 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mappings in Mesh-based Simulations
Jun 14, 2025Many real-world physics and engineering problems arise in geometrically complex domains discretized by meshes for numerical simulations. The nodes of these potentially irregular meshes naturally form point clouds whose limited tractability poses significant challenges for learning mappings via machine learning models. To address this, we introduce a novel and parameter-free encoding scheme that aggregates footprints of points onto grid vertices and yields information-rich grid representations of the topology. Such structured representations are well-suited for standard convolution and FFT (Fast Fourier Transform) operations and enable efficient learning of mappings between encoded input-output pairs using Convolutional Neural Networks (CNNs). Specifically, we integrate our encoder with a uniquely designed UNet (E-UNet) and benchmark its performance against Fourier- and transformer-based models across diverse 2D and 3D problems where we analyze the performance in terms of predictive accuracy, data efficiency, and noise robustness. Furthermore, we highlight the versatility of our encoding scheme in various mapping tasks including recovering full point cloud responses from partial observations. Our proposed framework offers a practical alternative to both primitive and computationally intensive encoding schemes; supporting broad adoption in computational science applications involving mesh-based simulations.
A preliminary data fusion study to assess the feasibility of Foundation Process-Property Models in Laser Powder Bed Fusion
Mar 20, 2025Foundation models are at the forefront of an increasing number of critical applications. In regards to technologies such as additive manufacturing (AM), these models have the potential to dramatically accelerate process optimization and, in turn, design of next generation materials. A major challenge that impedes the construction of foundation process-property models is data scarcity. To understand the impact of this challenge, and since foundation models rely on data fusion, in this work we conduct controlled experiments where we focus on the transferability of information across different material systems and properties. More specifically, we generate experimental datasets from 17-4 PH and 316L stainless steels (SSs) in Laser Powder Bed Fusion (LPBF) where we measure the effect of five process parameters on porosity and hardness. We then leverage Gaussian processes (GPs) for process-property modeling in various configurations to test if knowledge about one material system or property can be leveraged to build more accurate machine learning models for other material systems or properties. Through extensive cross-validation studies and probing the GPs' interpretable hyperparameters, we study the intricate relation among data size and dimensionality, complexity of the process-property relations, noise, and characteristics of machine learning models. Our findings highlight the need for structured learning approaches that incorporate domain knowledge in building foundation process-property models rather than relying on uninformed data fusion in data-limited applications.
SEEK: Self-adaptive Explainable Kernel For Nonstationary Gaussian Processes
Mar 18, 2025Gaussian processes (GPs) are powerful probabilistic models that define flexible priors over functions, offering strong interpretability and uncertainty quantification. However, GP models often rely on simple, stationary kernels which can lead to suboptimal predictions and miscalibrated uncertainty estimates, especially in nonstationary real-world applications. In this paper, we introduce SEEK, a novel class of learnable kernels to model complex, nonstationary functions via GPs. Inspired by artificial neurons, SEEK is derived from first principles to ensure symmetry and positive semi-definiteness, key properties of valid kernels. The proposed method achieves flexible and adaptive nonstationarity by learning a mapping from a set of base kernels. Compared to existing techniques, our approach is more interpretable and much less prone to overfitting. We conduct comprehensive sensitivity analyses and comparative studies to demonstrate that our approach is not robust to only many of its design choices, but also outperforms existing stationary/nonstationary kernels in both mean prediction accuracy and uncertainty quantification.
Localized Physics-informed Gaussian Processes with Curriculum Training for Topology Optimization
Mar 18, 2025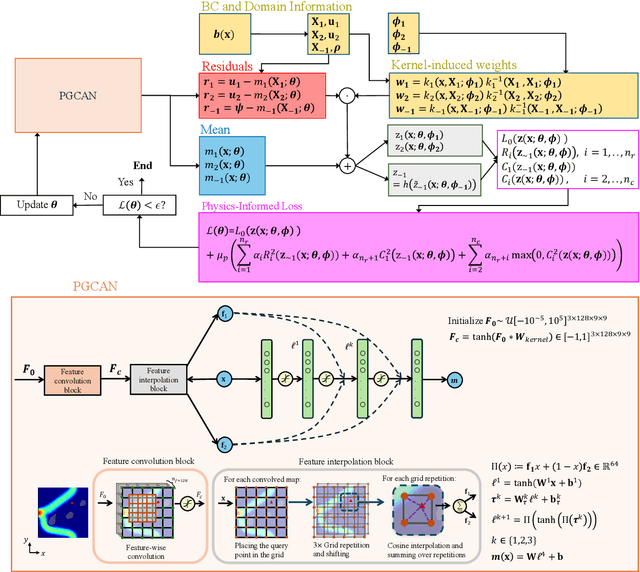
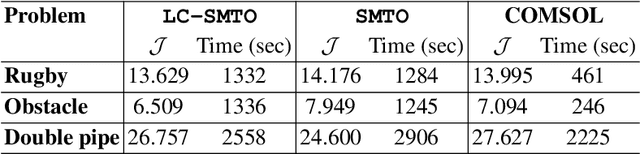
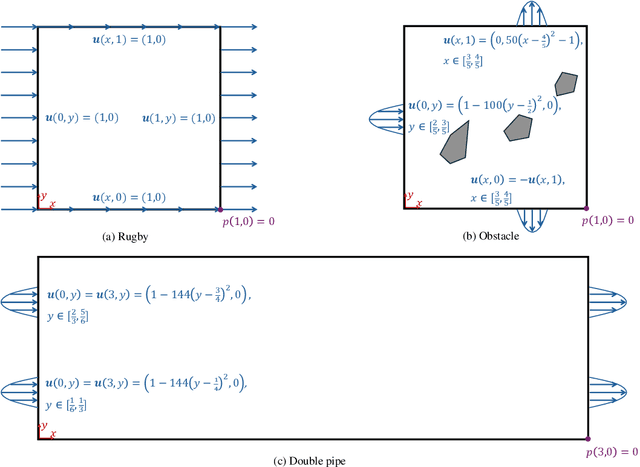
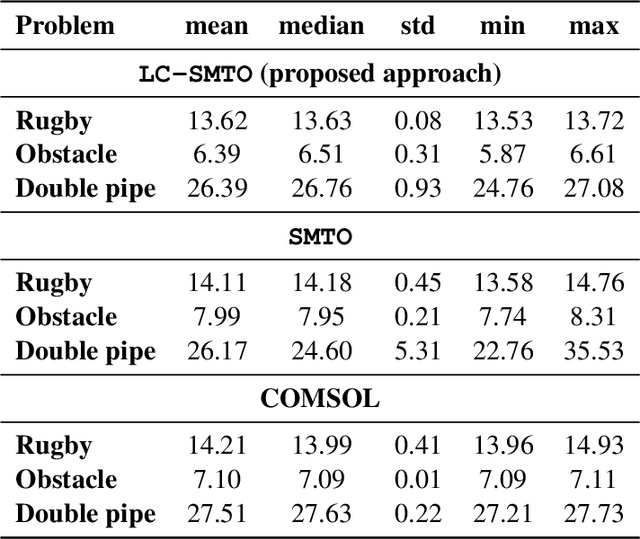
We introduce a simultaneous and meshfree topology optimization (TO) framework based on physics-informed Gaussian processes (GPs). Our framework endows all design and state variables via GP priors which have a shared, multi-output mean function that is parametrized via a customized deep neural network (DNN). The parameters of this mean function are estimated by minimizing a multi-component loss function that depends on the performance metric, design constraints, and the residuals on the state equations. Our TO approach yields well-defined material interfaces and has a built-in continuation nature that promotes global optimality. Other unique features of our approach include (1) its customized DNN which, unlike fully connected feed-forward DNNs, has a localized learning capacity that enables capturing intricate topologies and reducing residuals in high gradient fields, (2) its loss function that leverages localized weights to promote solution accuracy around interfaces, and (3) its use of curriculum training to avoid local optimality.To demonstrate the power of our framework, we validate it against commercial TO package COMSOL on three problems involving dissipated power minimization in Stokes flow.
Constrained multi-fidelity Bayesian optimization with automatic stop condition
Mar 03, 2025Bayesian optimization (BO) is increasingly employed in critical applications to find the optimal design with minimal cost. While BO is known for its sample efficiency, relying solely on costly high-fidelity data can still result in high costs. This is especially the case in constrained search spaces where BO must not only optimize but also ensure feasibility. A related issue in the BO literature is the lack of a systematic stopping criterion. To solve these challenges, we develop a constrained cost-aware multi-fidelity BO (CMFBO) framework whose goal is to minimize overall sampling costs by utilizing inexpensive low-fidelity sources while ensuring feasibility. In our case, the constraints can change across the data sources and may be even black-box functions. We also introduce a systematic stopping criterion that addresses the long-lasting issue associated with BO's convergence assessment. Our framework is publicly available on GitHub through the GP+ Python package and herein we validate it's efficacy on multiple benchmark problems.
Operator Learning with Gaussian Processes
Sep 06, 2024


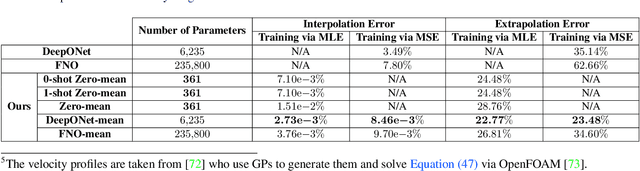
Operator learning focuses on approximating mappings $\mathcal{G}^\dagger:\mathcal{U} \rightarrow\mathcal{V}$ between infinite-dimensional spaces of functions, such as $u: \Omega_u\rightarrow\mathbb{R}$ and $v: \Omega_v\rightarrow\mathbb{R}$. This makes it particularly suitable for solving parametric nonlinear partial differential equations (PDEs). While most machine learning methods for operator learning rely on variants of deep neural networks (NNs), recent studies have shown that Gaussian Processes (GPs) are also competitive while offering interpretability and theoretical guarantees. In this paper, we introduce a hybrid GP/NN-based framework for operator learning that leverages the strengths of both methods. Instead of approximating the function-valued operator $\mathcal{G}^\dagger$, we use a GP to approximate its associated real-valued bilinear form $\widetilde{\mathcal{G}}^\dagger: \mathcal{U}\times\mathcal{V}^*\rightarrow\mathbb{R}.$ This bilinear form is defined by $\widetilde{\mathcal{G}}^\dagger(u,\varphi) := [\varphi,\mathcal{G}^\dagger(u)],$ which allows us to recover the operator $\mathcal{G}^\dagger$ through $\mathcal{G}^\dagger(u)(y)=\widetilde{\mathcal{G}}^\dagger(u,\delta_y).$ The GP mean function can be zero or parameterized by a neural operator and for each setting we develop a robust training mechanism based on maximum likelihood estimation (MLE) that can optionally leverage the physics involved. Numerical benchmarks show that (1) it improves the performance of a base neural operator by using it as the mean function of a GP, and (2) it enables zero-shot data-driven models for accurate predictions without prior training. Our framework also handles multi-output operators where $\mathcal{G}^\dagger:\mathcal{U} \rightarrow\prod_{s=1}^S\mathcal{V}^s$, and benefits from computational speed-ups via product kernel structures and Kronecker product matrix representations.
Unveiling Processing--Property Relationships in Laser Powder Bed Fusion: The Synergy of Machine Learning and High-throughput Experiments
Aug 30, 2024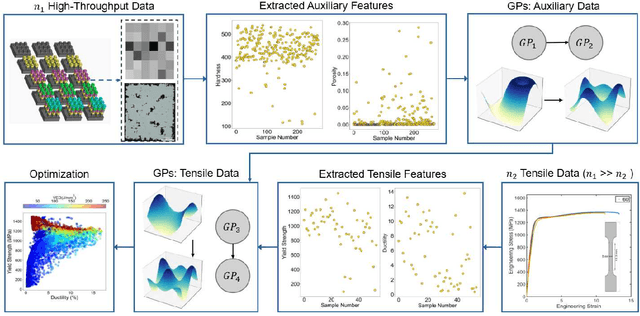
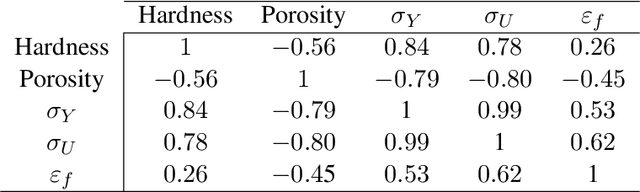
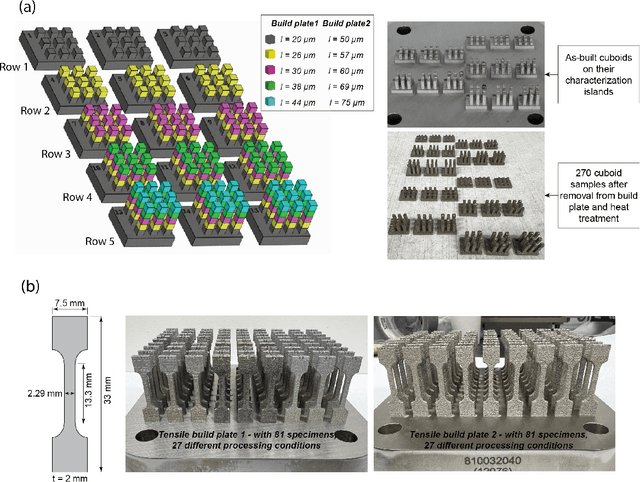

Achieving desired mechanical properties in additive manufacturing requires many experiments and a well-defined design framework becomes crucial in reducing trials and conserving resources. Here, we propose a methodology embracing the synergy between high-throughput (HT) experimentation and hierarchical machine learning (ML) to unveil the complex relationships between a large set of process parameters in Laser Powder Bed Fusion (LPBF) and selected mechanical properties (tensile strength and ductility). The HT method envisions the fabrication of small samples for rapid automated hardness and porosity characterization, and a smaller set of tensile specimens for more labor-intensive direct measurement of yield strength and ductility. The ML approach is based on a sequential application of Gaussian processes (GPs) where the correlations between process parameters and hardness/porosity are first learnt and subsequently adopted by the GPs that relate strength and ductility to process parameters. Finally, an optimization scheme is devised that leverages these GPs to identify the processing parameters that maximize combinations of strength and ductility. By founding the learning on larger easy-to-collect and smaller labor-intensive data, we reduce the reliance on expensive characterization and enable exploration of a large processing space. Our approach is material-agnostic and herein we demonstrate its application on 17-4PH stainless steel.
Simultaneous and Meshfree Topology Optimization with Physics-informed Gaussian Processes
Aug 07, 2024Topology optimization (TO) provides a principled mathematical approach for optimizing the performance of a structure by designing its material spatial distribution in a pre-defined domain and subject to a set of constraints. The majority of existing TO approaches leverage numerical solvers for design evaluations during the optimization and hence have a nested nature and rely on discretizing the design variables. Contrary to these approaches, herein we develop a new class of TO methods based on the framework of Gaussian processes (GPs) whose mean functions are parameterized via deep neural networks. Specifically, we place GP priors on all design and state variables to represent them via parameterized continuous functions. These GPs share a deep neural network as their mean function but have as many independent kernels as there are state and design variables. We estimate all the parameters of our model in a single for loop that optimizes a penalized version of the performance metric where the penalty terms correspond to the state equations and design constraints. Attractive features of our approach include $(1)$ having a built-in continuation nature since the performance metric is optimized at the same time that the state equations are solved, and $(2)$ being discretization-invariant and accommodating complex domains and topologies. To test our method against conventional TO approaches implemented in commercial software, we evaluate it on four problems involving the minimization of dissipated power in Stokes flow. The results indicate that our approach does not need filtering techniques, has consistent computational costs, and is highly robust against random initializations and problem setup.
Parametric Encoding with Attention and Convolution Mitigate Spectral Bias of Neural Partial Differential Equation Solvers
Mar 22, 2024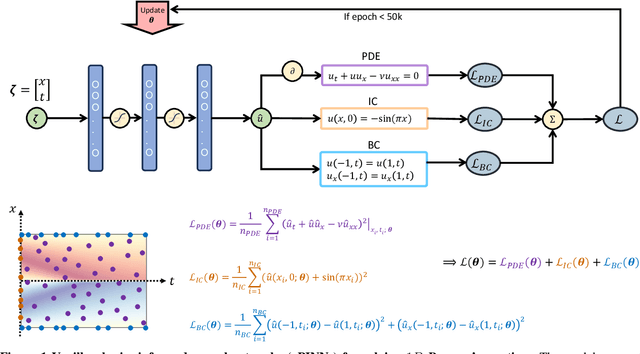
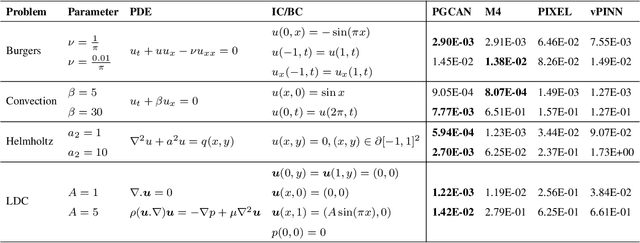
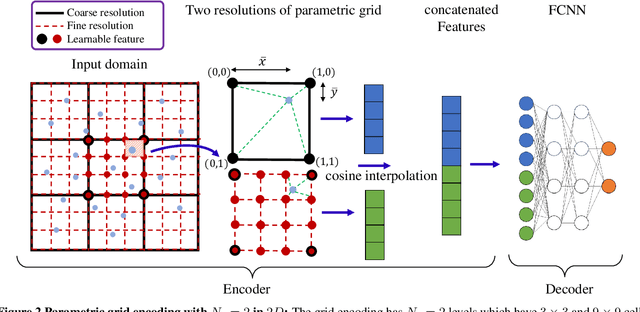
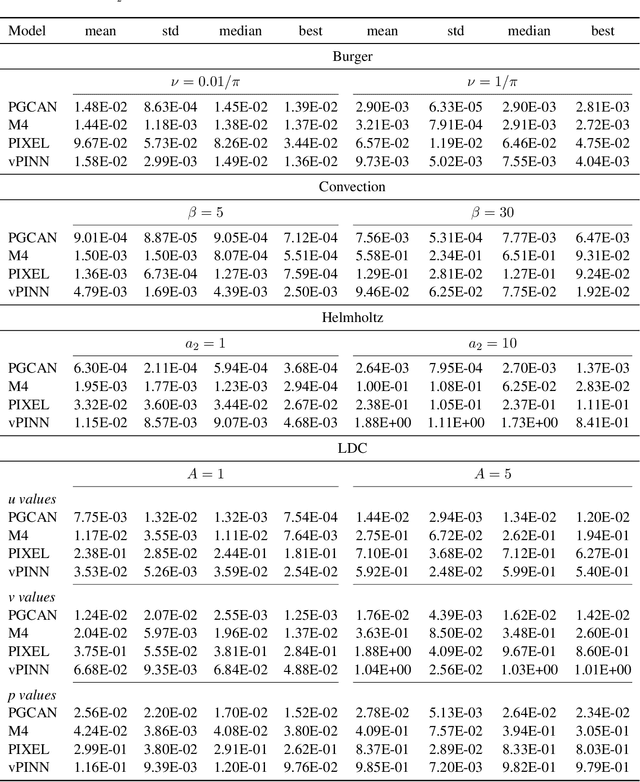
Deep neural networks (DNNs) are increasingly used to solve partial differential equations (PDEs) that naturally arise while modeling a wide range of systems and physical phenomena. However, the accuracy of such DNNs decreases as the PDE complexity increases and they also suffer from spectral bias as they tend to learn the low-frequency solution characteristics. To address these issues, we introduce Parametric Grid Convolutional Attention Networks (PGCANs) that can solve PDE systems without leveraging any labeled data in the domain. The main idea of PGCAN is to parameterize the input space with a grid-based encoder whose parameters are connected to the output via a DNN decoder that leverages attention to prioritize feature training. Our encoder provides a localized learning ability and uses convolution layers to avoid overfitting and improve information propagation rate from the boundaries to the interior of the domain. We test the performance of PGCAN on a wide range of PDE systems and show that it effectively addresses spectral bias and provides more accurate solutions compared to competing methods.
Neural Networks with Kernel-Weighted Corrective Residuals for Solving Partial Differential Equations
Jan 07, 2024Physics-informed machine learning (PIML) has emerged as a promising alternative to conventional numerical methods for solving partial differential equations (PDEs). PIML models are increasingly built via deep neural networks (NNs) whose architecture and training process are designed such that the network satisfies the PDE system. While such PIML models have substantially advanced over the past few years, their performance is still very sensitive to the NN's architecture and loss function. Motivated by this limitation, we introduce kernel-weighted Corrective Residuals (CoRes) to integrate the strengths of kernel methods and deep NNs for solving nonlinear PDE systems. To achieve this integration, we design a modular and robust framework which consistently outperforms competing methods in solving a broad range of benchmark problems. This performance improvement has a theoretical justification and is particularly attractive since we simplify the training process while negligibly increasing the inference costs. Additionally, our studies on solving multiple PDEs indicate that kernel-weighted CoRes considerably decrease the sensitivity of NNs to factors such as random initialization, architecture type, and choice of optimizer. We believe our findings have the potential to spark a renewed interest in leveraging kernel methods for solving PDEs.