 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator Learning with Gaussian Processes
Paper and Code
Sep 06, 2024


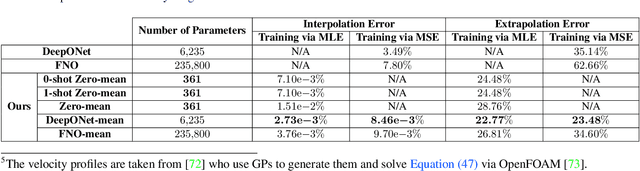
Operator learning focuses on approximating mappings $\mathcal{G}^\dagger:\mathcal{U} \rightarrow\mathcal{V}$ between infinite-dimensional spaces of functions, such as $u: \Omega_u\rightarrow\mathbb{R}$ and $v: \Omega_v\rightarrow\mathbb{R}$. This makes it particularly suitable for solving parametric nonlinear partial differential equations (PDEs). While most machine learning methods for operator learning rely on variants of deep neural networks (NNs), recent studies have shown that Gaussian Processes (GPs) are also competitive while offering interpretability and theoretical guarantees. In this paper, we introduce a hybrid GP/NN-based framework for operator learning that leverages the strengths of both methods. Instead of approximating the function-valued operator $\mathcal{G}^\dagger$, we use a GP to approximate its associated real-valued bilinear form $\widetilde{\mathcal{G}}^\dagger: \mathcal{U}\times\mathcal{V}^*\rightarrow\mathbb{R}.$ This bilinear form is defined by $\widetilde{\mathcal{G}}^\dagger(u,\varphi) := [\varphi,\mathcal{G}^\dagger(u)],$ which allows us to recover the operator $\mathcal{G}^\dagger$ through $\mathcal{G}^\dagger(u)(y)=\widetilde{\mathcal{G}}^\dagger(u,\delta_y).$ The GP mean function can be zero or parameterized by a neural operator and for each setting we develop a robust training mechanism based on maximum likelihood estimation (MLE) that can optionally leverage the physics involved. Numerical benchmarks show that (1) it improves the performance of a base neural operator by using it as the mean function of a GP, and (2) it enables zero-shot data-driven models for accurate predictions without prior training. Our framework also handles multi-output operators where $\mathcal{G}^\dagger:\mathcal{U} \rightarrow\prod_{s=1}^S\mathcal{V}^s$, and benefits from computational speed-ups via product kernel structures and Kronecker product matrix representations.