 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Task Completion Time Updates Using POMDPs
Mar 16, 2026Managing announced task completion times is a fundamental control problem in project management. While extensive research exists on estimating task durations and task scheduling, the problem of when and how to update completion times communicated to stakeholders remains understudied. Organizations must balance announcement accuracy against the costs of frequent timeline updates, which can erode stakeholder trust and trigger costly replanning. Despite the prevalence of this problem, current approaches rely on static predictions or ad-hoc policies that fail to account for the sequential nature of announcement management. In this paper, we formulate the task announcement problem as a Partially Observable Markov Decision Process (POMDP) where the control policy must decide when to update announced completion times based on noisy observations of true task completion. Since most state variables (current time and previous announcements) are fully observable, we leverage the Mixed Observability MDP (MOMDP) framework to enable more efficient policy optimization. Our reward structure captures the dual costs of announcement errors and update frequency, enabling synthesis of optimal announcement control policies. Using off-the-shelf solvers, we generate policies that act as feedback controllers, adaptively managing announcements based on belief state evolution. Simulation results demonstrate significant improvements in both accuracy and announcement stability compared to baseline strategies, achieving up to 75\% reduction in unnecessary updates while maintaining or improving prediction accuracy.
Learning to Trust: Bayesian Adaptation to Varying Suggester Reliability in Sequential Decision Making
Nov 15, 2025



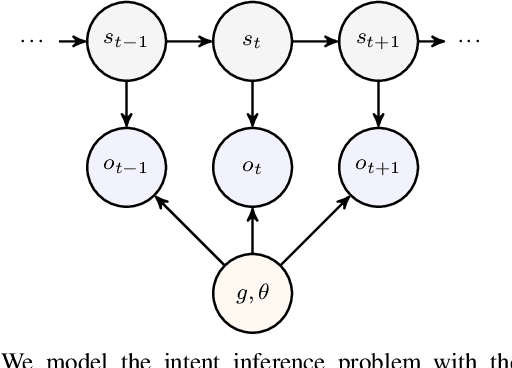
Autonomous agents operating in sequential decision-making tasks under uncertainty can benefit from external action suggestions, which provide valuable guidance but inherently vary in reliability. Existing methods for incorporating such advice typically assume static and known suggester quality parameters, limiting practical deployment. We introduce a framework that dynamically learns and adapts to varying suggester reliability in partially observable environments. First, we integrate suggester quality directly into the agent's belief representation, enabling agents to infer and adjust their reliance on suggestions through Bayesian inference over suggester types. Second, we introduce an explicit ``ask'' action allowing agents to strategically request suggestions at critical moments, balancing informational gains against acquisition costs. Experimental evaluation demonstrates robust performance across varying suggester qualities, adaptation to changing reliability, and strategic management of suggestion requests. This work provides a foundation for adaptive human-agent collaboration by addressing suggestion uncertainty in uncertain environments.
Physics-informed Gaussian Processes for Safe Envelope Expansion
Jan 02, 2025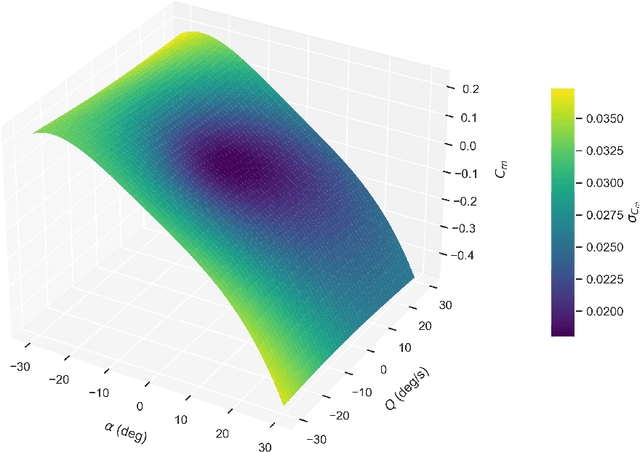
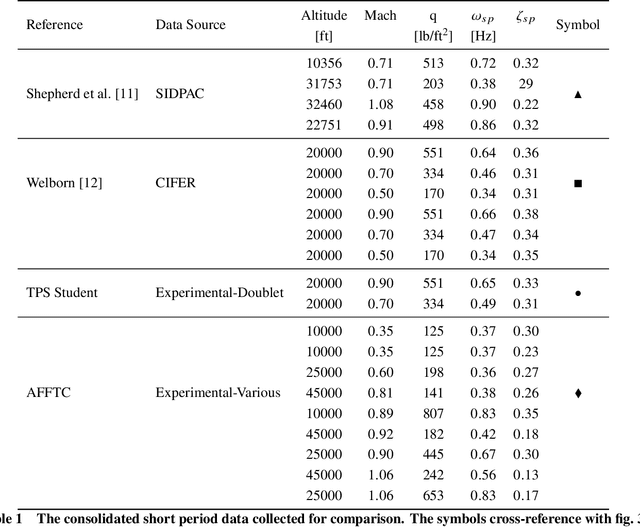
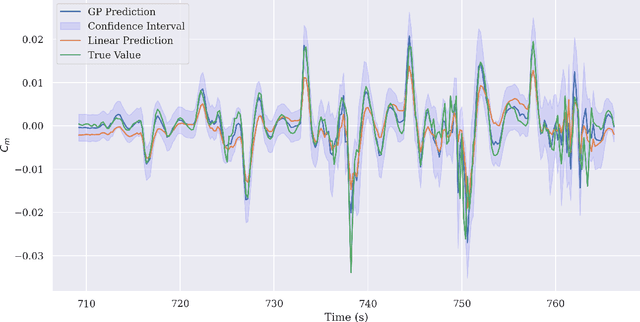
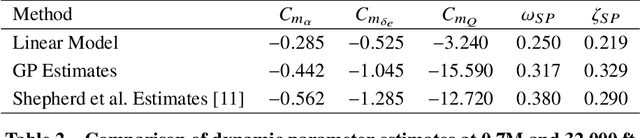
Flight test analysis often requires predefined test points with arbitrarily tight tolerances, leading to extensive and resource-intensive experimental campaigns. To address this challenge, we propose a novel approach to flight test analysis using Gaussian processes (GPs) with physics-informed mean functions to estimate aerodynamic quantities from arbitrary flight test data, validated using real T-38 aircraft data collected in collaboration with the United States Air Force Test Pilot School. We demonstrate our method by estimating the pitching moment coefficient without requiring predefined or repeated flight test points, significantly reducing the need for extensive experimental campaigns. Our approach incorporates aerodynamic models as priors within the GP framework, enhancing predictive accuracy across diverse flight conditions and providing robust uncertainty quantification. Key contributions include the integration of physics-based priors in a probabilistic model, which allows for precise computation from arbitrary flight test maneuvers, and the demonstration of our method capturing relevant dynamic characteristics such as short-period mode behavior. The proposed framework offers a scalable and generalizable solution for efficient data-driven flight test analysis and is able to accurately predict the short period frequency and damping for the T-38 across several Mach and dynamic pressure profiles.
More than Marketing? On the Information Value of AI Benchmarks for Practitioners
Dec 07, 2024Public AI benchmark results are widely broadcast by model developers as indicators of model quality within a growing and competitive market. However, these advertised scores do not necessarily reflect the traits of interest to those who will ultimately apply AI models. In this paper, we seek to understand if and how AI benchmarks are used to inform decision-making. Based on the analyses of interviews with 19 individuals who have used, or decided against using, benchmarks in their day-to-day work, we find that across these settings, participants use benchmarks as a signal of relative performance difference between models. However, whether this signal was considered a definitive sign of model superiority, sufficient for downstream decisions, varied. In academia, public benchmarks were generally viewed as suitable measures for capturing research progress. By contrast, in both product and policy, benchmarks -- even those developed internally for specific tasks -- were often found to be inadequate for informing substantive decisions. Of the benchmarks deemed unsatisfactory, respondents reported that their goals were neither well-defined nor reflective of real-world use. Based on the study results, we conclude that effective benchmarks should provide meaningful, real-world evaluations, incorporate domain expertise, and maintain transparency in scope and goals. They must capture diverse, task-relevant capabilities, be challenging enough to avoid quick saturation, and account for trade-offs in model performance rather than relying on a single score. Additionally, proprietary data collection and contamination prevention are critical for producing reliable and actionable results. By adhering to these criteria, benchmarks can move beyond mere marketing tricks into robust evaluative frameworks.
Optimal Control of Mechanical Ventilators with Learned Respiratory Dynamics
Nov 12, 2024Deciding on appropriate mechanical ventilator management strategies significantly impacts the health outcomes for patients with respiratory diseases. Acute Respiratory Distress Syndrome (ARDS) is one such disease that requires careful ventilator operation to be effectively treated. In this work, we frame the management of ventilators for patients with ARDS as a sequential decision making problem using the Markov decision process framework. We implement and compare controllers based on clinical guidelines contained in the ARDSnet protocol, optimal control theory, and learned latent dynamics represented as neural networks. The Pulse Physiology Engine's respiratory dynamics simulator is used to establish a repeatable benchmark, gather simulated data, and quantitatively compare these controllers. We score performance in terms of measured improvement in established ARDS health markers (pertaining to improved respiratory rate, oxygenation, and vital signs). Our results demonstrate that techniques leveraging neural networks and optimal control can automatically discover effective ventilation management strategies without access to explicit ventilator management procedures or guidelines (such as those defined in the ARDSnet protocol).
Large-Scale Multi-Robot Assembly Planning for Autonomous Manufacturing
Oct 31, 2023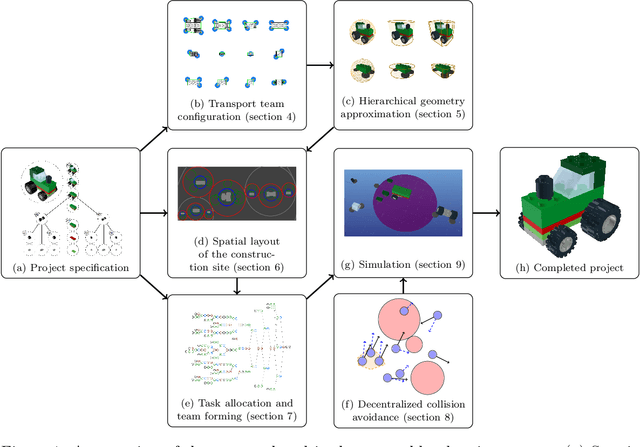


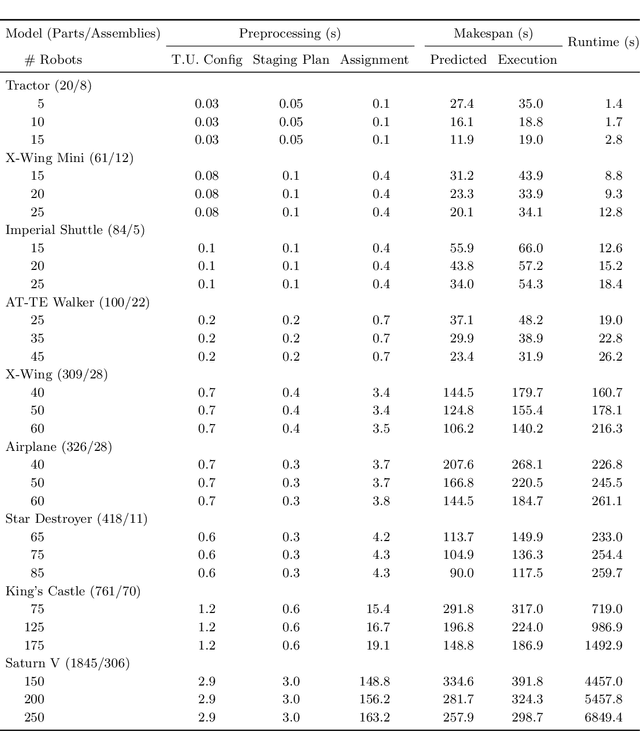
Mobile autonomous robots have the potential to revolutionize manufacturing processes. However, employing large robot fleets in manufacturing requires addressing challenges including collision-free movement in a shared workspace, effective multi-robot collaboration to manipulate and transport large payloads, complex task allocation due to coupled manufacturing processes, and spatial planning for parallel assembly and transportation of nested subassemblies. We propose a full algorithmic stack for large-scale multi-robot assembly planning that addresses these challenges and can synthesize construction plans for complex assemblies with thousands of parts in a matter of minutes. Our approach takes in a CAD-like product specification and automatically plans a full-stack assembly procedure for a group of robots to manufacture the product. We propose an algorithmic stack that comprises: (i) an iterative radial layout optimization procedure to define a global staging layout for the manufacturing facility, (ii) a graph-repair mixed-integer program formulation and a modified greedy task allocation algorithm to optimally allocate robots and robot sub-teams to assembly and transport tasks, (iii) a geometric heuristic and a hill-climbing algorithm to plan collaborative carrying configurations of robot sub-teams, and (iv) a distributed control policy that enables robots to execute the assembly motion plan collision-free. We also present an open-source multi-robot manufacturing simulator implemented in Julia as a resource to the research community, to test our algorithms and to facilitate multi-robot manufacturing research more broadly. Our empirical results demonstrate the scalability and effectiveness of our approach by generating plans to manufacture a LEGO model of a Saturn V launch vehicle with 1845 parts, 306 subassemblies, and 250 robots in under three minutes on a standard laptop computer.
Incorporating Human Path Preferences in Robot Navigation with Minimal Interventions
Mar 16, 2023


Robots that can effectively understand human intentions from actions are crucial for successful human-robot collaboration. In this work, we address the challenge of a robot navigating towards an unknown goal while also accounting for a human's preference for a particular path in the presence of obstacles. This problem is particularly challenging when both the goal and path preference are unknown a priori. To overcome this challenge, we propose a method for encoding and inferring path preference online using a partitioning of the space into polytopes. Our approach enables joint inference over the goal and path preference using a stochastic observation model for the human. We evaluate our method on an unknown-goal navigation problem with sparse human interventions, and find that it outperforms baseline approaches as the human's inputs become increasingly sparse. We find that the time required to update the robot's belief does not increase with the complexity of the environment, which makes our method suitable for online applications.
Collaborative Decision Making Using Action Suggestions
Sep 27, 2022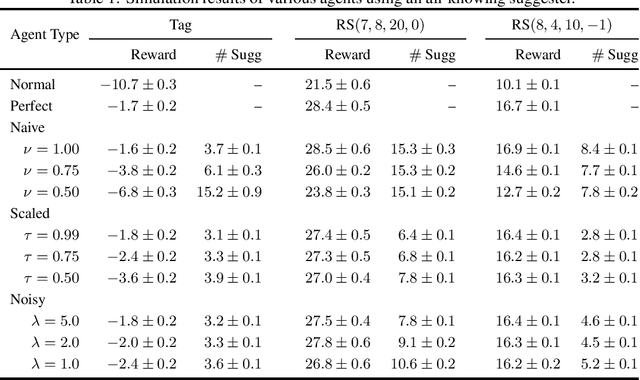
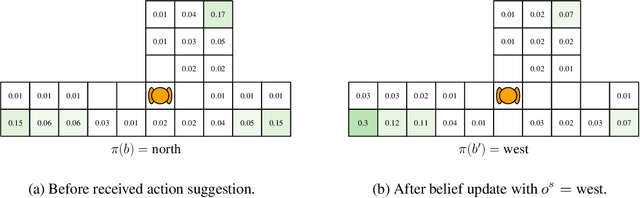
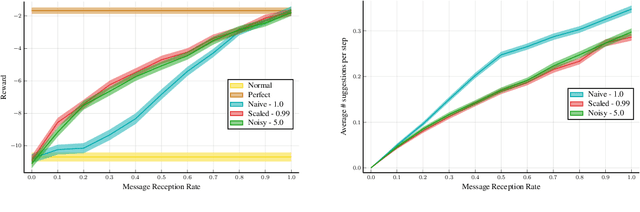
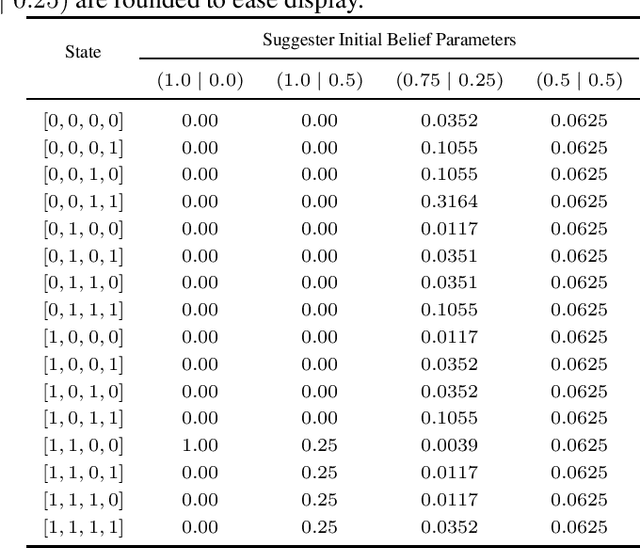
The level of autonomy is increasing in systems spanning multiple domains, but these systems still experience failures. One way to mitigate the risk of failures is to integrate human oversight of the autonomous systems and rely on the human to take control when the autonomy fails. In this work, we formulate a method of collaborative decision making through action suggestions that improves action selection without taking control of the system. Our approach uses each suggestion efficiently by incorporating the implicit information shared through suggestions to modify the agent's belief and achieves better performance with fewer suggestions than naively following the suggested actions. We assume collaborative agents share the same objective and communicate through valid actions. By assuming the suggested action is dependent only on the state, we can incorporate the suggested action as an independent observation of the environment. The assumption of a collaborative environment enables us to use the agent's policy to estimate the distribution over action suggestions. We propose two methods that use suggested actions and demonstrate the approach through simulated experiments. The proposed methodology results in increased performance while also being robust to suboptimal suggestions.
Model Predictive Optimized Path Integral Strategies
Mar 30, 2022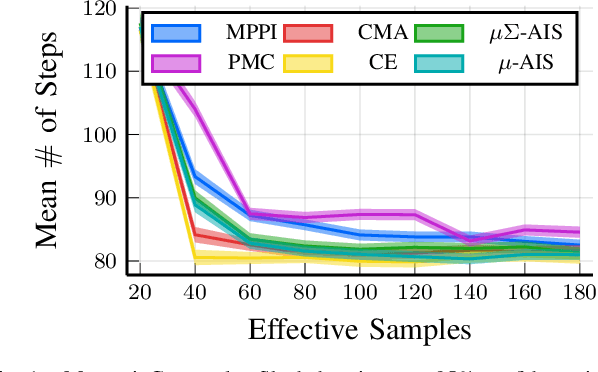
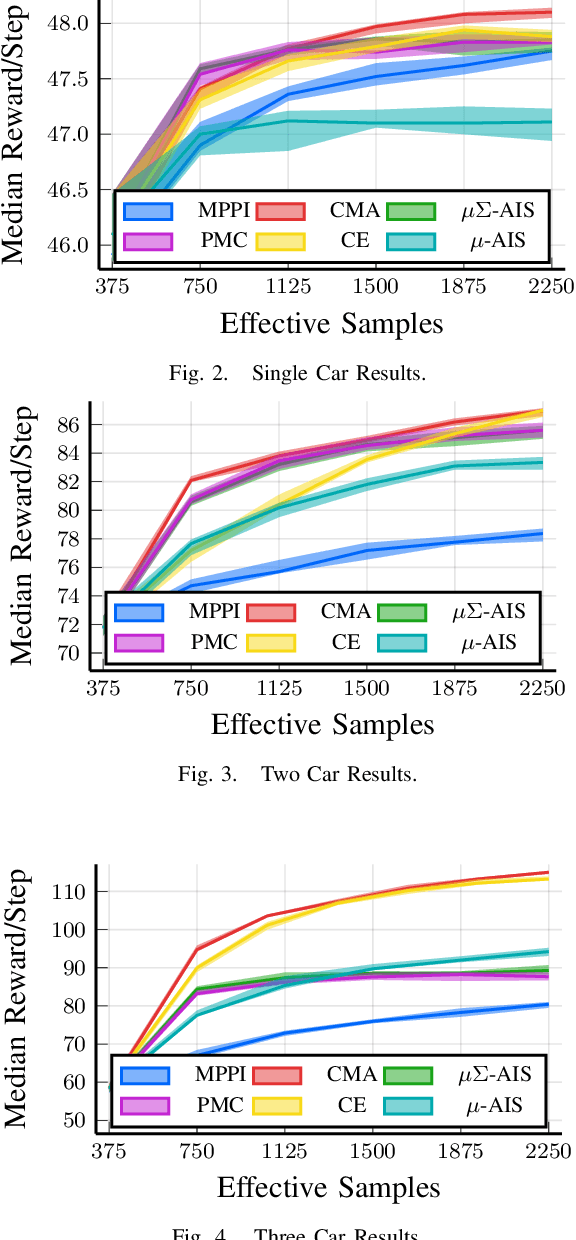
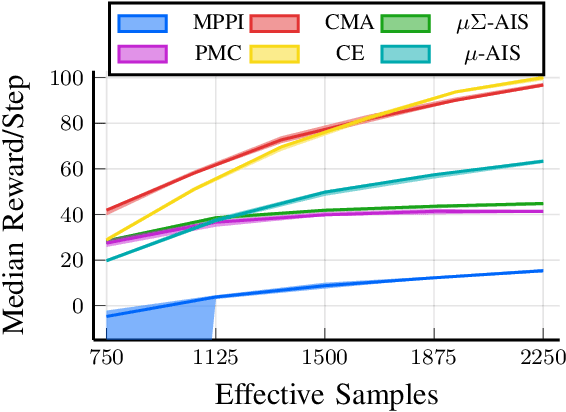
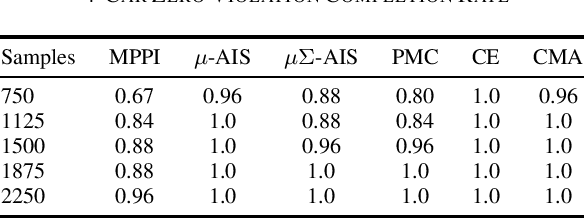
We generalize the derivation of model predictive path integral control (MPPI) to allow for a single joint distribution across controls in the control sequence. This reformation allows for the implementation of adaptive importance sampling (AIS) algorithms into the original importance sampling step while still maintaining the benefits of MPPI such as working with arbitrary system dynamics and cost functions. The benefit of optimizing the proposal distribution by integrating AIS at each control step is demonstrated in simulated environments including controlling multiple cars around a track. The new algorithm is more sample efficient than MPPI, achieving better performance with fewer samples. This performance disparity grows as the dimension of the action space increases. Results from simulations suggest the new algorithm can be used as an anytime algorithm, increasing the value of control at each iteration versus relying on a large set of samples.