 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHHAR-net: Hierarchical Human Activity Recognition using Neural Networks
Nov 10, 2020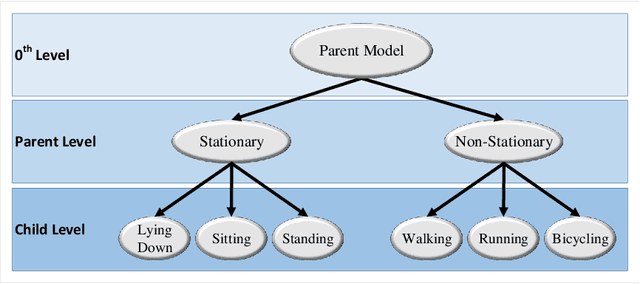



Activity recognition using built-in sensors in smart and wearable devices provides great opportunities to understand and detect human behavior in the wild and gives a more holistic view of individuals' health and well being. Numerous computational methods have been applied to sensor streams to recognize different daily activities. However, most methods are unable to capture different layers of activities concealed in human behavior. Also, the performance of the models starts to decrease with increasing the number of activities. This research aims at building a hierarchical classification with Neural Networks to recognize human activities based on different levels of abstraction. We evaluate our model on the Extrasensory dataset; a dataset collected in the wild and containing data from smartphones and smartwatches. We use a two-level hierarchy with a total of six mutually exclusive labels namely, "lying down", "sitting", "standing in place", "walking", "running", and "bicycling" divided into "stationary" and "non-stationary". The results show that our model can recognize low-level activities (stationary/non-stationary) with 95.8% accuracy and overall accuracy of 92.8% over six labels. This is 3% above our best performing baseline.
Improve Document Embedding for Text Categorization Through Deep Siamese Neural Network
May 31, 2020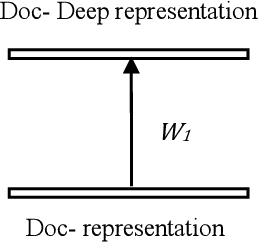
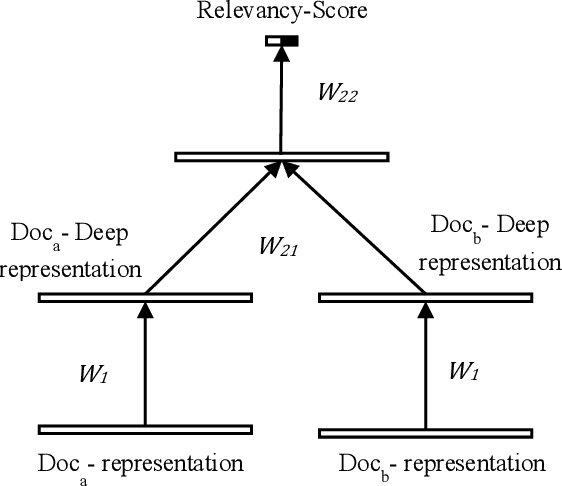
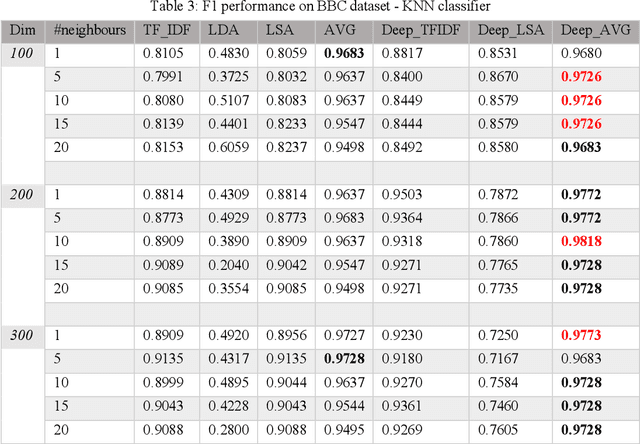
Due to the increasing amount of data on the internet, finding a highly-informative, low-dimensional representation for text is one of the main challenges for efficient natural language processing tasks including text classification. This representation should capture the semantic information of the text while retaining their relevance level for document classification. This approach maps the documents with similar topics to a similar space in vector space representation. To obtain representation for large text, we propose the utilization of deep Siamese neural networks. To embed document relevance in topics in the distributed representation, we use a Siamese neural network to jointly learn document representations. Our Siamese network consists of two sub-network of multi-layer perceptron. We examine our representation for the text categorization task on BBC news dataset. The results show that the proposed representations outperform the conventional and state-of-the-art representations in the text classification task on this dataset.
Dialogue-based simulation for cultural awareness training
Feb 01, 2020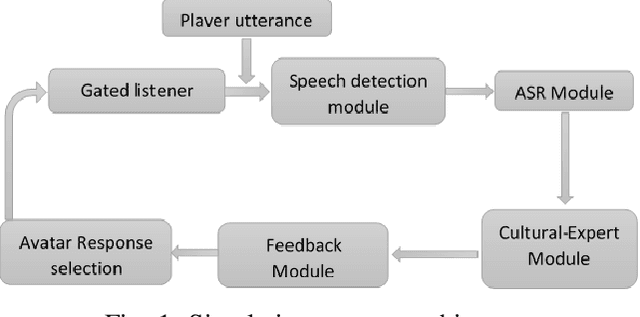

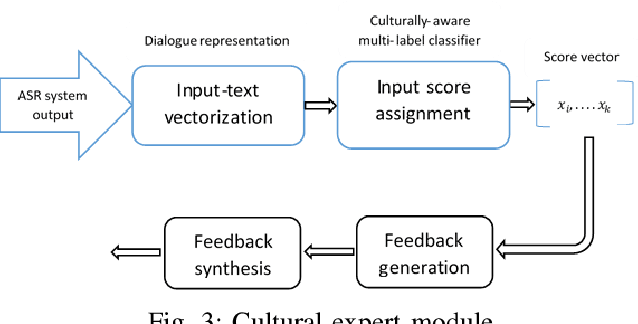

Existing simulations designed for cultural and interpersonal skill training rely on pre-defined responses with a menu option selection interface. Using a multiple-choice interface and restricting trainees' responses may limit the trainees' ability to apply the lessons in real life situations. This systems also uses a simplistic evaluation model, where trainees' selected options are marked as either correct or incorrect. This model may not capture sufficient information that could drive an adaptive feedback mechanism to improve trainees' cultural awareness. This paper describes the design of a dialogue-based simulation for cultural awareness training. The simulation, built around a disaster management scenario involving a joint coalition between the US and the Chinese armies. Trainees were able to engage in realistic dialogue with the Chinese agent. Their responses, at different points, get evaluated by different multi-label classification models. Based on training on our dataset, the models score the trainees' responses for cultural awareness in the Chinese culture. Trainees also get feedback that informs the cultural appropriateness of their responses. The result of this work showed the following; i) A feature-based evaluation model improves the design, modeling and computation of dialogue-based training simulation systems; ii) Output from current automatic speech recognition (ASR) systems gave comparable end results compared with the output from manual transcription; iii) A multi-label classification model trained as a cultural expert gave results which were comparable with scores assigned by human annotators.