 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChest Disease Detection In X-Ray Images Using Deep Learning Classification Method
May 28, 2025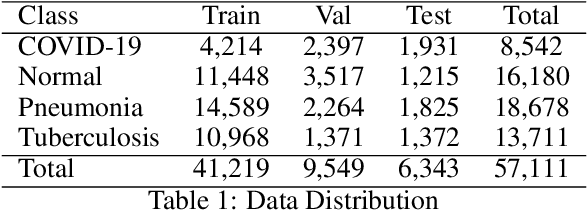
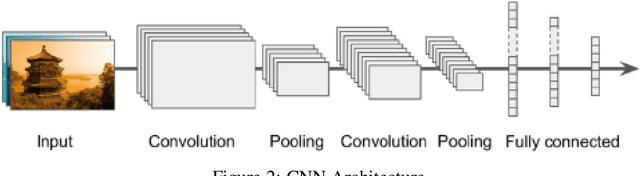

In this work, we investigate the performance across multiple classification models to classify chest X-ray images into four categories of COVID-19, pneumonia, tuberculosis (TB), and normal cases. We leveraged transfer learning techniques with state-of-the-art pre-trained Convolutional Neural Networks (CNNs) models. We fine-tuned these pre-trained architectures on a labeled medical x-ray images. The initial results are promising with high accuracy and strong performance in key classification metrics such as precision, recall, and F1 score. We applied Gradient-weighted Class Activation Mapping (Grad-CAM) for model interpretability to provide visual explanations for classification decisions, improving trust and transparency in clinical applications.
Words of War: Exploring the Presidential Rhetorical Arsenal with Deep Learning
Dec 12, 2024In political discourse and geopolitical analysis, national leaders words hold profound significance, often serving as harbingers of pivotal historical moments. From impassioned rallying cries to calls for caution, presidential speeches preceding major conflicts encapsulate the multifaceted dynamics of decision-making at the apex of governance. This project aims to use deep learning techniques to decode the subtle nuances and underlying patterns of US presidential rhetoric that may signal US involvement in major wars. While accurate classification is desirable, we seek to take a step further and identify discriminative features between the two classes (i.e. interpretable learning). Through an interdisciplinary fusion of machine learning and historical inquiry, we aspire to unearth insights into the predictive capacity of neural networks in discerning the preparatory rhetoric of US presidents preceding war. Indeed, as the venerable Prussian General and military theorist Carl von Clausewitz admonishes, War is not merely an act of policy but a true political instrument, a continuation of political intercourse carried on with other means (Clausewitz, 1832).
The intersection of video capsule endoscopy and artificial intelligence: addressing unique challenges using machine learning
Aug 24, 2023



Introduction: Technical burdens and time-intensive review processes limit the practical utility of video capsule endoscopy (VCE). Artificial intelligence (AI) is poised to address these limitations, but the intersection of AI and VCE reveals challenges that must first be overcome. We identified five challenges to address. Challenge #1: VCE data are stochastic and contains significant artifact. Challenge #2: VCE interpretation is cost-intensive. Challenge #3: VCE data are inherently imbalanced. Challenge #4: Existing VCE AIMLT are computationally cumbersome. Challenge #5: Clinicians are hesitant to accept AIMLT that cannot explain their process. Methods: An anatomic landmark detection model was used to test the application of convolutional neural networks (CNNs) to the task of classifying VCE data. We also created a tool that assists in expert annotation of VCE data. We then created more elaborate models using different approaches including a multi-frame approach, a CNN based on graph representation, and a few-shot approach based on meta-learning. Results: When used on full-length VCE footage, CNNs accurately identified anatomic landmarks (99.1%), with gradient weighted-class activation mapping showing the parts of each frame that the CNN used to make its decision. The graph CNN with weakly supervised learning (accuracy 89.9%, sensitivity of 91.1%), the few-shot model (accuracy 90.8%, precision 91.4%, sensitivity 90.9%), and the multi-frame model (accuracy 97.5%, precision 91.5%, sensitivity 94.8%) performed well. Discussion: Each of these five challenges is addressed, in part, by one of our AI-based models. Our goal of producing high performance using lightweight models that aim to improve clinician confidence was achieved.
Distributed Conditional GAN (discGAN) For Synthetic Healthcare Data Generation
Apr 09, 2023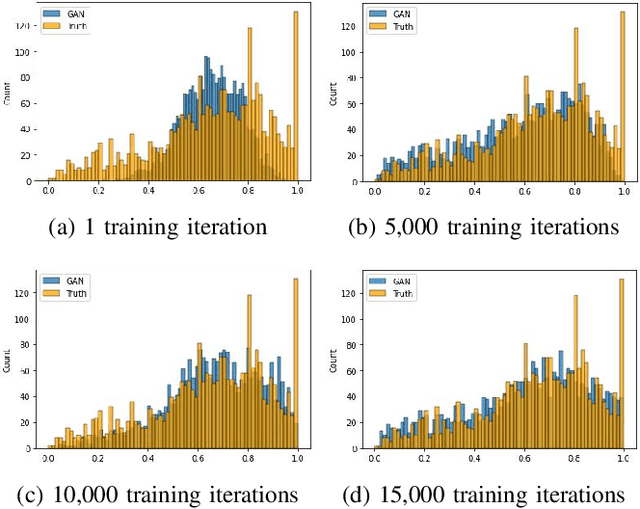
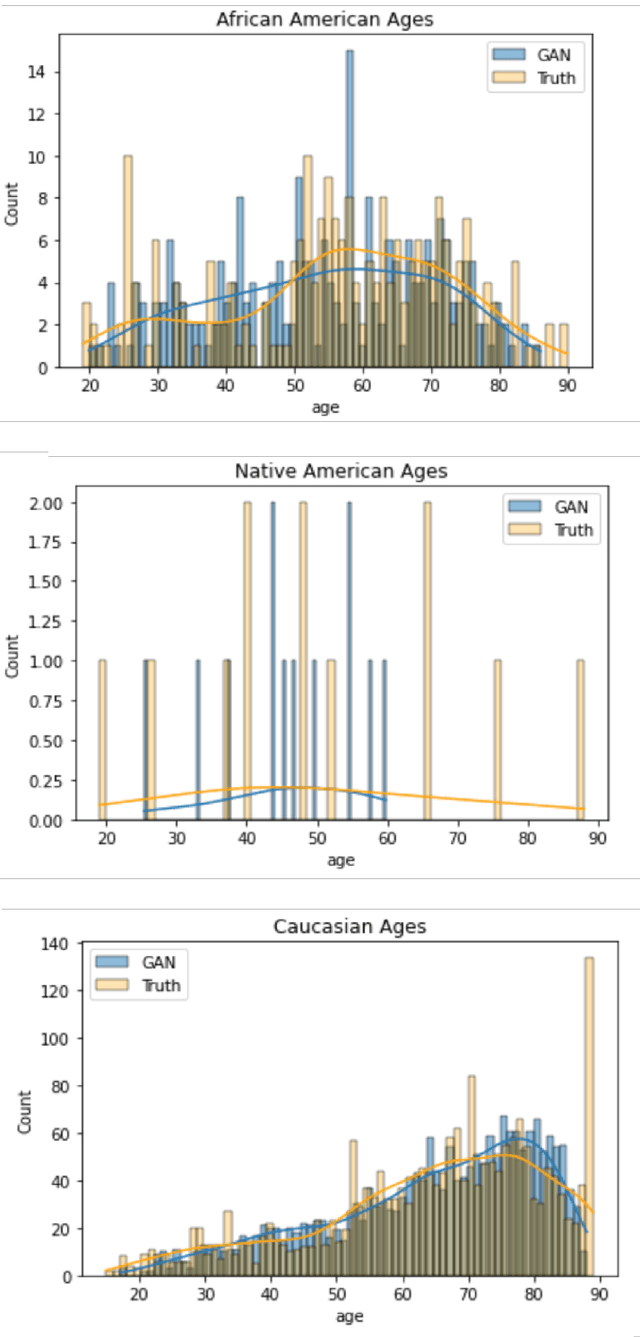
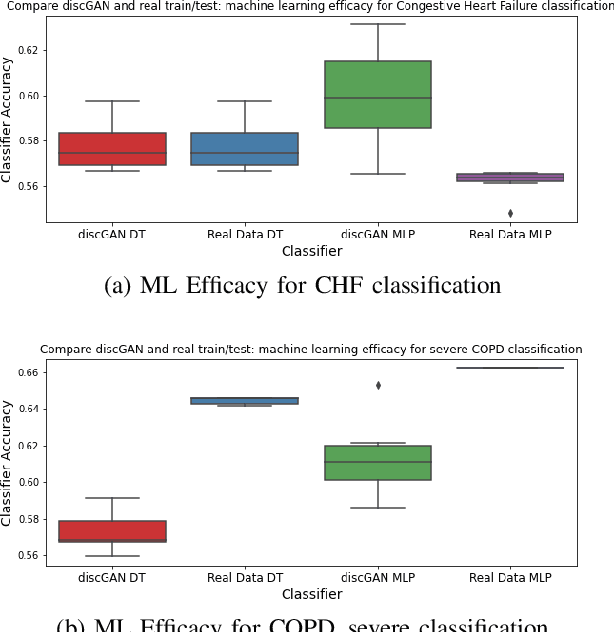
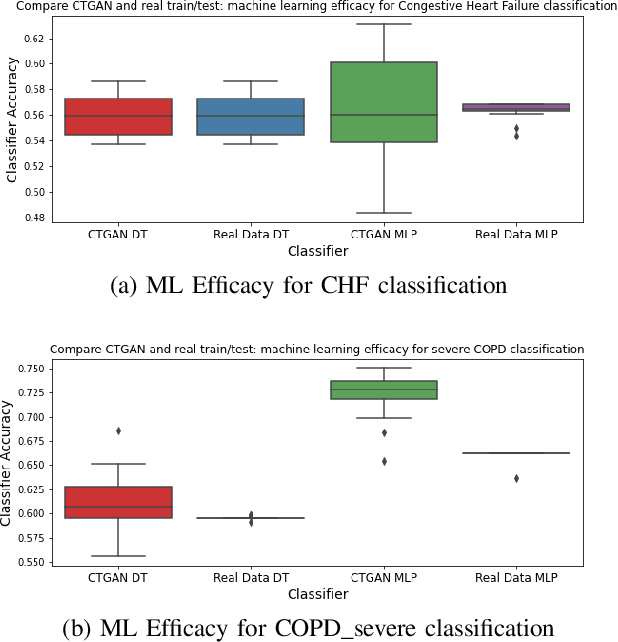
In this paper, we propose a distributed Generative Adversarial Networks (discGANs) to generate synthetic tabular data specific to the healthcare domain. While using GANs to generate images has been well studied, little to no attention has been given to generation of tabular data. Modeling distributions of discrete and continuous tabular data is a non-trivial task with high utility. We applied discGAN to model non-Gaussian multi-modal healthcare data. We generated 249,000 synthetic records from original 2,027 eICU dataset. We evaluated the performance of the model using machine learning efficacy, the Kolmogorov-Smirnov (KS) test for continuous variables and chi-squared test for discrete variables. Our results show that discGAN was able to generate data with distributions similar to the real data.
Graph Convolution Neural Network For Weakly Supervised Abnormality Localization In Long Capsule Endoscopy Videos
Oct 18, 2021
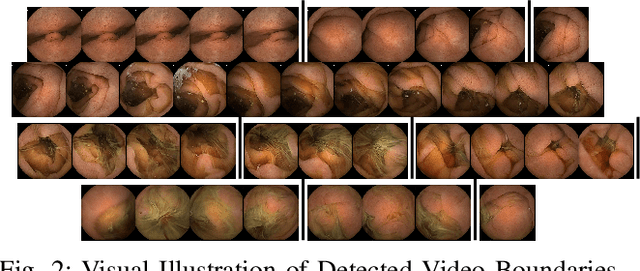
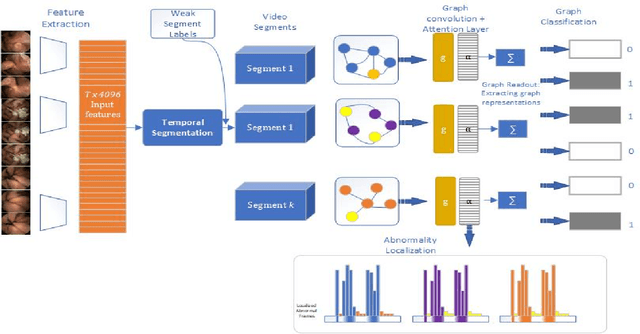
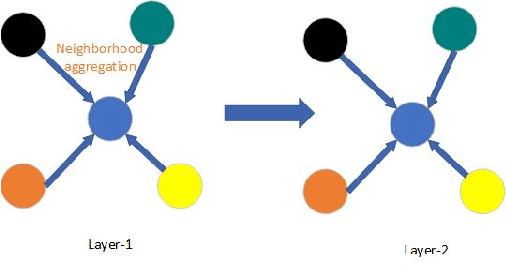
Temporal activity localization in long videos is an important problem. The cost of obtaining frame level label for long Wireless Capsule Endoscopy (WCE) videos is prohibitive. In this paper, we propose an end-to-end temporal abnormality localization for long WCE videos using only weak video level labels. Physicians use Capsule Endoscopy (CE) as a non-surgical and non-invasive method to examine the entire digestive tract in order to diagnose diseases or abnormalities. While CE has revolutionized traditional endoscopy procedures, a single CE examination could last up to 8 hours generating as much as 100,000 frames. Physicians must review the entire video, frame-by-frame, in order to identify the frames capturing relevant abnormality. This, sometimes could be as few as just a single frame. Given this very high level of redundancy, analyzing long CE videos can be very tedious, time consuming and also error prone. This paper presents a novel multi-step method for an end-to-end localization of target frames capturing abnormalities of interest in the long video using only weak video labels. First we developed an automatic temporal segmentation using change point detection technique to temporally segment the video into uniform, homogeneous and identifiable segments. Then we employed Graph Convolutional Neural Network (GCNN) to learn a representation of each video segment. Using weak video segment labels, we trained our GCNN model to recognize each video segment as abnormal if it contains at least a single abnormal frame. Finally, leveraging the parameters of the trained GCNN model, we replaced the final layer of the network with a temporal pool layer to localize the relevant abnormal frames within each abnormal video segment. Our method achieved an accuracy of 89.9\% on the graph classification task and a specificity of 97.5\% on the abnormal frames localization task.
Unsupervised Shot Boundary Detection for Temporal Segmentation of Long Capsule Endoscopy Videos
Oct 18, 2021



Physicians use Capsule Endoscopy (CE) as a non-invasive and non-surgical procedure to examine the entire gastrointestinal (GI) tract for diseases and abnormalities. A single CE examination could last between 8 to 11 hours generating up to 80,000 frames which is compiled as a video. Physicians have to review and analyze the entire video to identify abnormalities or diseases before making diagnosis. This review task can be very tedious, time consuming and prone to error. While only as little as a single frame may capture useful content that is relevant to the physicians' final diagnosis, frames covering the small bowel region alone could be as much as 50,000. To minimize physicians' review time and effort, this paper proposes a novel unsupervised and computationally efficient temporal segmentation method to automatically partition long CE videos into a homogeneous and identifiable video segments. However, the search for temporal boundaries in a long video using high dimensional frame-feature matrix is computationally prohibitive and impracticable for real clinical application. Therefore, leveraging both spatial and temporal information in the video, we first extracted high level frame features using a pretrained CNN model and then projected the high-dimensional frame-feature matrix to lower 1-dimensional embedding. Using this 1-dimensional sequence embedding, we applied the Pruned Exact Linear Time (PELT) algorithm to searched for temporal boundaries that indicates the transition points from normal to abnormal frames and vice-versa. We experimented with multiple real patients' CE videos and our model achieved an AUC of 66\% on multiple test videos against expert provided labels.
Feature Selection Using Reinforcement Learning
Jan 23, 2021


With the decreasing cost of data collection, the space of variables or features that can be used to characterize a particular predictor of interest continues to grow exponentially. Therefore, identifying the most characterizing features that minimizes the variance without jeopardizing the bias of our models is critical to successfully training a machine learning model. In addition, identifying such features is critical for interpretability, prediction accuracy and optimal computation cost. While statistical methods such as subset selection, shrinkage, dimensionality reduction have been applied in selecting the best set of features, some other approaches in literature have approached feature selection task as a search problem where each state in the search space is a possible feature subset. In this paper, we solved the feature selection problem using Reinforcement Learning. Formulating the state space as a Markov Decision Process (MDP), we used Temporal Difference (TD) algorithm to select the best subset of features. Each state was evaluated using a robust and low cost classifier algorithm which could handle any non-linearities in the dataset.
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021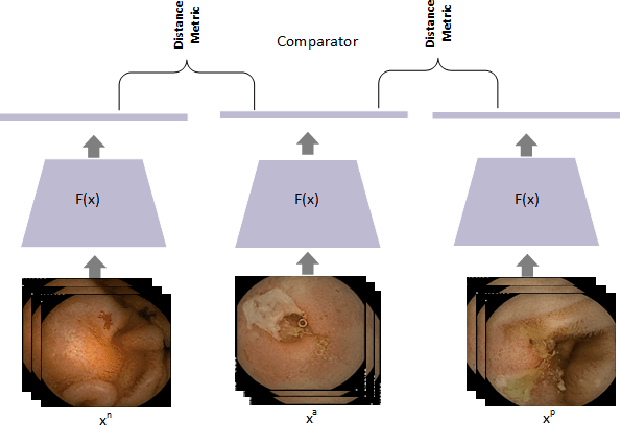
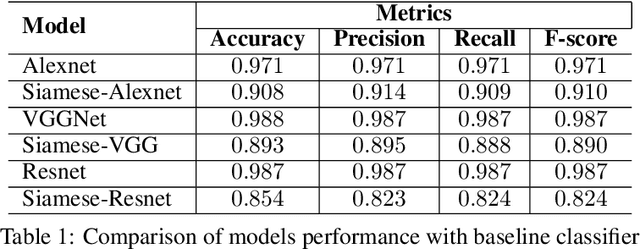
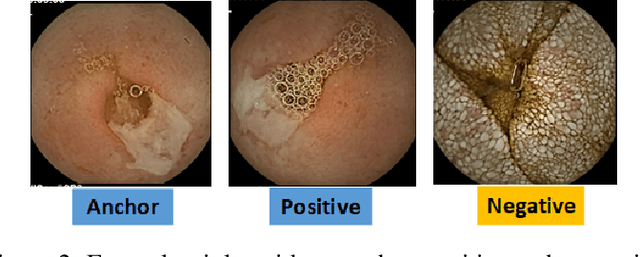
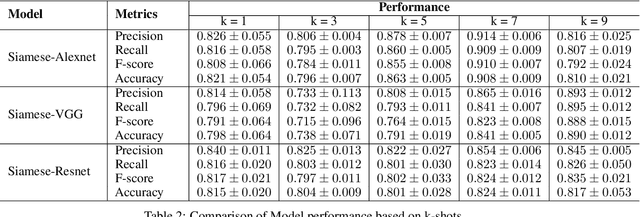
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.
Hierarchical Deep Convolutional Neural Networks for Multi-category Diagnosis of Gastrointestinal Disorders on Histopathological Images
May 08, 2020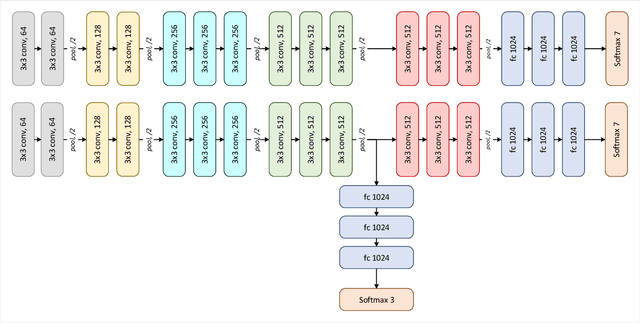
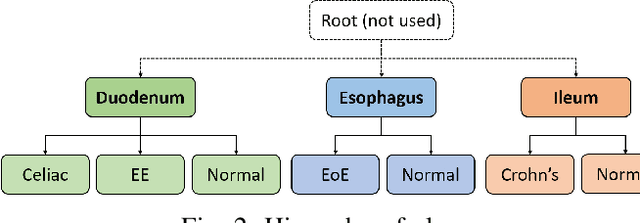
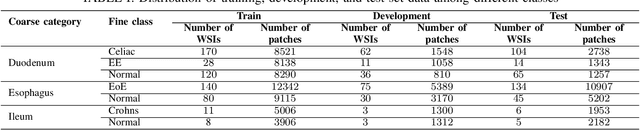
Deep convolutional neural networks (CNNs) have been successful for a wide range of computer vision tasks including image classification. A specific area of application lies in digital pathology for pattern recognition in tissue-based diagnosis of gastrointestinal (GI) diseases. This domain can utilize CNNs to translate histopathological images into precise diagnostics. This is challenging since these complex biopsies are heterogeneous and require multiple levels of assessment. This is mainly due to structural similarities in different parts of the GI tract and shared features among different gut diseases. Addressing this problem with a flat model which assumes all classes (parts of the gut and their diseases) are equally difficult to distinguish leads to an inadequate assessment of each class. Since hierarchical model restricts classification error to each sub-class, it leads to a more informative model compared to a flat model. In this paper we propose to apply hierarchical classification of biopsy images from different parts of the GI tract and the receptive diseases within each. We embedded a class hierarchy into the plain VGGNet to take advantage of the hierarchical structure of its layers. The proposed model was evaluated using an independent set of image patches from 373 whole slide images. The results indicate that hierarchical model can achieve better results compared to the flat model for multi-category diagnosis of GI disorders using histopathological images.
Dialogue-based simulation for cultural awareness training
Feb 01, 2020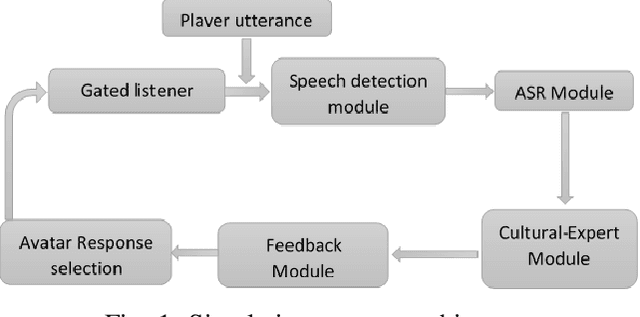

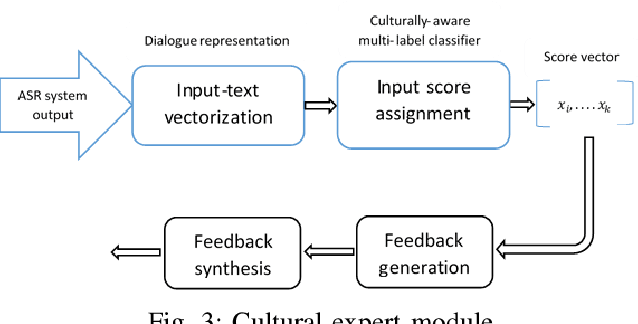

Existing simulations designed for cultural and interpersonal skill training rely on pre-defined responses with a menu option selection interface. Using a multiple-choice interface and restricting trainees' responses may limit the trainees' ability to apply the lessons in real life situations. This systems also uses a simplistic evaluation model, where trainees' selected options are marked as either correct or incorrect. This model may not capture sufficient information that could drive an adaptive feedback mechanism to improve trainees' cultural awareness. This paper describes the design of a dialogue-based simulation for cultural awareness training. The simulation, built around a disaster management scenario involving a joint coalition between the US and the Chinese armies. Trainees were able to engage in realistic dialogue with the Chinese agent. Their responses, at different points, get evaluated by different multi-label classification models. Based on training on our dataset, the models score the trainees' responses for cultural awareness in the Chinese culture. Trainees also get feedback that informs the cultural appropriateness of their responses. The result of this work showed the following; i) A feature-based evaluation model improves the design, modeling and computation of dialogue-based training simulation systems; ii) Output from current automatic speech recognition (ASR) systems gave comparable end results compared with the output from manual transcription; iii) A multi-label classification model trained as a cultural expert gave results which were comparable with scores assigned by human annotators.