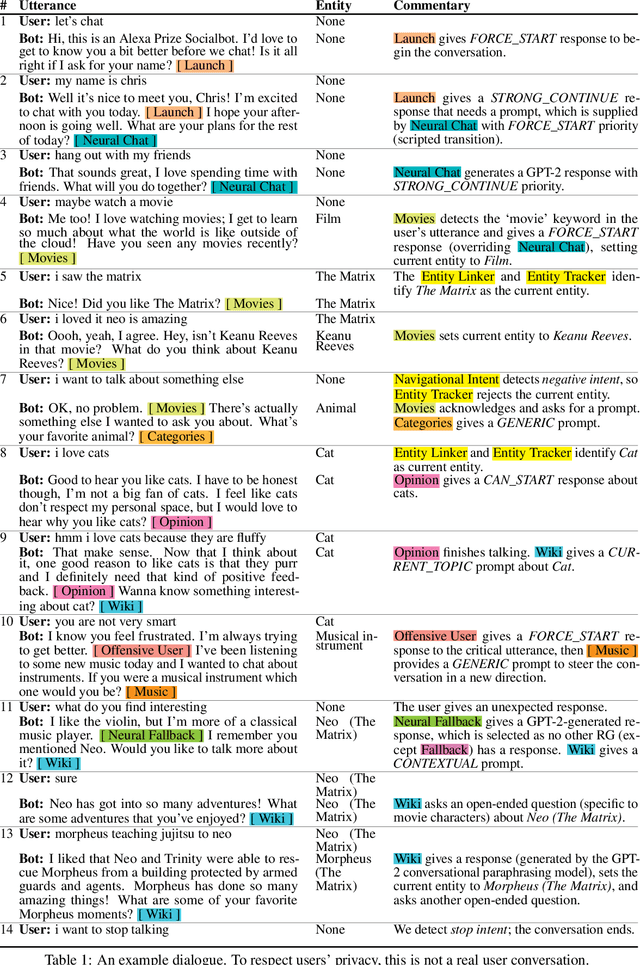

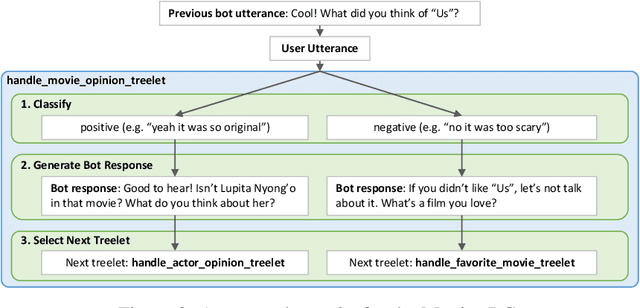
We present Chirpy Cardinal, an open-domain dialogue agent, as a research platform for the 2019 Alexa Prize competition. Building an open-domain socialbot that talks to real people is challenging - such a system must meet multiple user expectations such as broad world knowledge, conversational style, and emotional connection. Our socialbot engages users on their terms - prioritizing their interests, feelings and autonomy. As a result, our socialbot provides a responsive, personalized user experience, capable of talking knowledgeably about a wide variety of topics, as well as chatting empathetically about ordinary life. Neural generation plays a key role in achieving these goals, providing the backbone for our conversational and emotional tone. At the end of the competition, Chirpy Cardinal progressed to the finals with an average rating of 3.6/5.0, a median conversation duration of 2 minutes 16 seconds, and a 90th percentile duration of over 12 minutes.