 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Matters: Harnessing Video Models in Super-Resolution
Dec 16, 20243D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating 'smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets. Project page: https://ko-lani.github.io/Sequence-Matters
MetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Dec 05, 2024



Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
Sharp-NeRF: Grid-based Fast Deblurring Neural Radiance Fields Using Sharpness Prior
Jan 01, 2024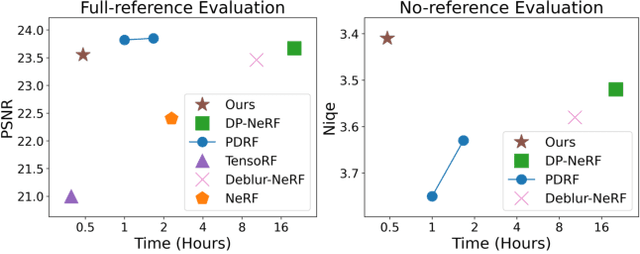
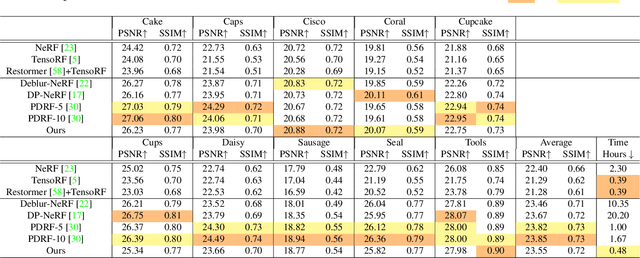
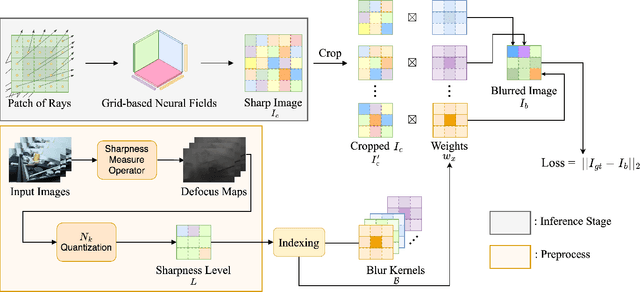
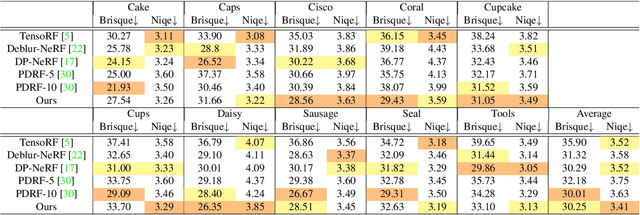
Neural Radiance Fields (NeRF) have shown remarkable performance in neural rendering-based novel view synthesis. However, NeRF suffers from severe visual quality degradation when the input images have been captured under imperfect conditions, such as poor illumination, defocus blurring, and lens aberrations. Especially, defocus blur is quite common in the images when they are normally captured using cameras. Although few recent studies have proposed to render sharp images of considerably high-quality, yet they still face many key challenges. In particular, those methods have employed a Multi-Layer Perceptron (MLP) based NeRF, which requires tremendous computational time. To overcome these shortcomings, this paper proposes a novel technique Sharp-NeRF -- a grid-based NeRF that renders clean and sharp images from the input blurry images within half an hour of training. To do so, we used several grid-based kernels to accurately model the sharpness/blurriness of the scene. The sharpness level of the pixels is computed to learn the spatially varying blur kernels. We have conducted experiments on the benchmarks consisting of blurry images and have evaluated full-reference and non-reference metrics. The qualitative and quantitative results have revealed that our approach renders the sharp novel views with vivid colors and fine details, and it has considerably faster training time than the previous works. Our project page is available at https://benhenryl.github.io/SharpNeRF/
Deblurring 3D Gaussian Splatting
Jan 01, 2024Recent studies in Radiance Fields have paved the robust way for novel view synthesis with their photorealistic rendering quality. Nevertheless, they usually employ neural networks and volumetric rendering, which are costly to train and impede their broad use in various real-time applications due to the lengthy rendering time. Lately 3D Gaussians splatting-based approach has been proposed to model the 3D scene, and it achieves remarkable visual quality while rendering the images in real-time. However, it suffers from severe degradation in the rendering quality if the training images are blurry. Blurriness commonly occurs due to the lens defocusing, object motion, and camera shake, and it inevitably intervenes in clean image acquisition. Several previous studies have attempted to render clean and sharp images from blurry input images using neural fields. The majority of those works, however, are designed only for volumetric rendering-based neural radiance fields and are not straightforwardly applicable to rasterization-based 3D Gaussian splatting methods. Thus, we propose a novel real-time deblurring framework, deblurring 3D Gaussian Splatting, using a small Multi-Layer Perceptron (MLP) that manipulates the covariance of each 3D Gaussian to model the scene blurriness. While deblurring 3D Gaussian Splatting can still enjoy real-time rendering, it can reconstruct fine and sharp details from blurry images. A variety of experiments have been conducted on the benchmark, and the results have revealed the effectiveness of our approach for deblurring. Qualitative results are available at https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/
Masked Wavelet Representation for Compact Neural Radiance Fields
Dec 18, 2022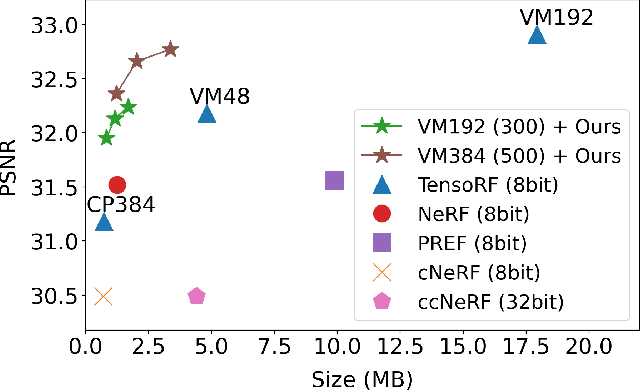


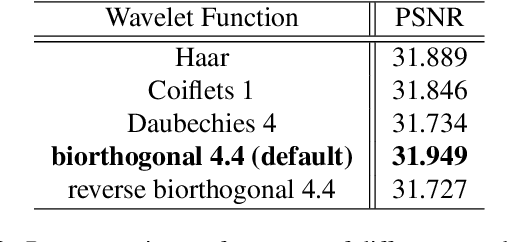
Neural radiance fields (NeRF) have demonstrated the potential of coordinate-based neural representation (neural fields or implicit neural representation) in neural rendering. However, using a multi-layer perceptron (MLP) to represent a 3D scene or object requires enormous computational resources and time. There have been recent studies on how to reduce these computational inefficiencies by using additional data structures, such as grids or trees. Despite the promising performance, the explicit data structure necessitates a substantial amount of memory. In this work, we present a method to reduce the size without compromising the advantages of having additional data structures. In detail, we propose using the wavelet transform on grid-based neural fields. Grid-based neural fields are for fast convergence, and the wavelet transform, whose efficiency has been demonstrated in high-performance standard codecs, is to improve the parameter efficiency of grids. Furthermore, in order to achieve a higher sparsity of grid coefficients while maintaining reconstruction quality, we present a novel trainable masking approach. Experimental results demonstrate that non-spatial grid coefficients, such as wavelet coefficients, are capable of attaining a higher level of sparsity than spatial grid coefficients, resulting in a more compact representation. With our proposed mask and compression pipeline, we achieved state-of-the-art performance within a memory budget of 2 MB. Our code is available at https://github.com/daniel03c1/masked_wavelet_nerf.
PIXEL: Physics-Informed Cell Representations for Fast and Accurate PDE Solvers
Jul 26, 2022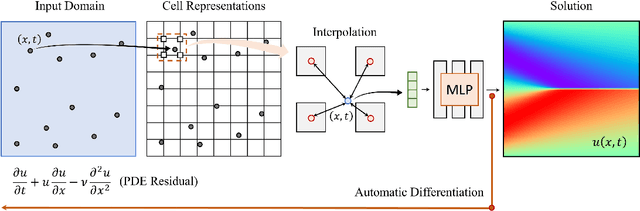
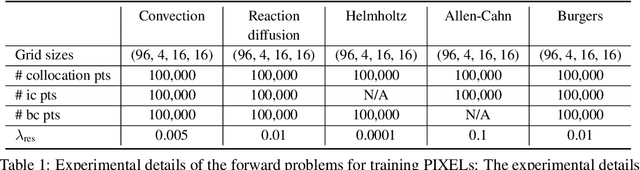
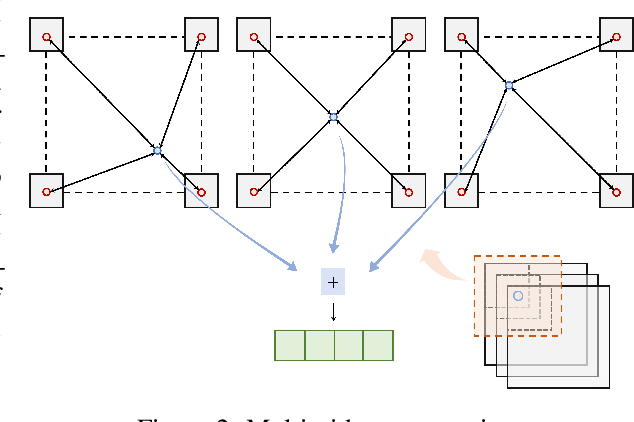

With the increases in computational power and advances in machine learning, data-driven learning-based methods have gained significant attention in solving PDEs. Physics-informed neural networks (PINNs) have recently emerged and succeeded in various forward and inverse PDEs problems thanks to their excellent properties, such as flexibility, mesh-free solutions, and unsupervised training. However, their slower convergence speed and relatively inaccurate solutions often limit their broader applicability in many science and engineering domains. This paper proposes a new kind of data-driven PDEs solver, physics-informed cell representations (PIXEL), elegantly combining classical numerical methods and learning-based approaches. We adopt a grid structure from the numerical methods to improve accuracy and convergence speed and overcome the spectral bias presented in PINNs. Moreover, the proposed method enjoys the same benefits in PINNs, e.g., using the same optimization frameworks to solve both forward and inverse PDE problems and readily enforcing PDE constraints with modern automatic differentiation techniques. We provide experimental results on various challenging PDEs that the original PINNs have struggled with and show that PIXEL achieves fast convergence speed and high accuracy.