 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Assisted Stitching for Offline Hierarchical Reinforcement Learning
Jun 09, 2025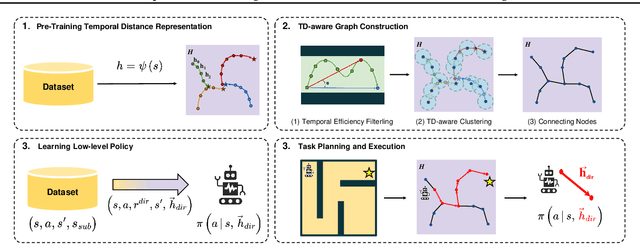
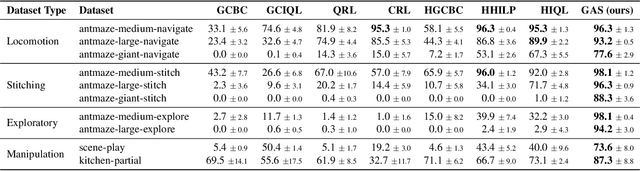
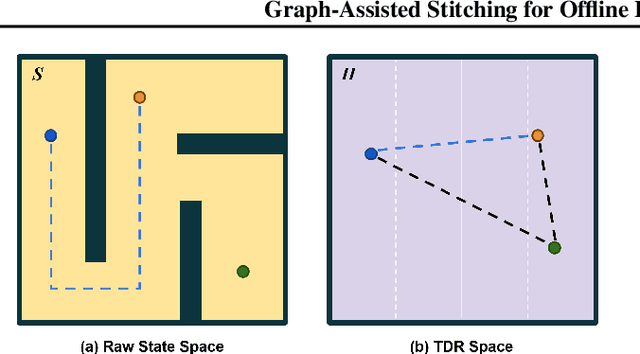
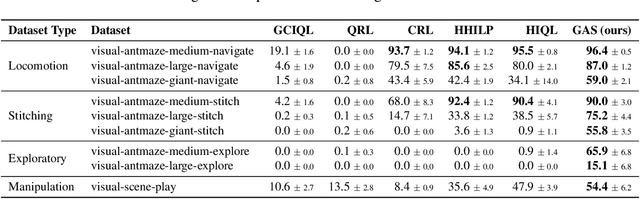
Existing offline hierarchical reinforcement learning methods rely on high-level policy learning to generate subgoal sequences. However, their efficiency degrades as task horizons increase, and they lack effective strategies for stitching useful state transitions across different trajectories. We propose Graph-Assisted Stitching (GAS), a novel framework that formulates subgoal selection as a graph search problem rather than learning an explicit high-level policy. By embedding states into a Temporal Distance Representation (TDR) space, GAS clusters semantically similar states from different trajectories into unified graph nodes, enabling efficient transition stitching. A shortest-path algorithm is then applied to select subgoal sequences within the graph, while a low-level policy learns to reach the subgoals. To improve graph quality, we introduce the Temporal Efficiency (TE) metric, which filters out noisy or inefficient transition states, significantly enhancing task performance. GAS outperforms prior offline HRL methods across locomotion, navigation, and manipulation tasks. Notably, in the most stitching-critical task, it achieves a score of 88.3, dramatically surpassing the previous state-of-the-art score of 1.0. Our source code is available at: https://github.com/qortmdgh4141/GAS.
Hybrid 3D-4D Gaussian Splatting for Fast Dynamic Scene Representation
May 19, 2025Recent advancements in dynamic 3D scene reconstruction have shown promising results, enabling high-fidelity 3D novel view synthesis with improved temporal consistency. Among these, 4D Gaussian Splatting (4DGS) has emerged as an appealing approach due to its ability to model high-fidelity spatial and temporal variations. However, existing methods suffer from substantial computational and memory overhead due to the redundant allocation of 4D Gaussians to static regions, which can also degrade image quality. In this work, we introduce hybrid 3D-4D Gaussian Splatting (3D-4DGS), a novel framework that adaptively represents static regions with 3D Gaussians while reserving 4D Gaussians for dynamic elements. Our method begins with a fully 4D Gaussian representation and iteratively converts temporally invariant Gaussians into 3D, significantly reducing the number of parameters and improving computational efficiency. Meanwhile, dynamic Gaussians retain their full 4D representation, capturing complex motions with high fidelity. Our approach achieves significantly faster training times compared to baseline 4D Gaussian Splatting methods while maintaining or improving the visual quality.
Better Think with Tables: Leveraging Tables to Enhance Large Language Model Comprehension
Dec 22, 2024



Despite the recent advancement of Large Langauge Models (LLMs), they struggle with complex queries often involving multiple conditions, common in real-world scenarios. We propose Thinking with Tables, a technique that assists LLMs to leverage tables for intermediate thinking aligning with human cognitive behavior. By introducing a pre-instruction that triggers an LLM to organize information in tables, our approach achieves a 40.29\% average relative performance increase, higher robustness, and show generalizability to different requests, conditions, or scenarios. We additionally show the influence of data structuredness for the model by comparing results from four distinct structuring levels that we introduce.
Generative Densification: Learning to Densify Gaussians for High-Fidelity Generalizable 3D Reconstruction
Dec 09, 2024



Generalized feed-forward Gaussian models have achieved significant progress in sparse-view 3D reconstruction by leveraging prior knowledge from large multi-view datasets. However, these models often struggle to represent high-frequency details due to the limited number of Gaussians. While the densification strategy used in per-scene 3D Gaussian splatting (3D-GS) optimization can be adapted to the feed-forward models, it may not be ideally suited for generalized scenarios. In this paper, we propose Generative Densification, an efficient and generalizable method to densify Gaussians generated by feed-forward models. Unlike the 3D-GS densification strategy, which iteratively splits and clones raw Gaussian parameters, our method up-samples feature representations from the feed-forward models and generates their corresponding fine Gaussians in a single forward pass, leveraging the embedded prior knowledge for enhanced generalization. Experimental results on both object-level and scene-level reconstruction tasks demonstrate that our method outperforms state-of-the-art approaches with comparable or smaller model sizes, achieving notable improvements in representing fine details.
Parameter-Efficient Instance-Adaptive Neural Video Compression
May 14, 2024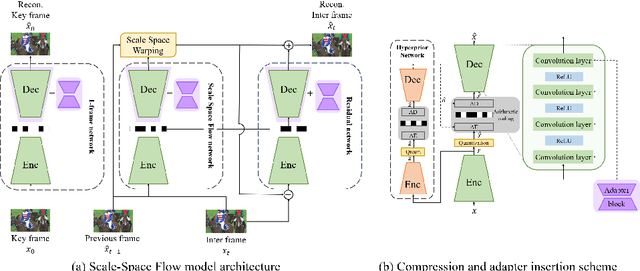

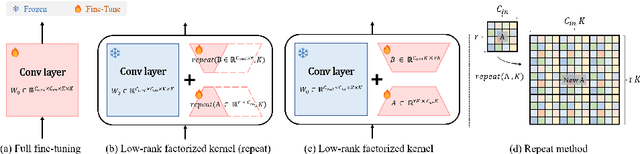

Learning-based Neural Video Codecs (NVCs) have emerged as a compelling alternative to the standard video codecs, demonstrating promising performance, and simple and easily maintainable pipelines. However, NVCs often fall short of compression performance and occasionally exhibit poor generalization capability due to inference-only compression scheme and their dependence on training data. The instance-adaptive video compression techniques have recently been suggested as a viable solution, fine-tuning the encoder or decoder networks for a particular test instance video. However, fine-tuning all the model parameters incurs high computational costs, increases the bitrates, and often leads to unstable training. In this work, we propose a parameter-efficient instance-adaptive video compression framework. Inspired by the remarkable success of parameter-efficient fine-tuning on large-scale neural network models, we propose to use a lightweight adapter module that can be easily attached to the pretrained NVCs and fine-tuned for test video sequences. The resulting algorithm significantly improves compression performance and reduces the encoding time compared to the existing instant-adaptive video compression algorithms. Furthermore, the suggested fine-tuning method enhances the robustness of the training process, allowing for the proposed method to be widely used in many practical settings. We conducted extensive experiments on various standard benchmark datasets, including UVG, MCL-JVC, and HEVC sequences, and the experimental results have shown a significant improvement in rate-distortion (RD) curves (up to 5 dB PSNR improvements) and BD rates compared to the baselines NVC.