 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Spike Wave Discharges (SWD) using 1-dimensional Residual UNet
Jan 01, 2026The manual labeling of events in electroencephalography (EEG) records is time-consuming. This is especially true when EEG recordings are taken continuously over weeks to months. Therefore, a method to automatically label pertinent EEG events reduces the manual workload. Spike wave discharges (SWD), which are the electrographic hallmark of absence seizures, are EEG events that are often labeled manually. While some previous studies have utilized machine learning to automatically segment and classify EEG signals like SWDs, they can be improved. Here we compare the performance of 14 machine learning classifiers on our own manually annotated dataset of 961 hours of EEG recordings from C3H/HeJ mice, including 22,637 labeled SWDs. We find that a 1D UNet performs best for labeling SWDs in this dataset. We also improve the 1D UNet by augmenting our training data and determine that scaling showed the greatest benefit of all augmentation procedures applied. We then compare the 1D UNet with data augmentation, AugUNet1D, against a recently published time- and frequency-based algorithmic approach called "Twin Peaks". AugUNet1D showed superior performance and detected events with more similar features to the SWDs labeled manually. AugUNet1D, pretrained on our manually annotated data or untrained, is made public for others users.
Analyzing historical diagnosis code data from NIH N3C and RECOVER Programs using deep learning to determine risk factors for Long Covid
Oct 05, 2022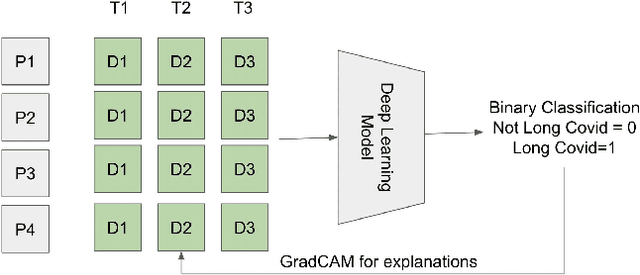
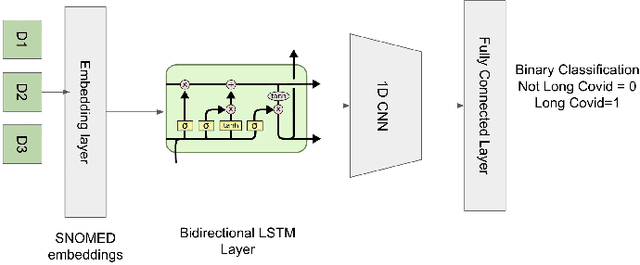


Post-acute sequelae of SARS-CoV-2 infection (PASC) or Long COVID is an emerging medical condition that has been observed in several patients with a positive diagnosis for COVID-19. Historical Electronic Health Records (EHR) like diagnosis codes, lab results and clinical notes have been analyzed using deep learning and have been used to predict future clinical events. In this paper, we propose an interpretable deep learning approach to analyze historical diagnosis code data from the National COVID Cohort Collective (N3C) to find the risk factors contributing to developing Long COVID. Using our deep learning approach, we are able to predict if a patient is suffering from Long COVID from a temporally ordered list of diagnosis codes up to 45 days post the first COVID positive test or diagnosis for each patient, with an accuracy of 70.48\%. We are then able to examine the trained model using Gradient-weighted Class Activation Mapping (GradCAM) to give each input diagnoses a score. The highest scored diagnosis were deemed to be the most important for making the correct prediction for a patient. We also propose a way to summarize these top diagnoses for each patient in our cohort and look at their temporal trends to determine which codes contribute towards a positive Long COVID diagnosis.