 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2Xplat: Two Experts Are Better Than One Generalist
Mar 24, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
Two Experts Are Better Than One Generalist: Decoupling Geometry and Appearance for Feed-Forward 3D Gaussian Splatting
Mar 22, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
VGGT-World: Transforming VGGT into an Autoregressive Geometry World Model
Mar 13, 2026World models that forecast scene evolution by generating future video frames devote the bulk of their capacity to photometric details, yet the resulting predictions often remain geometrically inconsistent. We present VGGT-World, a geometry world model that side-steps video generation entirely and instead forecasts the temporal evolution of frozen geometry-foundation-model (GFM) features. Concretely, we repurpose the latent tokens of a frozen VGGT as the world state and train a lightweight temporal flow transformer to autoregressively predict their future trajectory. Two technical challenges arise in this high-dimensional (d=1024) feature space: (i) standard velocity-prediction flow matching collapses, and (ii) autoregressive rollout suffers from compounding exposure bias. We address the first with a clean-target (z-prediction) parameterization that yields a substantially higher signal-to-noise ratio, and the second with a two-stage latent flow-forcing curriculum that progressively conditions the model on its own partially denoised rollouts. Experiments on KITTI, Cityscapes, and TartanAir demonstrate that VGGT-World significantly outperforms the strongest baselines in depth forecasting while running 3.6-5 times faster with only 0.43B trainable parameters, establishing frozen GFM features as an effective and efficient predictive state for 3D world modeling.
TabReason: A Reinforcement Learning-Enhanced Reasoning LLM for Explainable Tabular Data Prediction
May 29, 2025



Predictive modeling on tabular data is the cornerstone of many real-world applications. Although gradient boosting machines and some recent deep models achieve strong performance on tabular data, they often lack interpretability. On the other hand, large language models (LLMs) have demonstrated powerful capabilities to generate human-like reasoning and explanations, but remain under-performed for tabular data prediction. In this paper, we propose a new approach that leverages reasoning-based LLMs, trained using reinforcement learning, to perform more accurate and explainable predictions on tabular data. Our method introduces custom reward functions that guide the model not only toward high prediction accuracy but also toward human-understandable reasons for its predictions. Experimental results show that our model achieves promising performance on financial benchmark datasets, outperforming most existing LLMs.
Intern-GS: Vision Model Guided Sparse-View 3D Gaussian Splatting
May 27, 2025Sparse-view scene reconstruction often faces significant challenges due to the constraints imposed by limited observational data. These limitations result in incomplete information, leading to suboptimal reconstructions using existing methodologies. To address this, we present Intern-GS, a novel approach that effectively leverages rich prior knowledge from vision foundation models to enhance the process of sparse-view Gaussian Splatting, thereby enabling high-quality scene reconstruction. Specifically, Intern-GS utilizes vision foundation models to guide both the initialization and the optimization process of 3D Gaussian splatting, effectively addressing the limitations of sparse inputs. In the initialization process, our method employs DUSt3R to generate a dense and non-redundant gaussian point cloud. This approach significantly alleviates the limitations encountered by traditional structure-from-motion (SfM) methods, which often struggle under sparse-view constraints. During the optimization process, vision foundation models predict depth and appearance for unobserved views, refining the 3D Gaussians to compensate for missing information in unseen regions. Extensive experiments demonstrate that Intern-GS achieves state-of-the-art rendering quality across diverse datasets, including both forward-facing and large-scale scenes, such as LLFF, DTU, and Tanks and Temples.
Localized Physics-informed Gaussian Processes with Curriculum Training for Topology Optimization
Mar 18, 2025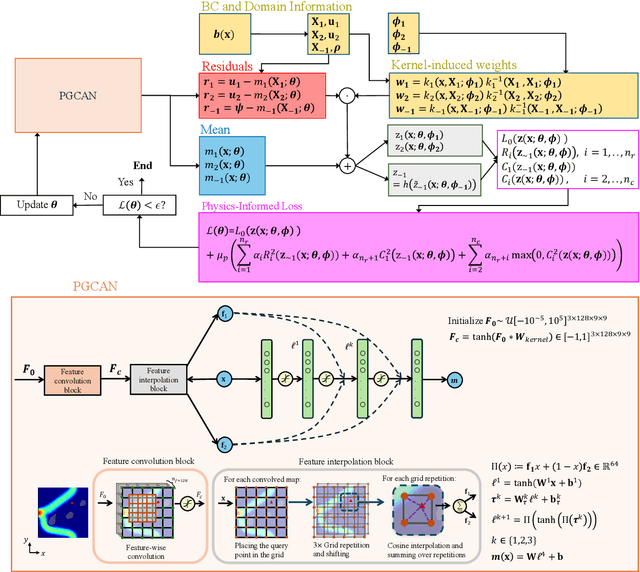
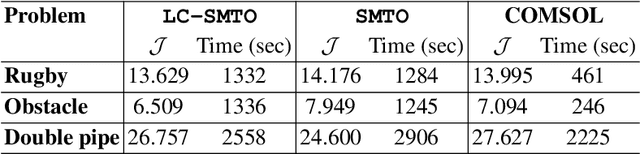
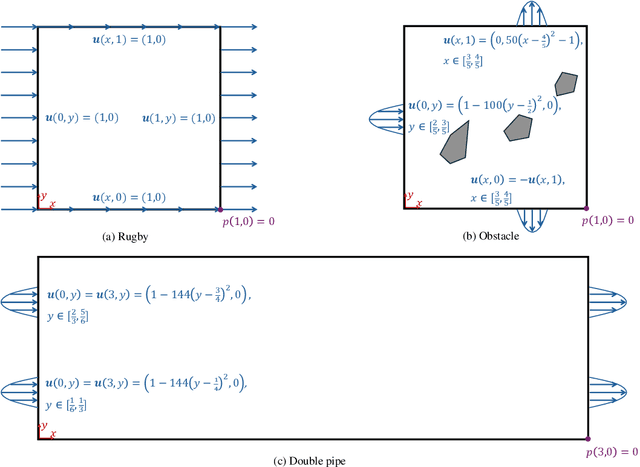
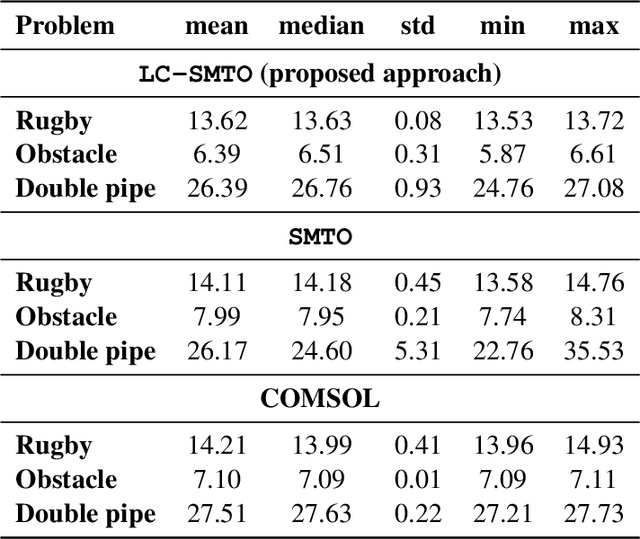
We introduce a simultaneous and meshfree topology optimization (TO) framework based on physics-informed Gaussian processes (GPs). Our framework endows all design and state variables via GP priors which have a shared, multi-output mean function that is parametrized via a customized deep neural network (DNN). The parameters of this mean function are estimated by minimizing a multi-component loss function that depends on the performance metric, design constraints, and the residuals on the state equations. Our TO approach yields well-defined material interfaces and has a built-in continuation nature that promotes global optimality. Other unique features of our approach include (1) its customized DNN which, unlike fully connected feed-forward DNNs, has a localized learning capacity that enables capturing intricate topologies and reducing residuals in high gradient fields, (2) its loss function that leverages localized weights to promote solution accuracy around interfaces, and (3) its use of curriculum training to avoid local optimality.To demonstrate the power of our framework, we validate it against commercial TO package COMSOL on three problems involving dissipated power minimization in Stokes flow.
Fairness Analysis of CLIP-Based Foundation Models for X-Ray Image Classification
Jan 31, 2025


X-ray imaging is pivotal in medical diagnostics, offering non-invasive insights into a range of health conditions. Recently, vision-language models, such as the Contrastive Language-Image Pretraining (CLIP) model, have demonstrated potential in improving diagnostic accuracy by leveraging large-scale image-text datasets. However, since CLIP was not initially designed for medical images, several CLIP-like models trained specifically on medical images have been developed. Despite their enhanced performance, issues of fairness - particularly regarding demographic attributes - remain largely unaddressed. In this study, we perform a comprehensive fairness analysis of CLIP-like models applied to X-ray image classification. We assess their performance and fairness across diverse patient demographics and disease categories using zero-shot inference and various fine-tuning techniques, including Linear Probing, Multilayer Perceptron (MLP), Low-Rank Adaptation (LoRA), and full fine-tuning. Our results indicate that while fine-tuning improves model accuracy, fairness concerns persist, highlighting the need for further fairness interventions in these foundational models.
OVGaussian: Generalizable 3D Gaussian Segmentation with Open Vocabularies
Dec 31, 2024Open-vocabulary scene understanding using 3D Gaussian (3DGS) representations has garnered considerable attention. However, existing methods mostly lift knowledge from large 2D vision models into 3DGS on a scene-by-scene basis, restricting the capabilities of open-vocabulary querying within their training scenes so that lacking the generalizability to novel scenes. In this work, we propose \textbf{OVGaussian}, a generalizable \textbf{O}pen-\textbf{V}ocabulary 3D semantic segmentation framework based on the 3D \textbf{Gaussian} representation. We first construct a large-scale 3D scene dataset based on 3DGS, dubbed \textbf{SegGaussian}, which provides detailed semantic and instance annotations for both Gaussian points and multi-view images. To promote semantic generalization across scenes, we introduce Generalizable Semantic Rasterization (GSR), which leverages a 3D neural network to learn and predict the semantic property for each 3D Gaussian point, where the semantic property can be rendered as multi-view consistent 2D semantic maps. In the next, we propose a Cross-modal Consistency Learning (CCL) framework that utilizes open-vocabulary annotations of 2D images and 3D Gaussians within SegGaussian to train the 3D neural network capable of open-vocabulary semantic segmentation across Gaussian-based 3D scenes. Experimental results demonstrate that OVGaussian significantly outperforms baseline methods, exhibiting robust cross-scene, cross-domain, and novel-view generalization capabilities. Code and the SegGaussian dataset will be released. (https://github.com/runnanchen/OVGaussian).
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Dec 09, 2024



Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.
Compact 3D Gaussian Splatting for Static and Dynamic Radiance Fields
Aug 07, 2024



3D Gaussian splatting (3DGS) has recently emerged as an alternative representation that leverages a 3D Gaussian-based representation and introduces an approximated volumetric rendering, achieving very fast rendering speed and promising image quality. Furthermore, subsequent studies have successfully extended 3DGS to dynamic 3D scenes, demonstrating its wide range of applications. However, a significant drawback arises as 3DGS and its following methods entail a substantial number of Gaussians to maintain the high fidelity of the rendered images, which requires a large amount of memory and storage. To address this critical issue, we place a specific emphasis on two key objectives: reducing the number of Gaussian points without sacrificing performance and compressing the Gaussian attributes, such as view-dependent color and covariance. To this end, we propose a learnable mask strategy that significantly reduces the number of Gaussians while preserving high performance. In addition, we propose a compact but effective representation of view-dependent color by employing a grid-based neural field rather than relying on spherical harmonics. Finally, we learn codebooks to compactly represent the geometric and temporal attributes by residual vector quantization. With model compression techniques such as quantization and entropy coding, we consistently show over 25x reduced storage and enhanced rendering speed compared to 3DGS for static scenes, while maintaining the quality of the scene representation. For dynamic scenes, our approach achieves more than 12x storage efficiency and retains a high-quality reconstruction compared to the existing state-of-the-art methods. Our work provides a comprehensive framework for 3D scene representation, achieving high performance, fast training, compactness, and real-time rendering. Our project page is available at https://maincold2.github.io/c3dgs/.