 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Multimodal Representation: A Unified Approach with Adaptive Experts and Alignment
Mar 12, 2025Healthcare relies on multiple types of data, such as medical images, genetic information, and clinical records, to improve diagnosis and treatment. However, missing data is a common challenge due to privacy restrictions, cost, and technical issues, making many existing multi-modal models unreliable. To address this, we propose a new multi-model model called Mixture of Experts, Symmetric Aligning, and Reconstruction (MoSARe), a deep learning framework that handles incomplete multimodal data while maintaining high accuracy. MoSARe integrates expert selection, cross-modal attention, and contrastive learning to improve feature representation and decision-making. Our results show that MoSARe outperforms existing models in situations when the data is complete. Furthermore, it provides reliable predictions even when some data are missing. This makes it especially useful in real-world healthcare settings, including resource-limited environments. Our code is publicly available at https://github.com/NazaninMn/MoSARe.
Diffusion and Multi-Domain Adaptation Methods for Eosinophil Segmentation
Mar 17, 2024Eosinophilic Esophagitis (EoE) represents a challenging condition for medical providers today. The cause is currently unknown, the impact on a patient's daily life is significant, and it is increasing in prevalence. Traditional approaches for medical image diagnosis such as standard deep learning algorithms are limited by the relatively small amount of data and difficulty in generalization. As a response, two methods have arisen that seem to perform well: Diffusion and Multi-Domain methods with current research efforts favoring diffusion methods. For the EoE dataset, we discovered that a Multi-Domain Adversarial Network outperformed a Diffusion based method with a FID of 42.56 compared to 50.65. Future work with diffusion methods should include a comparison with Multi-Domain adaptation methods to ensure that the best performance is achieved.
Uncertainty Quantification for Eosinophil Segmentation
Sep 28, 2023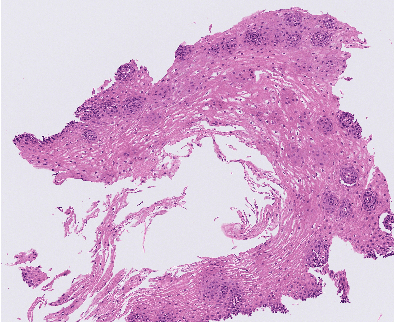
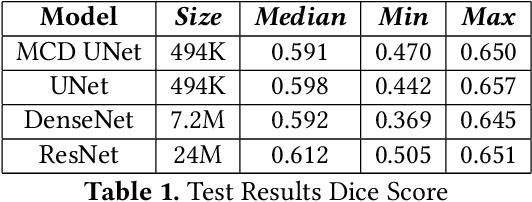
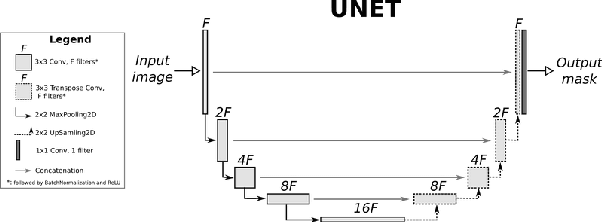
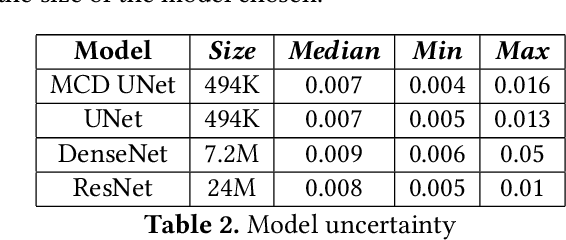
Eosinophilic Esophagitis (EoE) is an allergic condition increasing in prevalence. To diagnose EoE, pathologists must find 15 or more eosinophils within a single high-power field (400X magnification). Determining whether or not a patient has EoE can be an arduous process and any medical imaging approaches used to assist diagnosis must consider both efficiency and precision. We propose an improvement of Adorno et al's approach for quantifying eosinphils using deep image segmentation. Our new approach leverages Monte Carlo Dropout, a common approach in deep learning to reduce overfitting, to provide uncertainty quantification on current deep learning models. The uncertainty can be visualized in an output image to evaluate model performance, provide insight to how deep learning algorithms function, and assist pathologists in identifying eosinophils.
The intersection of video capsule endoscopy and artificial intelligence: addressing unique challenges using machine learning
Aug 24, 2023



Introduction: Technical burdens and time-intensive review processes limit the practical utility of video capsule endoscopy (VCE). Artificial intelligence (AI) is poised to address these limitations, but the intersection of AI and VCE reveals challenges that must first be overcome. We identified five challenges to address. Challenge #1: VCE data are stochastic and contains significant artifact. Challenge #2: VCE interpretation is cost-intensive. Challenge #3: VCE data are inherently imbalanced. Challenge #4: Existing VCE AIMLT are computationally cumbersome. Challenge #5: Clinicians are hesitant to accept AIMLT that cannot explain their process. Methods: An anatomic landmark detection model was used to test the application of convolutional neural networks (CNNs) to the task of classifying VCE data. We also created a tool that assists in expert annotation of VCE data. We then created more elaborate models using different approaches including a multi-frame approach, a CNN based on graph representation, and a few-shot approach based on meta-learning. Results: When used on full-length VCE footage, CNNs accurately identified anatomic landmarks (99.1%), with gradient weighted-class activation mapping showing the parts of each frame that the CNN used to make its decision. The graph CNN with weakly supervised learning (accuracy 89.9%, sensitivity of 91.1%), the few-shot model (accuracy 90.8%, precision 91.4%, sensitivity 90.9%), and the multi-frame model (accuracy 97.5%, precision 91.5%, sensitivity 94.8%) performed well. Discussion: Each of these five challenges is addressed, in part, by one of our AI-based models. Our goal of producing high performance using lightweight models that aim to improve clinician confidence was achieved.
MaNi: Maximizing Mutual Information for Nuclei Cross-Domain Unsupervised Segmentation
Jun 29, 2022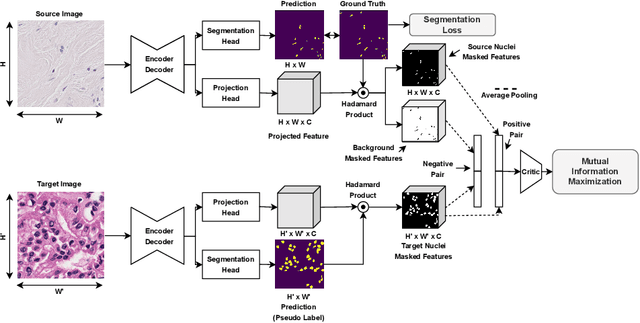
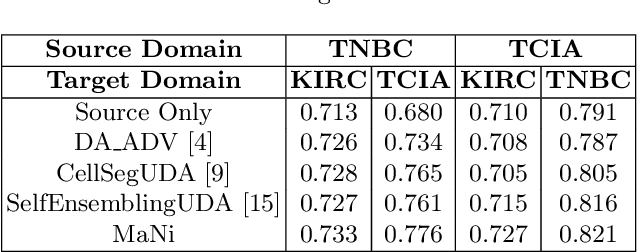
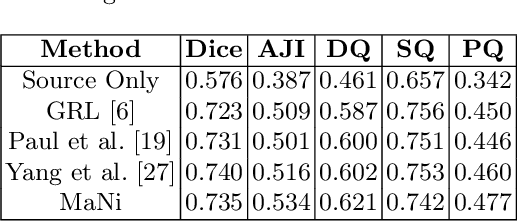
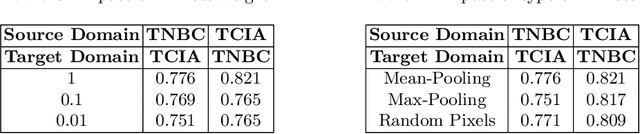
In this work, we propose a mutual information (MI) based unsupervised domain adaptation (UDA) method for the cross-domain nuclei segmentation. Nuclei vary substantially in structure and appearances across different cancer types, leading to a drop in performance of deep learning models when trained on one cancer type and tested on another. This domain shift becomes even more critical as accurate segmentation and quantification of nuclei is an essential histopathology task for the diagnosis/ prognosis of patients and annotating nuclei at the pixel level for new cancer types demands extensive effort by medical experts. To address this problem, we maximize the MI between labeled source cancer type data and unlabeled target cancer type data for transferring nuclei segmentation knowledge across domains. We use the Jensen-Shanon divergence bound, requiring only one negative pair per positive pair for MI maximization. We evaluate our set-up for multiple modeling frameworks and on different datasets comprising of over 20 cancer-type domain shifts and demonstrate competitive performance. All the recently proposed approaches consist of multiple components for improving the domain adaptation, whereas our proposed module is light and can be easily incorporated into other methods (Implementation: https://github.com/YashSharma/MaNi ).
Graph Convolution Neural Network For Weakly Supervised Abnormality Localization In Long Capsule Endoscopy Videos
Oct 18, 2021
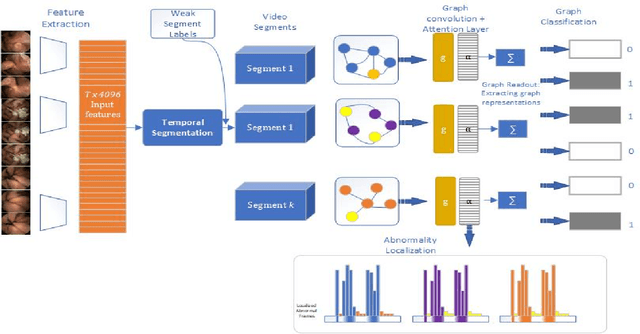
Temporal activity localization in long videos is an important problem. The cost of obtaining frame level label for long Wireless Capsule Endoscopy (WCE) videos is prohibitive. In this paper, we propose an end-to-end temporal abnormality localization for long WCE videos using only weak video level labels. Physicians use Capsule Endoscopy (CE) as a non-surgical and non-invasive method to examine the entire digestive tract in order to diagnose diseases or abnormalities. While CE has revolutionized traditional endoscopy procedures, a single CE examination could last up to 8 hours generating as much as 100,000 frames. Physicians must review the entire video, frame-by-frame, in order to identify the frames capturing relevant abnormality. This, sometimes could be as few as just a single frame. Given this very high level of redundancy, analyzing long CE videos can be very tedious, time consuming and also error prone. This paper presents a novel multi-step method for an end-to-end localization of target frames capturing abnormalities of interest in the long video using only weak video labels. First we developed an automatic temporal segmentation using change point detection technique to temporally segment the video into uniform, homogeneous and identifiable segments. Then we employed Graph Convolutional Neural Network (GCNN) to learn a representation of each video segment. Using weak video segment labels, we trained our GCNN model to recognize each video segment as abnormal if it contains at least a single abnormal frame. Finally, leveraging the parameters of the trained GCNN model, we replaced the final layer of the network with a temporal pool layer to localize the relevant abnormal frames within each abnormal video segment. Our method achieved an accuracy of 89.9\% on the graph classification task and a specificity of 97.5\% on the abnormal frames localization task.
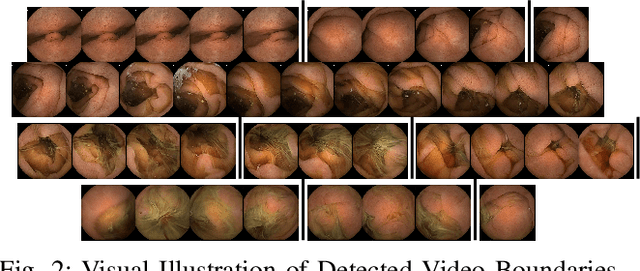
Unsupervised Shot Boundary Detection for Temporal Segmentation of Long Capsule Endoscopy Videos
Oct 18, 2021



Physicians use Capsule Endoscopy (CE) as a non-invasive and non-surgical procedure to examine the entire gastrointestinal (GI) tract for diseases and abnormalities. A single CE examination could last between 8 to 11 hours generating up to 80,000 frames which is compiled as a video. Physicians have to review and analyze the entire video to identify abnormalities or diseases before making diagnosis. This review task can be very tedious, time consuming and prone to error. While only as little as a single frame may capture useful content that is relevant to the physicians' final diagnosis, frames covering the small bowel region alone could be as much as 50,000. To minimize physicians' review time and effort, this paper proposes a novel unsupervised and computationally efficient temporal segmentation method to automatically partition long CE videos into a homogeneous and identifiable video segments. However, the search for temporal boundaries in a long video using high dimensional frame-feature matrix is computationally prohibitive and impracticable for real clinical application. Therefore, leveraging both spatial and temporal information in the video, we first extracted high level frame features using a pretrained CNN model and then projected the high-dimensional frame-feature matrix to lower 1-dimensional embedding. Using this 1-dimensional sequence embedding, we applied the Pruned Exact Linear Time (PELT) algorithm to searched for temporal boundaries that indicates the transition points from normal to abnormal frames and vice-versa. We experimented with multiple real patients' CE videos and our model achieved an AUC of 66\% on multiple test videos against expert provided labels.
HistoTransfer: Understanding Transfer Learning for Histopathology
Jun 13, 2021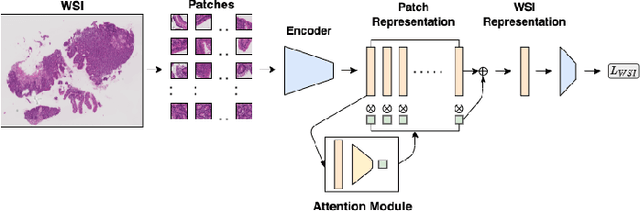
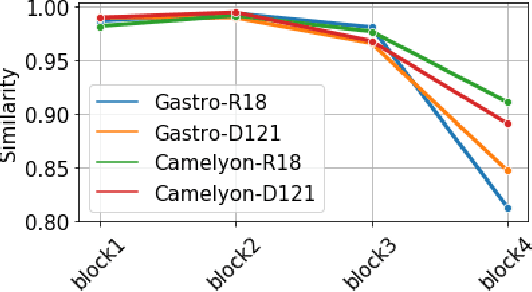
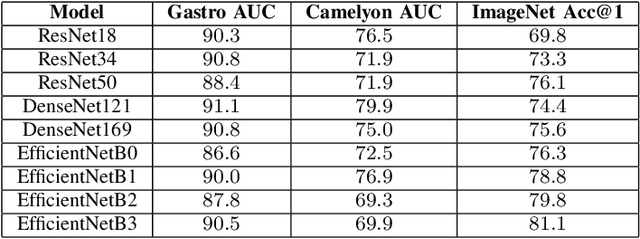

Advancement in digital pathology and artificial intelligence has enabled deep learning-based computer vision techniques for automated disease diagnosis and prognosis. However, WSIs present unique computational and algorithmic challenges. WSIs are gigapixel-sized, making them infeasible to be used directly for training deep neural networks. Hence, for modeling, a two-stage approach is adopted: Patch representations are extracted first, followed by the aggregation for WSI prediction. These approaches require detailed pixel-level annotations for training the patch encoder. However, obtaining these annotations is time-consuming and tedious for medical experts. Transfer learning is used to address this gap and deep learning architectures pre-trained on ImageNet are used for generating patch-level representation. Even though ImageNet differs significantly from histopathology data, pre-trained networks have been shown to perform impressively on histopathology data. Also, progress in self-supervised and multi-task learning coupled with the release of multiple histopathology data has led to the release of histopathology-specific networks. In this work, we compare the performance of features extracted from networks trained on ImageNet and histopathology data. We use an attention pooling network over these extracted features for slide-level aggregation. We investigate if features learned using more complex networks lead to gain in performance. We use a simple top-k sampling approach for fine-tuning framework and study the representation similarity between frozen and fine-tuned networks using Centered Kernel Alignment. Further, to examine if intermediate block representation is better suited for feature extraction and ImageNet architectures are unnecessarily large for histopathology, we truncate the blocks of ResNet18 and DenseNet121 and examine the performance.
Cluster-to-Conquer: A Framework for End-to-End Multi-Instance Learning for Whole Slide Image Classification
Mar 19, 2021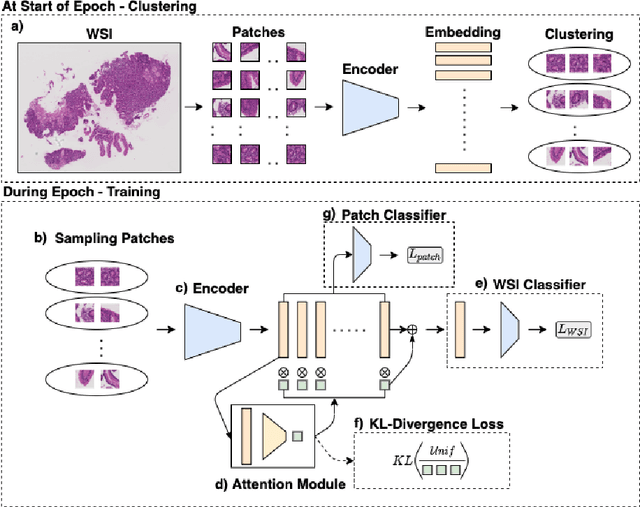
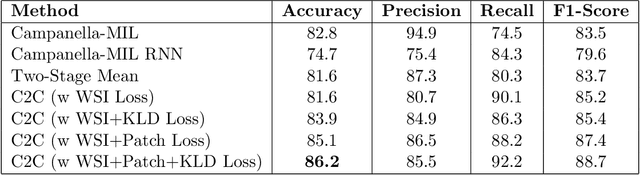
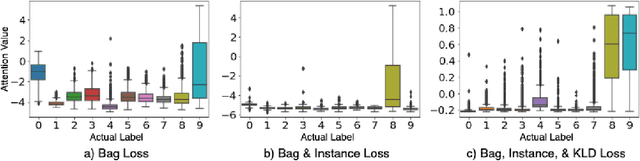

In recent years, the availability of digitized Whole Slide Images (WSIs) has enabled the use of deep learning-based computer vision techniques for automated disease diagnosis. However, WSIs present unique computational and algorithmic challenges. WSIs are gigapixel-sized ($\sim$100K pixels), making them infeasible to be used directly for training deep neural networks. Also, often only slide-level labels are available for training as detailed annotations are tedious and can be time-consuming for experts. Approaches using multiple-instance learning (MIL) frameworks have been shown to overcome these challenges. Current state-of-the-art approaches divide the learning framework into two decoupled parts: a convolutional neural network (CNN) for encoding the patches followed by an independent aggregation approach for slide-level prediction. In this approach, the aggregation step has no bearing on the representations learned by the CNN encoder. We have proposed an end-to-end framework that clusters the patches from a WSI into ${k}$-groups, samples ${k}'$ patches from each group for training, and uses an adaptive attention mechanism for slide level prediction; Cluster-to-Conquer (C2C). We have demonstrated that dividing a WSI into clusters can improve the model training by exposing it to diverse discriminative features extracted from the patches. We regularized the clustering mechanism by introducing a KL-divergence loss between the attention weights of patches in a cluster and the uniform distribution. The framework is optimized end-to-end on slide-level cross-entropy, patch-level cross-entropy, and KL-divergence loss (Implementation: https://github.com/YashSharma/C2C).
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021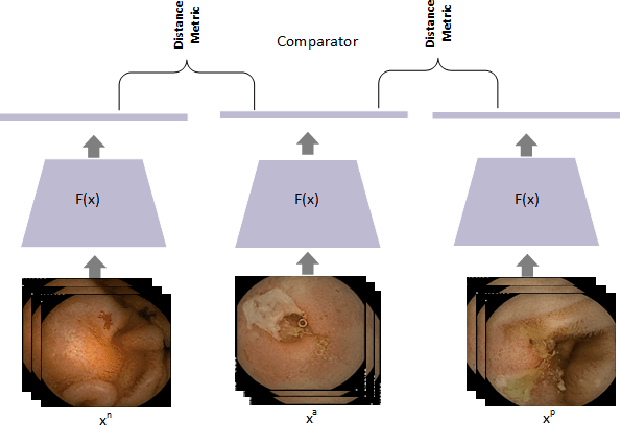
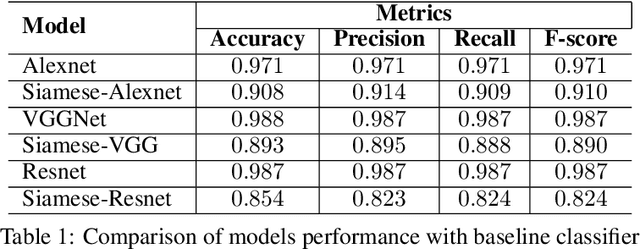
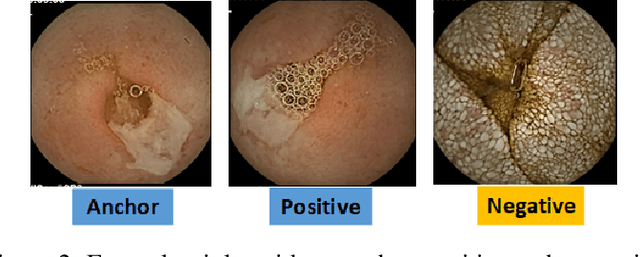
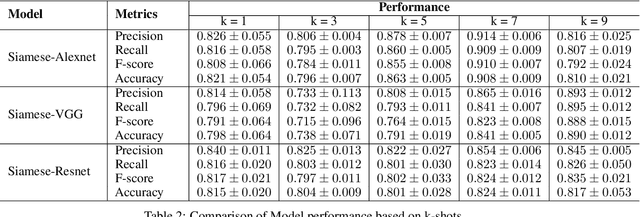
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.