 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Marketing? On the Information Value of AI Benchmarks for Practitioners
Dec 07, 2024Public AI benchmark results are widely broadcast by model developers as indicators of model quality within a growing and competitive market. However, these advertised scores do not necessarily reflect the traits of interest to those who will ultimately apply AI models. In this paper, we seek to understand if and how AI benchmarks are used to inform decision-making. Based on the analyses of interviews with 19 individuals who have used, or decided against using, benchmarks in their day-to-day work, we find that across these settings, participants use benchmarks as a signal of relative performance difference between models. However, whether this signal was considered a definitive sign of model superiority, sufficient for downstream decisions, varied. In academia, public benchmarks were generally viewed as suitable measures for capturing research progress. By contrast, in both product and policy, benchmarks -- even those developed internally for specific tasks -- were often found to be inadequate for informing substantive decisions. Of the benchmarks deemed unsatisfactory, respondents reported that their goals were neither well-defined nor reflective of real-world use. Based on the study results, we conclude that effective benchmarks should provide meaningful, real-world evaluations, incorporate domain expertise, and maintain transparency in scope and goals. They must capture diverse, task-relevant capabilities, be challenging enough to avoid quick saturation, and account for trade-offs in model performance rather than relying on a single score. Additionally, proprietary data collection and contamination prevention are critical for producing reliable and actionable results. By adhering to these criteria, benchmarks can move beyond mere marketing tricks into robust evaluative frameworks.
Text Classification Algorithms: A Survey
Apr 25, 2019
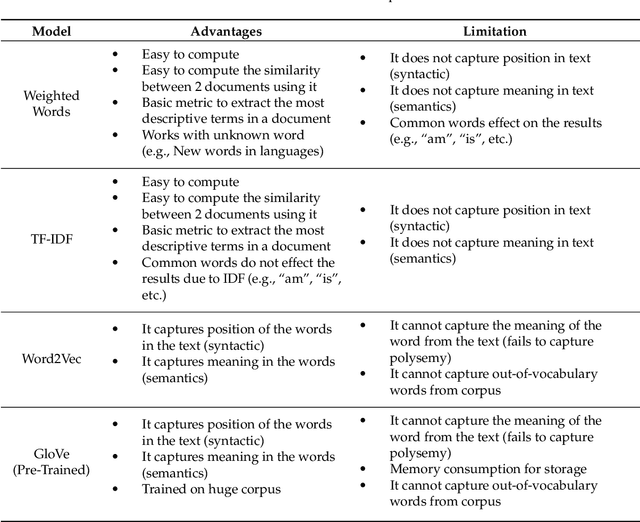
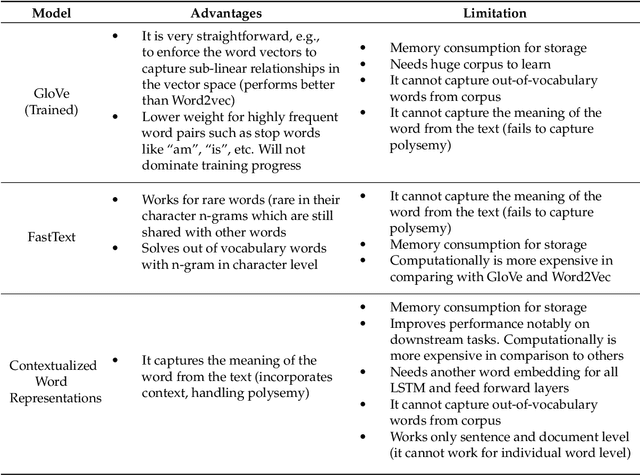
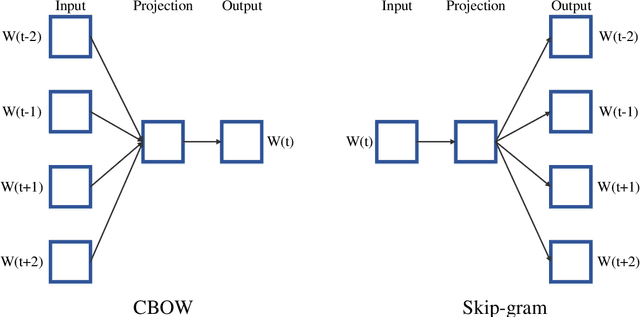
In recent years, there has been an exponential growth in the number of complex documents and texts that require a deeper understanding of machine learning methods to be able to accurately classify texts in many applications. Many machine learning approaches have achieved surpassing results in natural language processing. The success of these learning algorithms relies on their capacity to understand complex models and non-linear relationships within data. However, finding suitable structures, architectures, and techniques for text classification is a challenge for researchers. In this paper, a brief overview of text classification algorithms is discussed. This overview covers different text feature extractions, dimensionality reduction methods, existing algorithms and techniques, and evaluations methods. Finally, the limitations of each technique and their application in the real-world problem are discussed.
An Improvement of Data Classification Using Random Multimodel Deep Learning (RMDL)
Aug 23, 2018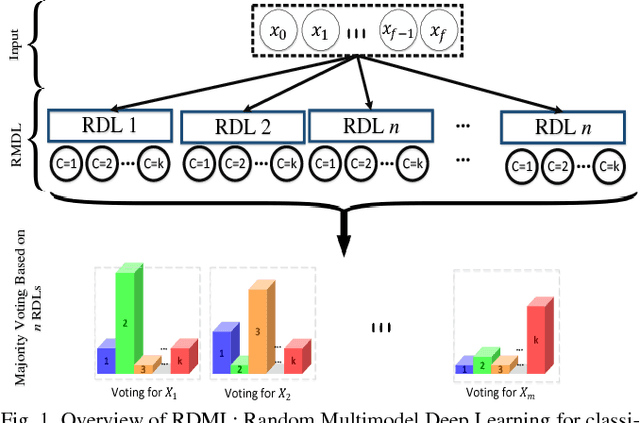
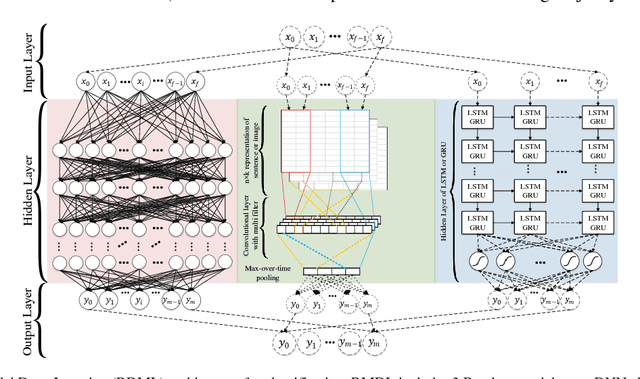
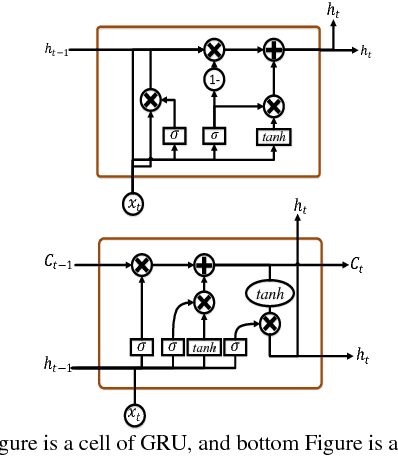

The exponential growth in the number of complex datasets every year requires more enhancement in machine learning methods to provide robust and accurate data classification. Lately, deep learning approaches have achieved surpassing results in comparison to previous machine learning algorithms. However, finding the suitable structure for these models has been a challenge for researchers. This paper introduces Random Multimodel Deep Learning (RMDL): a new ensemble, deep learning approach for classification. RMDL solves the problem of finding the best deep learning structure and architecture while simultaneously improving robustness and accuracy through ensembles of deep learning architectures. In short, RMDL trains multiple randomly generated models of Deep Neural Network (DNN), Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) in parallel and combines their results to produce better result of any of those models individually. In this paper, we describe RMDL model and compare the results for image and text classification as well as face recognition. We used MNIST and CIFAR-10 datasets as ground truth datasets for image classification and WOS, Reuters, IMDB, and 20newsgroup datasets for text classification. Lastly, we used ORL dataset to compare the model performance on face recognition task.
RMDL: Random Multimodel Deep Learning for Classification
May 31, 2018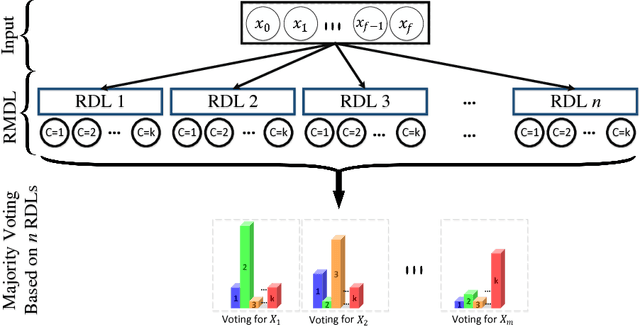
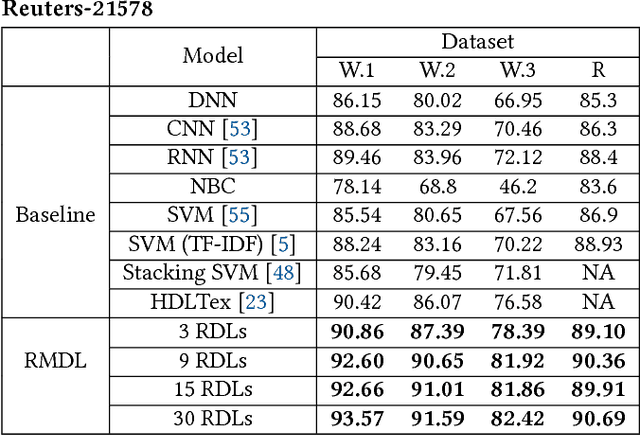

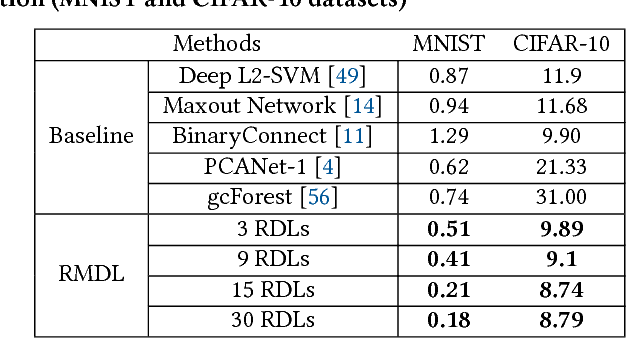
The continually increasing number of complex datasets each year necessitates ever improving machine learning methods for robust and accurate categorization of these data. This paper introduces Random Multimodel Deep Learning (RMDL): a new ensemble, deep learning approach for classification. Deep learning models have achieved state-of-the-art results across many domains. RMDL solves the problem of finding the best deep learning structure and architecture while simultaneously improving robustness and accuracy through ensembles of deep learning architectures. RDML can accept as input a variety data to include text, video, images, and symbolic. This paper describes RMDL and shows test results for image and text data including MNIST, CIFAR-10, WOS, Reuters, IMDB, and 20newsgroup. These test results show that RDML produces consistently better performance than standard methods over a broad range of data types and classification problems.
HDLTex: Hierarchical Deep Learning for Text Classification
Oct 06, 2017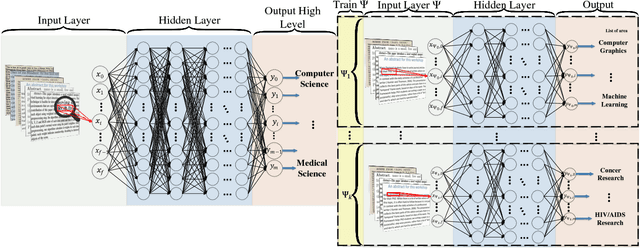
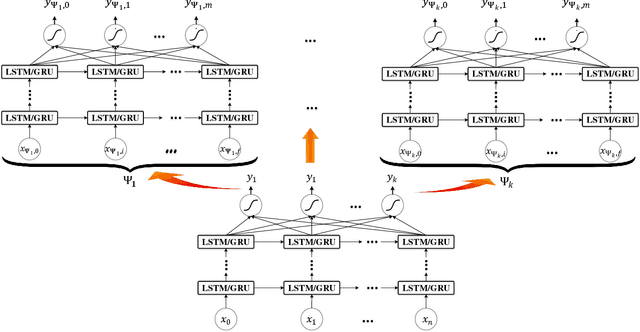
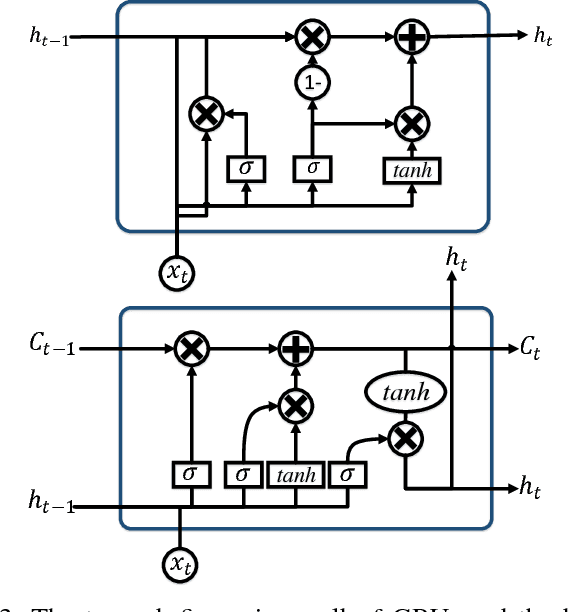
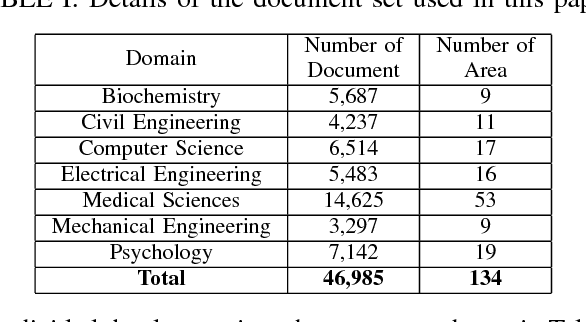
The continually increasing number of documents produced each year necessitates ever improving information processing methods for searching, retrieving, and organizing text. Central to these information processing methods is document classification, which has become an important application for supervised learning. Recently the performance of these traditional classifiers has degraded as the number of documents has increased. This is because along with this growth in the number of documents has come an increase in the number of categories. This paper approaches this problem differently from current document classification methods that view the problem as multi-class classification. Instead we perform hierarchical classification using an approach we call Hierarchical Deep Learning for Text classification (HDLTex). HDLTex employs stacks of deep learning architectures to provide specialized understanding at each level of the document hierarchy.