 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Classification through Weak Supervision in Context-specific Conversational Agent Development for Teacher Education
Paper and Code
Oct 23, 2020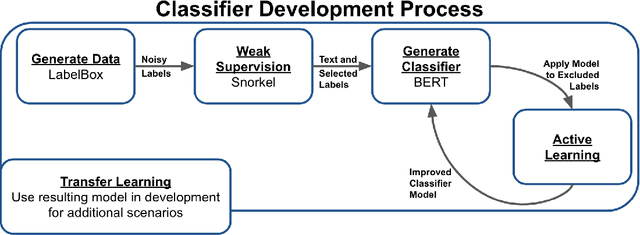

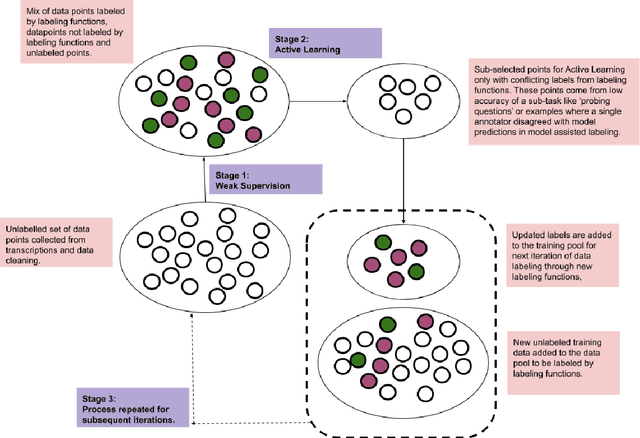

Machine learning techniques applied to the Natural Language Processing (NLP) component of conversational agent development show promising results for improved accuracy and quality of feedback that a conversational agent can provide. The effort required to develop an educational scenario specific conversational agent is time consuming as it requires domain experts to label and annotate noisy data sources such as classroom videos. Previous approaches to modeling annotations have relied on labeling thousands of examples and calculating inter-annotator agreement and majority votes in order to model the necessary scenarios. This method, while proven successful, ignores individual annotator strengths in labeling a data point and under-utilizes examples that do not have a majority vote for labeling. We propose using a multi-task weak supervision method combined with active learning to address these concerns. This approach requires less labeling than traditional methods and shows significant improvements in precision, efficiency, and time-requirements than the majority vote method (Ratner 2019). We demonstrate the validity of this method on the Google Jigsaw data set and then propose a scenario to apply this method using the Instructional Quality Assessment(IQA) to define the categories for labeling. We propose using probabilistic modeling of annotator labeling to generate active learning examples to further label the data. Active learning is able to iteratively improve the training performance and accuracy of the original classification model. This approach combines state-of-the art labeling techniques of weak supervision and active learning to optimize results in the educational domain and could be further used to lessen the data requirements for expanded scenarios within the education domain through transfer learning.