 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Analysis for Pediatric Upper Body Motor Function Assessment
Sep 10, 2022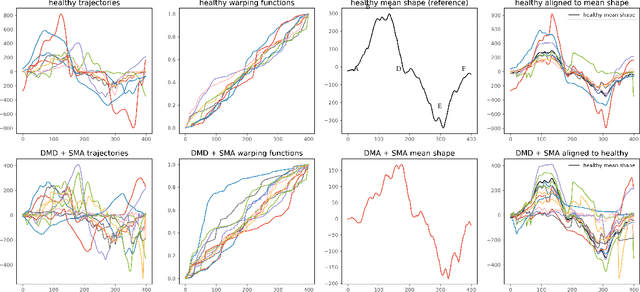



Neuromuscular disorders, such as Spinal Muscular Atrophy (SMA) and Duchenne Muscular Dystrophy (DMD), cause progressive muscular degeneration and loss of motor function for 1 in 6,000 children. Traditional upper limb motor function assessments do not quantitatively measure patient-performed motions, which makes it difficult to track progress for incremental changes. Assessing motor function in children with neuromuscular disorders is particularly challenging because they can be nervous or excited during experiments, or simply be too young to follow precise instructions. These challenges translate to confounding factors such as performing different parts of the arm curl slower or faster (phase variability) which affects the assessed motion quality. This paper uses curve registration and shape analysis to temporally align trajectories while simultaneously extracting a mean reference shape. Distances from this mean shape are used to assess the quality of motion. The proposed metric is invariant to confounding factors, such as phase variability, while suggesting several clinically relevant insights. First, there are statistically significant differences between functional scores for the control and patient populations (p$=$0.0213$\le$0.05). Next, several patients in the patient cohort are able to perform motion on par with the healthy cohort and vice versa. Our metric, which is computed based on wearables, is related to the Brooke's score ((p$=$0.00063$\le$0.05)), as well as motor function assessments based on dynamometry ((p$=$0.0006$\le$0.05)). These results show promise towards ubiquitous motion quality assessment in daily life.
HHAR-net: Hierarchical Human Activity Recognition using Neural Networks
Nov 10, 2020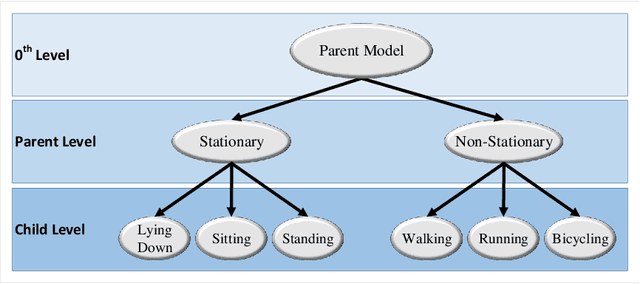



Activity recognition using built-in sensors in smart and wearable devices provides great opportunities to understand and detect human behavior in the wild and gives a more holistic view of individuals' health and well being. Numerous computational methods have been applied to sensor streams to recognize different daily activities. However, most methods are unable to capture different layers of activities concealed in human behavior. Also, the performance of the models starts to decrease with increasing the number of activities. This research aims at building a hierarchical classification with Neural Networks to recognize human activities based on different levels of abstraction. We evaluate our model on the Extrasensory dataset; a dataset collected in the wild and containing data from smartphones and smartwatches. We use a two-level hierarchy with a total of six mutually exclusive labels namely, "lying down", "sitting", "standing in place", "walking", "running", and "bicycling" divided into "stationary" and "non-stationary". The results show that our model can recognize low-level activities (stationary/non-stationary) with 95.8% accuracy and overall accuracy of 92.8% over six labels. This is 3% above our best performing baseline.
Sparse Longitudinal Representations of Electronic Health Record Data for the Early Detection of Chronic Kidney Disease in Diabetic Patients
Nov 09, 2020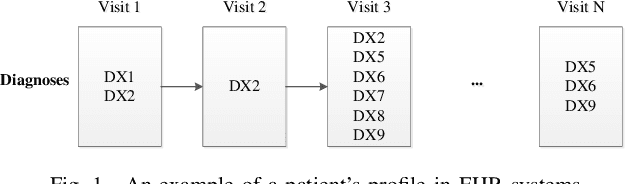
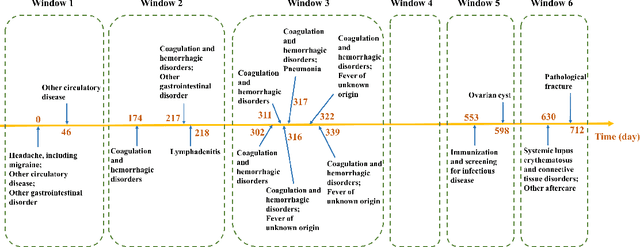
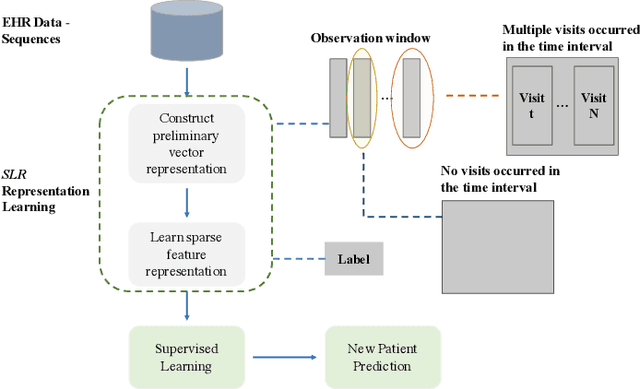
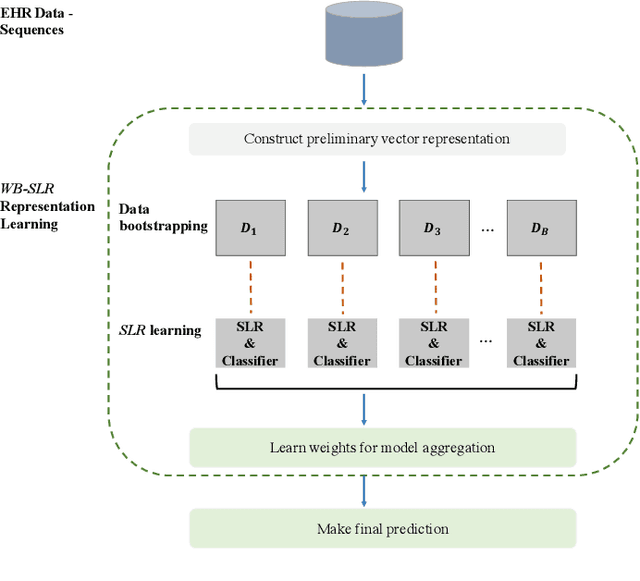
Chronic kidney disease (CKD) is a gradual loss of renal function over time, and it increases the risk of mortality, decreased quality of life, as well as serious complications. The prevalence of CKD has been increasing in the last couple of decades, which is partly due to the increased prevalence of diabetes and hypertension. To accurately detect CKD in diabetic patients, we propose a novel framework to learn sparse longitudinal representations of patients' medical records. The proposed method is also compared with widely used baselines such as Aggregated Frequency Vector and Bag-of-Pattern in Sequences on real EHR data, and the experimental results indicate that the proposed model achieves higher predictive performance. Additionally, the learned representations are interpreted and visualized to bring clinical insights.
Improving Classification through Weak Supervision in Context-specific Conversational Agent Development for Teacher Education
Oct 23, 2020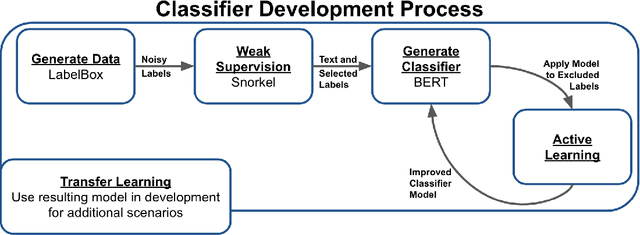

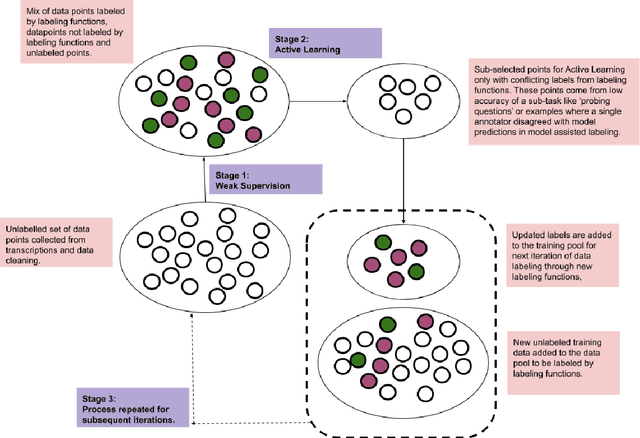

Machine learning techniques applied to the Natural Language Processing (NLP) component of conversational agent development show promising results for improved accuracy and quality of feedback that a conversational agent can provide. The effort required to develop an educational scenario specific conversational agent is time consuming as it requires domain experts to label and annotate noisy data sources such as classroom videos. Previous approaches to modeling annotations have relied on labeling thousands of examples and calculating inter-annotator agreement and majority votes in order to model the necessary scenarios. This method, while proven successful, ignores individual annotator strengths in labeling a data point and under-utilizes examples that do not have a majority vote for labeling. We propose using a multi-task weak supervision method combined with active learning to address these concerns. This approach requires less labeling than traditional methods and shows significant improvements in precision, efficiency, and time-requirements than the majority vote method (Ratner 2019). We demonstrate the validity of this method on the Google Jigsaw data set and then propose a scenario to apply this method using the Instructional Quality Assessment(IQA) to define the categories for labeling. We propose using probabilistic modeling of annotator labeling to generate active learning examples to further label the data. Active learning is able to iteratively improve the training performance and accuracy of the original classification model. This approach combines state-of-the art labeling techniques of weak supervision and active learning to optimize results in the educational domain and could be further used to lessen the data requirements for expanded scenarios within the education domain through transfer learning.
Geometry matters: Exploring language examples at the decision boundary
Oct 14, 2020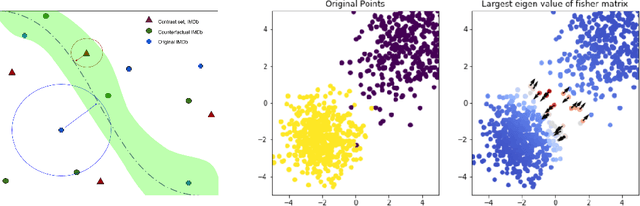


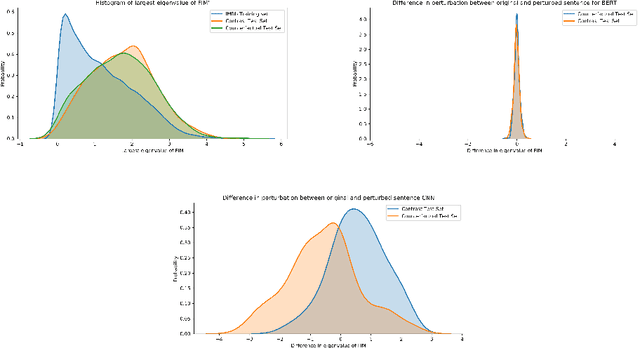
A growing body of recent evidence has highlighted the limitations of natural language processing (NLP) datasets and classifiers. These include the presence of annotation artifacts in datasets, classifiers relying on shallow features like a single word (e.g., if a movie review has the word "romantic", the review tends to be positive), or unnecessary words (e.g., learning a proper noun to classify a movie as positive or negative). The presence of such artifacts has subsequently led to the development of challenging datasets to force the model to generalize better. While a variety of heuristic strategies, such as counterfactual examples and contrast sets, have been proposed, the theoretical justification about what makes these examples difficult is often lacking or unclear. In this paper, using tools from information geometry, we propose a theoretical way to quantify the difficulty of an example in NLP. Using our approach, we explore difficult examples for two popular NLP architectures. We discover that both BERT and CNN are susceptible to single word substitutions in high difficulty examples. Consequently, examples with low difficulty scores tend to be robust to multiple word substitutions. Our analysis shows that perturbations like contrast sets and counterfactual examples are not necessarily difficult for the model, and they may not be accomplishing the intended goal. Our approach is simple, architecture agnostic, and easily extendable to other datasets. All the code used will be made publicly available, including a tool to explore the difficult examples for other datasets.
A Framework for Addressing the Risks and Opportunities In AI-Supported Virtual Health Coaches
Oct 12, 2020
Virtual coaching has rapidly evolved into a foundational component of modern clinical practice. At a time when healthcare professionals are in short supply and the demand for low-cost treatments is ever-increasing, virtual health coaches (VHCs) offer intervention-on-demand for those limited by finances or geographic access to care. More recently, AI-powered virtual coaches have become a viable complement to human coaches. However, the push for AI-powered coaching systems raises several important issues for researchers, designers, clinicians, and patients. In this paper, we present a novel framework to guide the design and development of virtual coaching systems. This framework augments a traditional data science pipeline with four key guiding goals: reliability, fairness, engagement, and ethics.
EyeCar: Modeling the Visual Attention Allocation of Drivers in Semi-Autonomous Vehicles
Dec 24, 2019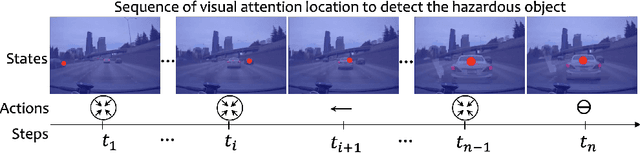
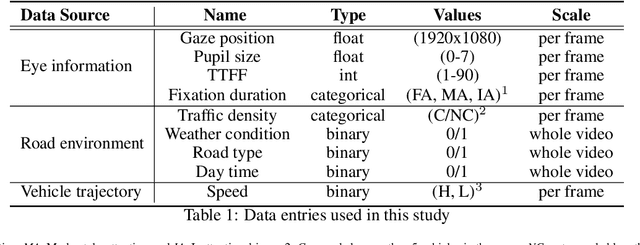

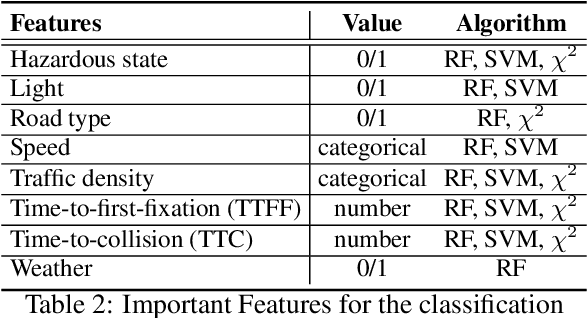
A safe transition between autonomous and manual control requires sustained visual attention of the driver for the perception and assessment of hazards in dynamic driving environments. Thus, drivers must retain a certain level of situation awareness to safely takeover. Understanding the visual attention allocation of drivers can pave the way for inferring their dynamic state of situational awareness. We propose a reinforcement and inverse-reinforcement learning framework for modeling passive drivers' visual attention allocation in semi-autonomous vehicles. The proposed approach measures the eye-movement of passive drivers to evaluate their responses to real-world rear-end collisions. The results show substantial individual differences in the eye fixation patterns by driving experience, even among fully attentive drivers. Experienced drivers were more attentive to the situational dynamics and were able to identify potentially hazardous objects before any collisions occurred. These models of visual attention could potentially be integrated into autonomous systems to continuously monitor and guide effective intervention. Keywords: Visual attention allocation; Situation awareness; Eye movements; Eye fixation; Eye-Tracking; Reinforcement Learning; Inverse Reinforcement Learning