 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Spike Wave Discharges (SWD) using 1-dimensional Residual UNet
Jan 01, 2026The manual labeling of events in electroencephalography (EEG) records is time-consuming. This is especially true when EEG recordings are taken continuously over weeks to months. Therefore, a method to automatically label pertinent EEG events reduces the manual workload. Spike wave discharges (SWD), which are the electrographic hallmark of absence seizures, are EEG events that are often labeled manually. While some previous studies have utilized machine learning to automatically segment and classify EEG signals like SWDs, they can be improved. Here we compare the performance of 14 machine learning classifiers on our own manually annotated dataset of 961 hours of EEG recordings from C3H/HeJ mice, including 22,637 labeled SWDs. We find that a 1D UNet performs best for labeling SWDs in this dataset. We also improve the 1D UNet by augmenting our training data and determine that scaling showed the greatest benefit of all augmentation procedures applied. We then compare the 1D UNet with data augmentation, AugUNet1D, against a recently published time- and frequency-based algorithmic approach called "Twin Peaks". AugUNet1D showed superior performance and detected events with more similar features to the SWDs labeled manually. AugUNet1D, pretrained on our manually annotated data or untrained, is made public for others users.
Examining Vision Language Models through Multi-dimensional Experiments with Vision and Text Features
Sep 10, 2025Recent research on Vision Language Models (VLMs) suggests that they rely on inherent biases learned during training to respond to questions about visual properties of an image. These biases are exacerbated when VLMs are asked highly specific questions that require focusing on specific areas of the image. For example, a VLM tasked with counting stars on a modified American flag (e.g., with more than 50 stars) will often disregard the visual evidence and fail to answer accurately. We build upon this research and develop a multi-dimensional examination framework to systematically determine which characteristics of the input data, including both the image and the accompanying prompt, lead to such differences in performance. Using open-source VLMs, we further examine how attention values fluctuate with varying input parameters (e.g., image size, number of objects in the image, background color, prompt specificity). This research aims to learn how the behavior of vision language models changes and to explore methods for characterizing such changes. Our results suggest, among other things, that even minor modifications in image characteristics and prompt specificity can lead to large changes in how a VLM formulates its answer and, subsequently, its overall performance.
Towards Robust Multimodal Representation: A Unified Approach with Adaptive Experts and Alignment
Mar 12, 2025Healthcare relies on multiple types of data, such as medical images, genetic information, and clinical records, to improve diagnosis and treatment. However, missing data is a common challenge due to privacy restrictions, cost, and technical issues, making many existing multi-modal models unreliable. To address this, we propose a new multi-model model called Mixture of Experts, Symmetric Aligning, and Reconstruction (MoSARe), a deep learning framework that handles incomplete multimodal data while maintaining high accuracy. MoSARe integrates expert selection, cross-modal attention, and contrastive learning to improve feature representation and decision-making. Our results show that MoSARe outperforms existing models in situations when the data is complete. Furthermore, it provides reliable predictions even when some data are missing. This makes it especially useful in real-world healthcare settings, including resource-limited environments. Our code is publicly available at https://github.com/NazaninMn/MoSARe.
GenGMM: Generalized Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Oct 21, 2024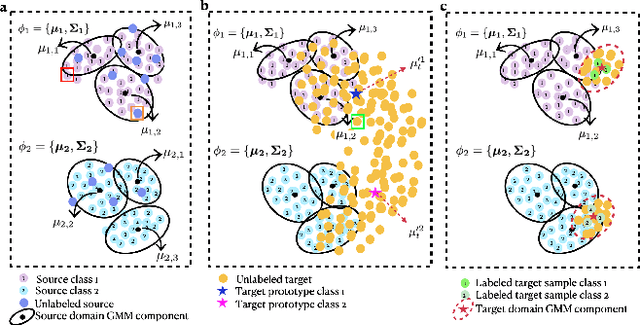


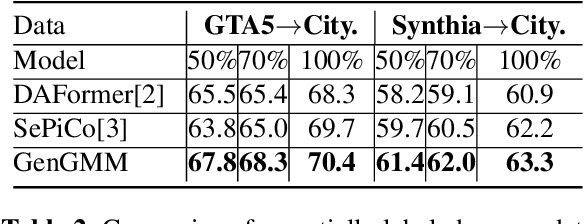
Domain adaptive semantic segmentation is the task of generating precise and dense predictions for an unlabeled target domain using a model trained on a labeled source domain. While significant efforts have been devoted to improving unsupervised domain adaptation for this task, it is crucial to note that many models rely on a strong assumption that the source data is entirely and accurately labeled, while the target data is unlabeled. In real-world scenarios, however, we often encounter partially or noisy labeled data in source and target domains, referred to as Generalized Domain Adaptation (GDA). In such cases, we suggest leveraging weak or unlabeled data from both domains to narrow the gap between them, resulting in effective adaptation. We introduce the Generalized Gaussian-mixture-based (GenGMM) domain adaptation model, which harnesses the underlying data distribution in both domains to refine noisy weak and pseudo labels. The experiments demonstrate the effectiveness of our approach.
ProtoGMM: Multi-prototype Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Jun 27, 2024



Domain adaptive semantic segmentation aims to generate accurate and dense predictions for an unlabeled target domain by leveraging a supervised model trained on a labeled source domain. The prevalent self-training approach involves retraining the dense discriminative classifier of $p(class|pixel feature)$ using the pseudo-labels from the target domain. While many methods focus on mitigating the issue of noisy pseudo-labels, they often overlook the underlying data distribution p(pixel feature|class) in both the source and target domains. To address this limitation, we propose the multi-prototype Gaussian-Mixture-based (ProtoGMM) model, which incorporates the GMM into contrastive losses to perform guided contrastive learning. Contrastive losses are commonly executed in the literature using memory banks, which can lead to class biases due to underrepresented classes. Furthermore, memory banks often have fixed capacities, potentially restricting the model's ability to capture diverse representations of the target/source domains. An alternative approach is to use global class prototypes (i.e. averaged features per category). However, the global prototypes are based on the unimodal distribution assumption per class, disregarding within-class variation. To address these challenges, we propose the ProtoGMM model. This novel approach involves estimating the underlying multi-prototype source distribution by utilizing the GMM on the feature space of the source samples. The components of the GMM model act as representative prototypes. To achieve increased intra-class semantic similarity, decreased inter-class similarity, and domain alignment between the source and target domains, we employ multi-prototype contrastive learning between source distribution and target samples. The experiments show the effectiveness of our method on UDA benchmarks.
Automatic Report Generation for Histopathology images using pre-trained Vision Transformers and BERT
Dec 03, 2023Deep learning for histopathology has been successfully used for disease classification, image segmentation and more. However, combining image and text modalities using current state-of-the-art methods has been a challenge due to the high resolution of histopathology images. Automatic report generation for histopathology images is one such challenge. In this work, we show that using an existing pre-trained Vision Transformer in a two-step process of first using it to encode 4096x4096 sized patches of the Whole Slide Image (WSI) and then using it as the encoder and a pre-trained Bidirectional Encoder Representations from Transformers (BERT) model for language modeling-based decoder for report generation, we can build a fairly performant and portable report generation mechanism that takes into account the whole of the high resolution image, instead of just the patches. Our method allows us to not only generate and evaluate captions that describe the image, but also helps us classify the image into tissue types and the gender of the patient as well. Our best performing model achieves a 79.98% accuracy in Tissue Type classification and 66.36% accuracy in classifying the sex of the patient the tissue came from, with a BLEU-4 score of 0.5818 in our caption generation task.
Automatic Report Generation for Histopathology images using pre-trained Vision Transformers
Nov 13, 2023



Deep learning for histopathology has been successfully used for disease classification, image segmentation and more. However, combining image and text modalities using current state-of-the-art methods has been a challenge due to the high resolution of histopathology images. Automatic report generation for histopathology images is one such challenge. In this work, we show that using an existing pre-trained Vision Transformer in a two-step process of first using it to encode 4096x4096 sized patches of the Whole Slide Image (WSI) and then using it as the encoder and an LSTM decoder for report generation, we can build a fairly performant and portable report generation mechanism that takes into account the whole of the high resolution image, instead of just the patches. We are also able to use representations from an existing powerful pre-trained hierarchical vision transformer and show its usefulness in not just zero shot classification but also for report generation.
Label-efficient Contrastive Learning-based model for nuclei detection and classification in 3D Cardiovascular Immunofluorescent Images
Sep 08, 2023



Recently, deep learning-based methods achieved promising performance in nuclei detection and classification applications. However, training deep learning-based methods requires a large amount of pixel-wise annotated data, which is time-consuming and labor-intensive, especially in 3D images. An alternative approach is to adapt weak-annotation methods, such as labeling each nucleus with a point, but this method does not extend from 2D histopathology images (for which it was originally developed) to 3D immunofluorescent images. The reason is that 3D images contain multiple channels (z-axis) for nuclei and different markers separately, which makes training using point annotations difficult. To address this challenge, we propose the Label-efficient Contrastive learning-based (LECL) model to detect and classify various types of nuclei in 3D immunofluorescent images. Previous methods use Maximum Intensity Projection (MIP) to convert immunofluorescent images with multiple slices to 2D images, which can cause signals from different z-stacks to falsely appear associated with each other. To overcome this, we devised an Extended Maximum Intensity Projection (EMIP) approach that addresses issues using MIP. Furthermore, we performed a Supervised Contrastive Learning (SCL) approach for weakly supervised settings. We conducted experiments on cardiovascular datasets and found that our proposed framework is effective and efficient in detecting and classifying various types of nuclei in 3D immunofluorescent images.
Analyzing historical diagnosis code data from NIH N3C and RECOVER Programs using deep learning to determine risk factors for Long Covid
Oct 05, 2022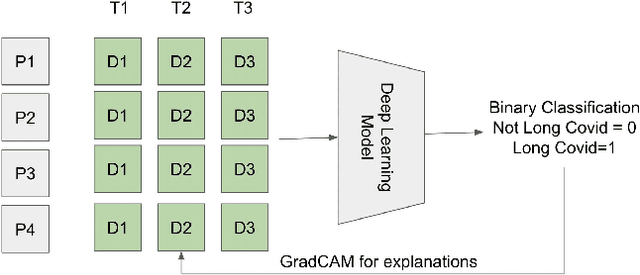
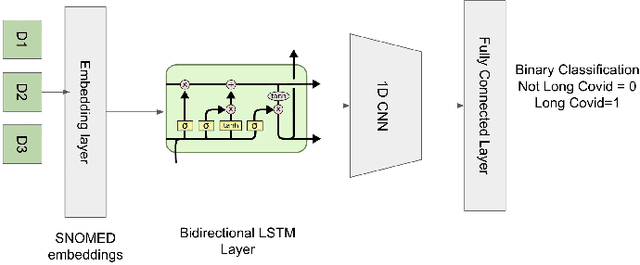


Post-acute sequelae of SARS-CoV-2 infection (PASC) or Long COVID is an emerging medical condition that has been observed in several patients with a positive diagnosis for COVID-19. Historical Electronic Health Records (EHR) like diagnosis codes, lab results and clinical notes have been analyzed using deep learning and have been used to predict future clinical events. In this paper, we propose an interpretable deep learning approach to analyze historical diagnosis code data from the National COVID Cohort Collective (N3C) to find the risk factors contributing to developing Long COVID. Using our deep learning approach, we are able to predict if a patient is suffering from Long COVID from a temporally ordered list of diagnosis codes up to 45 days post the first COVID positive test or diagnosis for each patient, with an accuracy of 70.48\%. We are then able to examine the trained model using Gradient-weighted Class Activation Mapping (GradCAM) to give each input diagnoses a score. The highest scored diagnosis were deemed to be the most important for making the correct prediction for a patient. We also propose a way to summarize these top diagnoses for each patient in our cohort and look at their temporal trends to determine which codes contribute towards a positive Long COVID diagnosis.
Weakly Supervised Deep Instance Nuclei Detection using Points Annotation in 3D Cardiovascular Immunofluorescent Images
Jul 29, 2022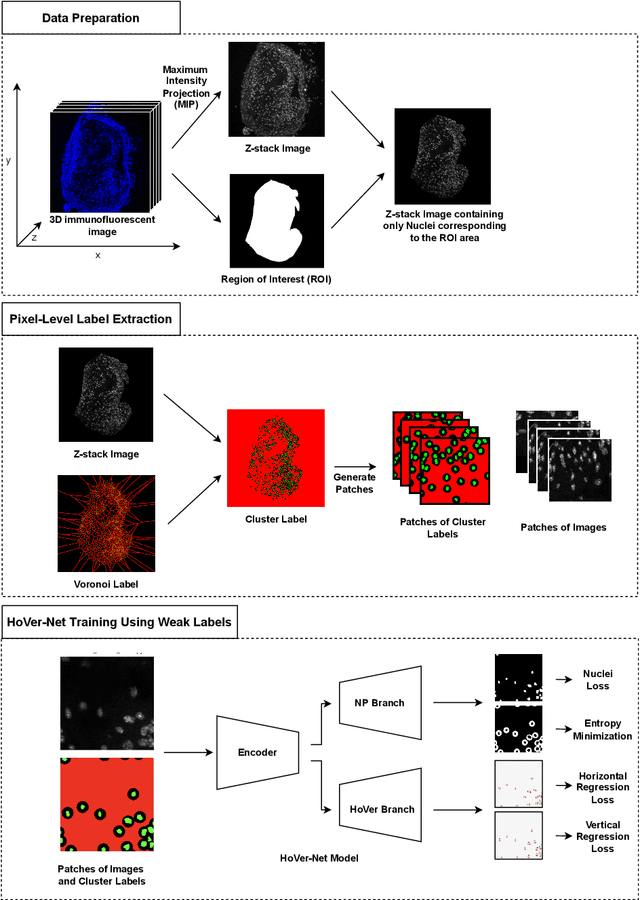


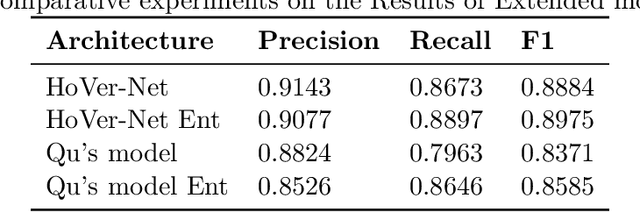
Two major causes of death in the United States and worldwide are stroke and myocardial infarction. The underlying cause of both is thrombi released from ruptured or eroded unstable atherosclerotic plaques that occlude vessels in the heart (myocardial infarction) or the brain (stroke). Clinical studies show that plaque composition plays a more important role than lesion size in plaque rupture or erosion events. To determine the plaque composition, various cell types in 3D cardiovascular immunofluorescent images of plaque lesions are counted. However, counting these cells manually is expensive, time-consuming, and prone to human error. These challenges of manual counting motivate the need for an automated approach to localize and count the cells in images. The purpose of this study is to develop an automatic approach to accurately detect and count cells in 3D immunofluorescent images with minimal annotation effort. In this study, we used a weakly supervised learning approach to train the HoVer-Net segmentation model using point annotations to detect nuclei in fluorescent images. The advantage of using point annotations is that they require less effort as opposed to pixel-wise annotation. To train the HoVer-Net model using point annotations, we adopted a popularly used cluster labeling approach to transform point annotations into accurate binary masks of cell nuclei. Traditionally, these approaches have generated binary masks from point annotations, leaving a region around the object unlabeled (which is typically ignored during model training). However, these areas may contain important information that helps determine the boundary between cells. Therefore, we used the entropy minimization loss function in these areas to encourage the model to output more confident predictions on the unlabeled areas. Our comparison studies indicate that the HoVer-Net model trained using our weakly ...