 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Think with Tables: Leveraging Tables to Enhance Large Language Model Comprehension
Dec 22, 2024



Despite the recent advancement of Large Langauge Models (LLMs), they struggle with complex queries often involving multiple conditions, common in real-world scenarios. We propose Thinking with Tables, a technique that assists LLMs to leverage tables for intermediate thinking aligning with human cognitive behavior. By introducing a pre-instruction that triggers an LLM to organize information in tables, our approach achieves a 40.29\% average relative performance increase, higher robustness, and show generalizability to different requests, conditions, or scenarios. We additionally show the influence of data structuredness for the model by comparing results from four distinct structuring levels that we introduce.
PFGuard: A Generative Framework with Privacy and Fairness Safeguards
Oct 03, 2024



Generative models must ensure both privacy and fairness for Trustworthy AI. While these goals have been pursued separately, recent studies propose to combine existing privacy and fairness techniques to achieve both goals. However, naively combining these techniques can be insufficient due to privacy-fairness conflicts, where a sample in a minority group may be amplified for fairness, only to be suppressed for privacy. We demonstrate how these conflicts lead to adverse effects, such as privacy violations and unexpected fairness-utility tradeoffs. To mitigate these risks, we propose PFGuard, a generative framework with privacy and fairness safeguards, which simultaneously addresses privacy, fairness, and utility. By using an ensemble of multiple teacher models, PFGuard balances privacy-fairness conflicts between fair and private training stages and achieves high utility based on ensemble learning. Extensive experiments show that PFGuard successfully generates synthetic data on high-dimensional data while providing both fairness convergence and strict DP guarantees - the first of its kind to our knowledge.
Personalized DP-SGD using Sampling Mechanisms
May 24, 2023



Personalized privacy becomes critical in deep learning for Trustworthy AI. While Differentially Private Stochastic Gradient Descent (DP-SGD) is widely used in deep learning methods supporting privacy, it provides the same level of privacy to all individuals, which may lead to overprotection and low utility. In practice, different users may require different privacy levels, and the model can be improved by using more information about the users with lower privacy requirements. There are also recent works on differential privacy of individuals when using DP-SGD, but they are mostly about individual privacy accounting and do not focus on satisfying different privacy levels. We thus extend DP-SGD to support a recent privacy notion called ($\Phi$,$\Delta$)-Personalized Differential Privacy (($\Phi$,$\Delta$)-PDP), which extends an existing PDP concept called $\Phi$-PDP. Our algorithm uses a multi-round personalized sampling mechanism and embeds it within the DP-SGD iterations. Experiments on real datasets show that our algorithm outperforms DP-SGD and simple combinations of DP-SGD with existing PDP mechanisms in terms of model performance and efficiency due to its embedded sampling mechanism.
Redactor: Targeted Disinformation Generation using Probabilistic Decision Boundaries
Feb 07, 2022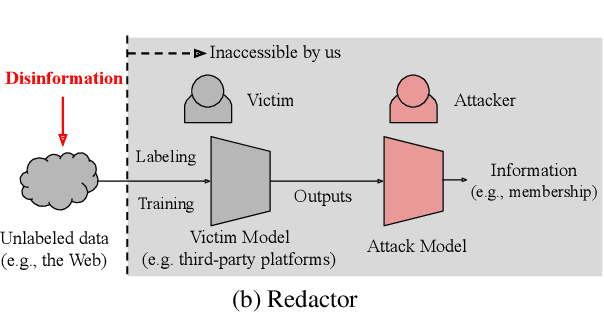

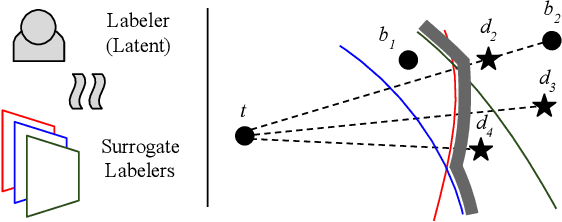
Information leakage is becoming a critical problem as various information becomes publicly available by mistake, and machine learning models train on that data to provide services. As a result, one's private information could easily be memorized by such trained models. Unfortunately, deleting information is out of the question as the data is already exposed to the Web or third-party platforms. Moreover, we cannot necessarily control the labeling process and the model trainings by other parties either. In this setting, we study the problem of targeted disinformation where the goal is to lower the accuracy of inference attacks on a specific target (e.g., a person's profile) only using data insertion. While our problem is related to data privacy and defenses against exploratory attacks, our techniques are inspired by targeted data poisoning attacks with some key differences. We show that our problem is best solved by finding the closest points to the target in the input space that will be labeled as a different class. Since we do not control the labeling process, we instead conservatively estimate the labels probabilistically by combining decision boundaries of multiple classifiers using data programming techniques. We also propose techniques for making the disinformation realistic. Our experiments show that a probabilistic decision boundary can be a good proxy for labelers, and that our approach outperforms other targeted poisoning methods when using end-to-end training on real datasets.
Responsible AI Challenges in End-to-end Machine Learning
Jan 15, 2021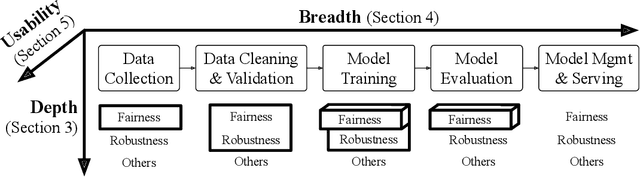
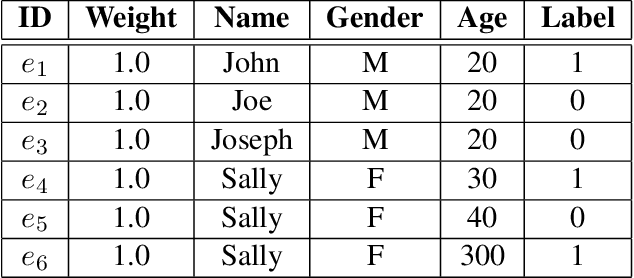
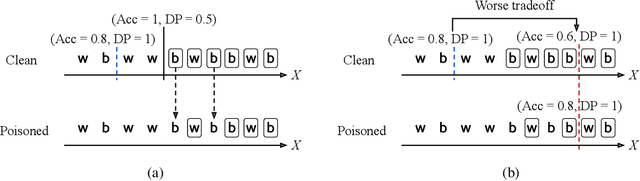
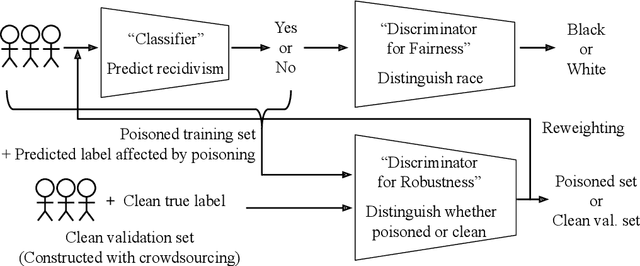
Responsible AI is becoming critical as AI is widely used in our everyday lives. Many companies that deploy AI publicly state that when training a model, we not only need to improve its accuracy, but also need to guarantee that the model does not discriminate against users (fairness), is resilient to noisy or poisoned data (robustness), is explainable, and more. In addition, these objectives are not only relevant to model training, but to all steps of end-to-end machine learning, which include data collection, data cleaning and validation, model training, model evaluation, and model management and serving. Finally, responsible AI is conceptually challenging, and supporting all the objectives must be as easy as possible. We thus propose three key research directions towards this vision - depth, breadth, and usability - to measure progress and introduce our ongoing research. First, responsible AI must be deeply supported where multiple objectives like fairness and robust must be handled together. To this end, we propose FR-Train, a holistic framework for fair and robust model training in the presence of data bias and poisoning. Second, responsible AI must be broadly supported, preferably in all steps of machine learning. Currently we focus on the data pre-processing steps and propose Slice Tuner, a selective data acquisition framework for training fair and accurate models, and MLClean, a data cleaning framework that also improves fairness and robustness. Finally, responsible AI must be usable where the techniques must be easy to deploy and actionable. We propose FairBatch, a batch selection approach for fairness that is effective and simple to use, and Slice Finder, a model evaluation tool that automatically finds problematic slices. We believe we scratched the surface of responsible AI for end-to-end machine learning and suggest research challenges moving forward.
Inspector Gadget: A Data Programming-based Labeling System for Industrial Images
Apr 07, 2020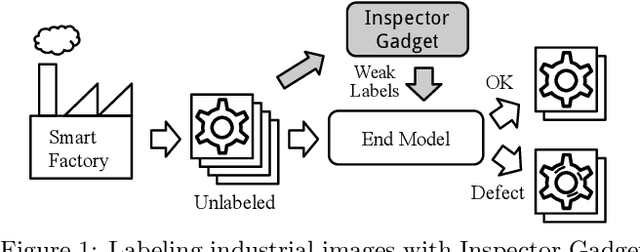
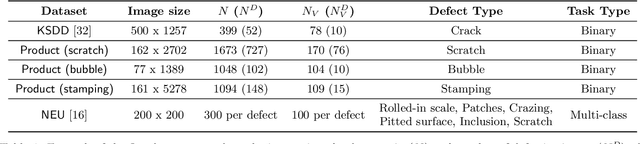
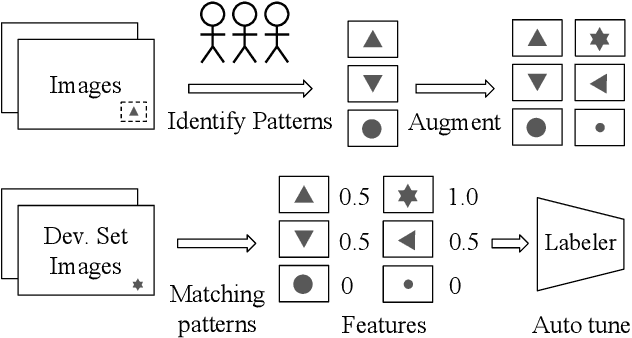
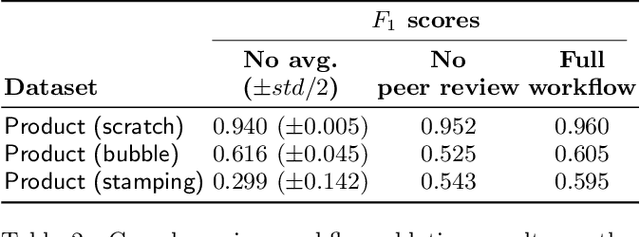
As machine learning for images becomes democratized in the Software 2.0 era, one of the serious bottlenecks is securing enough labeled data for training. This problem is especially critical in a manufacturing setting where smart factories rely on machine learning for product quality control by analyzing industrial images. Such images are typically large and may only need to be partially analyzed where only a small portion is problematic (e.g., identifying defects on a surface). Since manual labeling these images is expensive, weak supervision is an attractive alternative where the idea is to generate weak labels that are not perfect, but can be produced at scale. Data programming is a recent paradigm in this category where it uses human knowledge in the form of labeling functions and combines them into a generative model. Data programming has been successful in applications based on text or structured data and can also be applied to images usually if one can find a way to convert them into structured data. In this work, we expand the horizon of data programming by directly applying it to images without this conversion, which is a common scenario for industrial applications. We propose Inspector Gadget, an image labeling system that combines crowdsourcing, data augmentation, and data programming to produce weak labels at scale for image classification. We perform experiments on real industrial image datasets and show that Inspector Gadget obtains better accuracy than state-of-the-art techniques: Snuba, GOGGLES, and self-learning baselines using convolutional neural networks (CNNs) without pre-training.
A Survey on Data Collection for Machine Learning: a Big Data - AI Integration Perspective
Nov 08, 2018
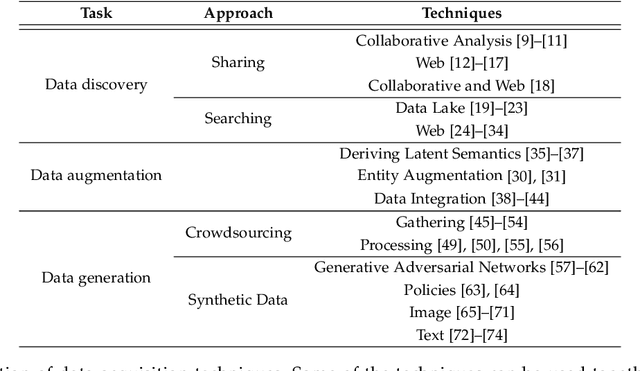

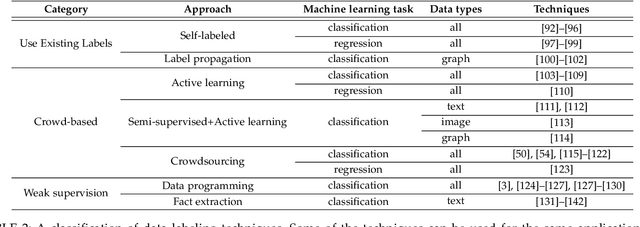
Data collection is a major bottleneck in machine learning and an active research topic in multiple communities. There are largely two reasons data collection has recently become a critical issue. First, as machine learning is becoming more widely-used, we are seeing new applications that do not necessarily have enough labeled data. Second, unlike traditional machine learning where feature engineering is the bottleneck, deep learning techniques automatically generate features, but instead require large amounts of labeled data. Interestingly, recent research in data collection comes not only from the machine learning, natural language, and computer vision communities, but also from the data management community due to the importance of handling large amounts of data. In this survey, we perform a comprehensive study of data collection from a data management point of view. Data collection largely consists of data acquisition, data labeling, and improvement of existing data or models. We provide a research landscape of these operations, provide guidelines on which technique to use when, and identify interesting research challenges. The integration of machine learning and data management for data collection is part of a larger trend of Big data and Artificial Intelligence (AI) integration and opens many opportunities for new research.