 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Dec 05, 2024



Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
EyeCar: Modeling the Visual Attention Allocation of Drivers in Semi-Autonomous Vehicles
Dec 24, 2019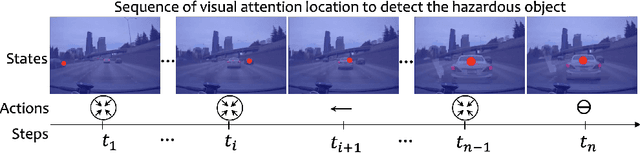
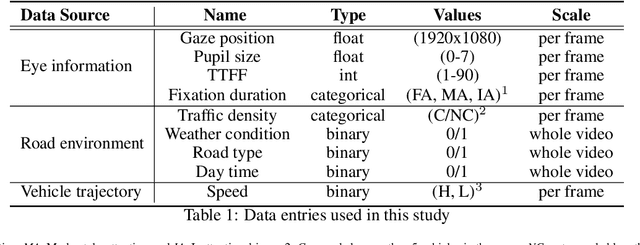

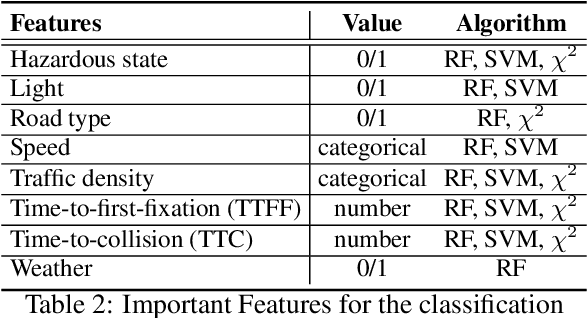
A safe transition between autonomous and manual control requires sustained visual attention of the driver for the perception and assessment of hazards in dynamic driving environments. Thus, drivers must retain a certain level of situation awareness to safely takeover. Understanding the visual attention allocation of drivers can pave the way for inferring their dynamic state of situational awareness. We propose a reinforcement and inverse-reinforcement learning framework for modeling passive drivers' visual attention allocation in semi-autonomous vehicles. The proposed approach measures the eye-movement of passive drivers to evaluate their responses to real-world rear-end collisions. The results show substantial individual differences in the eye fixation patterns by driving experience, even among fully attentive drivers. Experienced drivers were more attentive to the situational dynamics and were able to identify potentially hazardous objects before any collisions occurred. These models of visual attention could potentially be integrated into autonomous systems to continuously monitor and guide effective intervention. Keywords: Visual attention allocation; Situation awareness; Eye movements; Eye fixation; Eye-Tracking; Reinforcement Learning; Inverse Reinforcement Learning
Biomimetic Ultra-Broadband Perfect Absorbers Optimised with Reinforcement Learning
Oct 28, 2019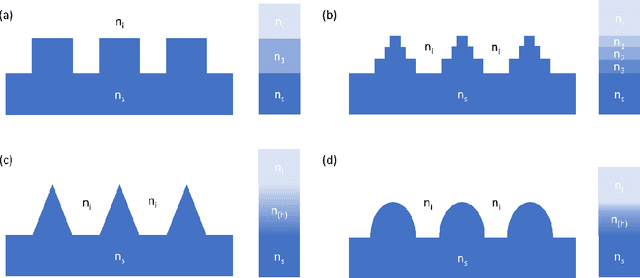
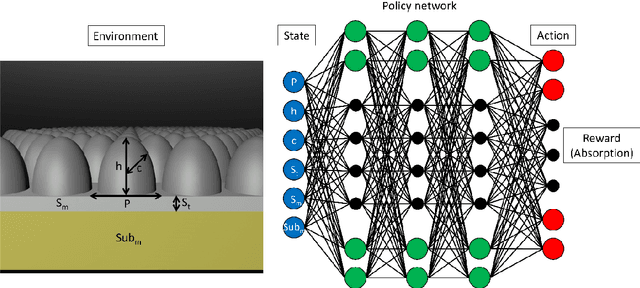
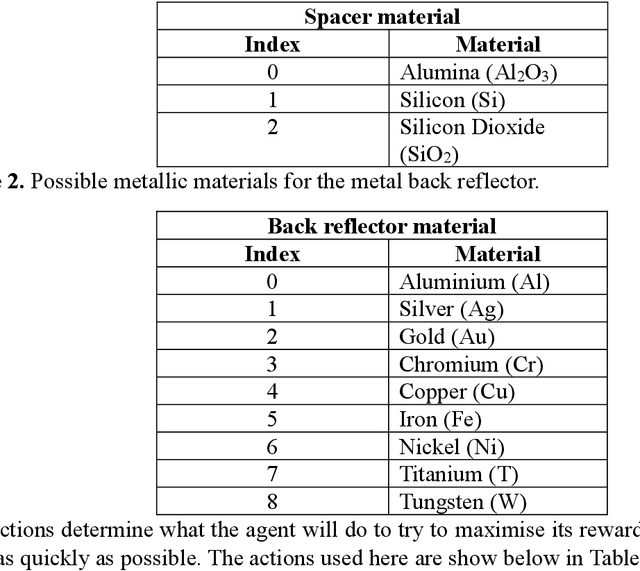

By learning the optimal policy with a double deep Q-learning network, we design ultra-broadband, biomimetic, perfect absorbers with various materials, based the structure of a moths eye. All absorbers achieve over 90% average absorption from 400 to 1,600 nm. By training a DDQN with motheye structures made up of chromium, we transfer the learned knowledge to other, similar materials to quickly and efficiently find the optimal parameters from the around 1 billion possible options. The knowledge learned from previous optimisations helps the network to find the best solution for a new material in fewer steps, dramatically increasing the efficiency of finding designs with ultra-broadband absorption.