 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGym: A Framework for A/B Test Simulation in E-Commerce with Traffic-Grounded VLM Agents
May 19, 2026A/B testing remains the gold standard for evaluating modifications to e-commerce storefronts, yet it diverts traffic, requires weeks to reach statistical significance, and risks degrading user experience. We present SimGym, a framework for simulating A/B tests on e-commerce storefronts using vision-language model (VLM) agents operating in a live browser. The framework comprises three key components: (a) a traffic-grounded persona generation pipeline that derives per-shop buyer archetypes and intents from production clickstream data; (b) a live-browser agent architecture that combines multimodal perception over visual and browser-structured observations with episodic memory and guardrails to conduct coherent shopping sessions across control and treatment storefronts; and (c) an evaluation protocol that compares simulated outcome shifts with observed shifts in real buyer behavior. We validate SimGym on A/B tests of visually driven UI theme changes from a major e-commerce platform across diverse storefronts and product categories. Empirical results show that SimGym agents achieve strong agreement with observed outcome shifts, attaining 77% directional alignment with add-to-cart shifts observed across interface variants in real-buyer traffic. It reduces experimental cycles from weeks to under an hour, enabling rapid experimentation without exposing real buyers to candidate variants.
SimPersona: Learning Discrete Buyer Personas from Raw Clickstreams for Grounded E-Commerce Agents
May 14, 2026LLM-based web agents can navigate live storefronts, yet they often collapse to a single "average buyer" policy, failing to capture the heterogeneous and distributional nature of real buyer populations. Existing personalization methods rely on hand-crafted prompt-based personas that are brittle, difficult to scale, context-inefficient, and unable to faithfully represent population-level behavior. We introduce SimPersona, a novel framework that learns discrete buyer types from historical traffic and exposes them to LLM-based web agents as compact persona tokens. Given raw clickstreams, a behavior-aware VQ-VAE induces a discrete buyer-type space that captures the statistical structure of real buyer behavior and merchant-specific buyer population distributions. To provide behavior-specific guidance to LLM-based web agents, SimPersona maps each learned buyer type to a dedicated persona token in the LLM agent vocabulary and fine-tunes the agent with these tokens on real browsing traces. At inference, each synthetic buyer is assigned to a learned buyer type with a single encoder forward pass, requiring no retraining or store-specific prompt engineering. For population-level simulation, SimPersona samples buyer types from each merchant's empirical distribution over the learned VQ-VAE codebook and instantiates agents with the corresponding persona tokens, preserving merchant-specific buyer population distributions. Evaluated on $8.37$M buyers across $42$ held-out live storefronts, SimPersona achieves $78\%$ conversion-rate alignment with real buyers, exhibits interpretable behavioral variation across buyer types, and outperforms a baseline with $8\times$ more parameters on goal-oriented shopping tasks. We further release an open-source data pipeline that converts raw e-commerce event logs into buyer representations and agent-training traces.
SimGym: Traffic-Grounded Browser Agents for Offline A/B Testing in E-Commerce
Feb 01, 2026A/B testing remains the gold standard for evaluating e-commerce UI changes, yet it diverts traffic, takes weeks to reach significance, and risks harming user experience. We introduce SimGym, a scalable system for rapid offline A/B testing using traffic-grounded synthetic buyers powered by Large Language Model agents operating in a live browser. SimGym extracts per-shop buyer profiles and intents from production interaction data, identifies distinct behavioral archetypes, and simulates cohort-weighted sessions across control and treatment storefronts. We validate SimGym against real human outcomes from real UI changes on a major e-commerce platform under confounder control. Even without alignment post training, SimGym agents achieve state of the art alignment with observed outcome shifts and reduces experiment cycles from weeks to under an hour , enabling rapid experimentation without exposure to real buyers.
A preliminary data fusion study to assess the feasibility of Foundation Process-Property Models in Laser Powder Bed Fusion
Mar 20, 2025Foundation models are at the forefront of an increasing number of critical applications. In regards to technologies such as additive manufacturing (AM), these models have the potential to dramatically accelerate process optimization and, in turn, design of next generation materials. A major challenge that impedes the construction of foundation process-property models is data scarcity. To understand the impact of this challenge, and since foundation models rely on data fusion, in this work we conduct controlled experiments where we focus on the transferability of information across different material systems and properties. More specifically, we generate experimental datasets from 17-4 PH and 316L stainless steels (SSs) in Laser Powder Bed Fusion (LPBF) where we measure the effect of five process parameters on porosity and hardness. We then leverage Gaussian processes (GPs) for process-property modeling in various configurations to test if knowledge about one material system or property can be leveraged to build more accurate machine learning models for other material systems or properties. Through extensive cross-validation studies and probing the GPs' interpretable hyperparameters, we study the intricate relation among data size and dimensionality, complexity of the process-property relations, noise, and characteristics of machine learning models. Our findings highlight the need for structured learning approaches that incorporate domain knowledge in building foundation process-property models rather than relying on uninformed data fusion in data-limited applications.
Constrained multi-fidelity Bayesian optimization with automatic stop condition
Mar 03, 2025Bayesian optimization (BO) is increasingly employed in critical applications to find the optimal design with minimal cost. While BO is known for its sample efficiency, relying solely on costly high-fidelity data can still result in high costs. This is especially the case in constrained search spaces where BO must not only optimize but also ensure feasibility. A related issue in the BO literature is the lack of a systematic stopping criterion. To solve these challenges, we develop a constrained cost-aware multi-fidelity BO (CMFBO) framework whose goal is to minimize overall sampling costs by utilizing inexpensive low-fidelity sources while ensuring feasibility. In our case, the constraints can change across the data sources and may be even black-box functions. We also introduce a systematic stopping criterion that addresses the long-lasting issue associated with BO's convergence assessment. Our framework is publicly available on GitHub through the GP+ Python package and herein we validate it's efficacy on multiple benchmark problems.
Unveiling Processing--Property Relationships in Laser Powder Bed Fusion: The Synergy of Machine Learning and High-throughput Experiments
Aug 30, 2024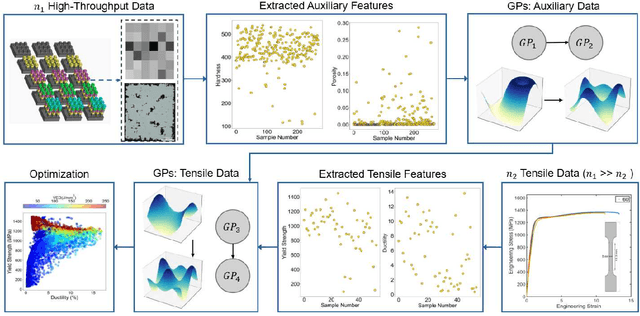
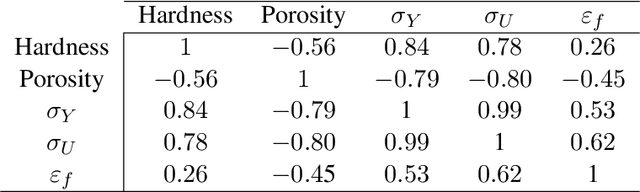
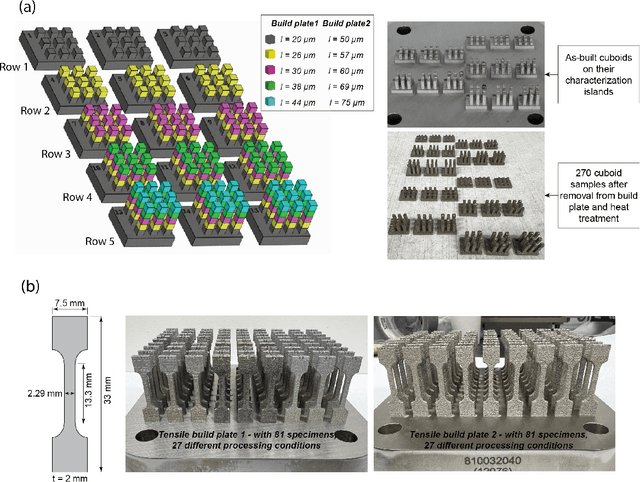

Achieving desired mechanical properties in additive manufacturing requires many experiments and a well-defined design framework becomes crucial in reducing trials and conserving resources. Here, we propose a methodology embracing the synergy between high-throughput (HT) experimentation and hierarchical machine learning (ML) to unveil the complex relationships between a large set of process parameters in Laser Powder Bed Fusion (LPBF) and selected mechanical properties (tensile strength and ductility). The HT method envisions the fabrication of small samples for rapid automated hardness and porosity characterization, and a smaller set of tensile specimens for more labor-intensive direct measurement of yield strength and ductility. The ML approach is based on a sequential application of Gaussian processes (GPs) where the correlations between process parameters and hardness/porosity are first learnt and subsequently adopted by the GPs that relate strength and ductility to process parameters. Finally, an optimization scheme is devised that leverages these GPs to identify the processing parameters that maximize combinations of strength and ductility. By founding the learning on larger easy-to-collect and smaller labor-intensive data, we reduce the reliance on expensive characterization and enable exploration of a large processing space. Our approach is material-agnostic and herein we demonstrate its application on 17-4PH stainless steel.
GP+: A Python Library for Kernel-based learning via Gaussian Processes
Dec 12, 2023In this paper we introduce GP+, an open-source library for kernel-based learning via Gaussian processes (GPs) which are powerful statistical models that are completely characterized by their parametric covariance and mean functions. GP+ is built on PyTorch and provides a user-friendly and object-oriented tool for probabilistic learning and inference. As we demonstrate with a host of examples, GP+ has a few unique advantages over other GP modeling libraries. We achieve these advantages primarily by integrating nonlinear manifold learning techniques with GPs' covariance and mean functions. As part of introducing GP+, in this paper we also make methodological contributions that (1) enable probabilistic data fusion and inverse parameter estimation, and (2) equip GPs with parsimonious parametric mean functions which span mixed feature spaces that have both categorical and quantitative variables. We demonstrate the impact of these contributions in the context of Bayesian optimization, multi-fidelity modeling, sensitivity analysis, and calibration of computer models.
On the Effects of Heterogeneous Errors on Multi-fidelity Bayesian Optimization
Sep 06, 2023Bayesian optimization (BO) is a sequential optimization strategy that is increasingly employed in a wide range of areas including materials design. In real world applications, acquiring high-fidelity (HF) data through physical experiments or HF simulations is the major cost component of BO. To alleviate this bottleneck, multi-fidelity (MF) methods are used to forgo the sole reliance on the expensive HF data and reduce the sampling costs by querying inexpensive low-fidelity (LF) sources whose data are correlated with HF samples. However, existing multi-fidelity BO (MFBO) methods operate under the following two assumptions that rarely hold in practical applications: (1) LF sources provide data that are well correlated with the HF data on a global scale, and (2) a single random process can model the noise in the fused data. These assumptions dramatically reduce the performance of MFBO when LF sources are only locally correlated with the HF source or when the noise variance varies across the data sources. In this paper, we dispense with these incorrect assumptions by proposing an MF emulation method that (1) learns a noise model for each data source, and (2) enables MFBO to leverage highly biased LF sources which are only locally correlated with the HF source. We illustrate the performance of our method through analytical examples and engineering problems on materials design.
Unsupervised Anomaly Detection via Nonlinear Manifold Learning
Jun 15, 2023Anomalies are samples that significantly deviate from the rest of the data and their detection plays a major role in building machine learning models that can be reliably used in applications such as data-driven design and novelty detection. The majority of existing anomaly detection methods either are exclusively developed for (semi) supervised settings, or provide poor performance in unsupervised applications where there is no training data with labeled anomalous samples. To bridge this research gap, we introduce a robust, efficient, and interpretable methodology based on nonlinear manifold learning to detect anomalies in unsupervised settings. The essence of our approach is to learn a low-dimensional and interpretable latent representation (aka manifold) for all the data points such that normal samples are automatically clustered together and hence can be easily and robustly identified. We learn this low-dimensional manifold by designing a learning algorithm that leverages either a latent map Gaussian process (LMGP) or a deep autoencoder (AE). Our LMGP-based approach, in particular, provides a probabilistic perspective on the learning task and is ideal for high-dimensional applications with scarce data. We demonstrate the superior performance of our approach over existing technologies via multiple analytic examples and real-world datasets.
Multi-Fidelity Cost-Aware Bayesian Optimization
Nov 04, 2022Bayesian optimization (BO) is increasingly employed in critical applications such as materials design and drug discovery. An increasingly popular strategy in BO is to forgo the sole reliance on high-fidelity data and instead use an ensemble of information sources which provide inexpensive low-fidelity data. The overall premise of this strategy is to reduce the overall sampling costs by querying inexpensive low-fidelity sources whose data are correlated with high-fidelity samples. Here, we propose a multi-fidelity cost-aware BO framework that dramatically outperforms the state-of-the-art technologies in terms of efficiency, consistency, and robustness. We demonstrate the advantages of our framework on analytic and engineering problems and argue that these benefits stem from our two main contributions: (1) we develop a novel acquisition function for multi-fidelity cost-aware BO that safeguards the convergence against the biases of low-fidelity data, and (2) we tailor a newly developed emulator for multi-fidelity BO which enables us to not only simultaneously learn from an ensemble of multi-fidelity datasets, but also identify the severely biased low-fidelity sources that should be excluded from BO.