 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFrame: Debiasing Large Language Models Against Framing Effects
Feb 04, 2026As large language models (LLMs) are increasingly deployed in real-world applications, ensuring their fair responses across demographics has become crucial. Despite many efforts, an ongoing challenge is hidden bias: LLMs appear fair under standard evaluations, but can produce biased responses outside those evaluation settings. In this paper, we identify framing -- differences in how semantically equivalent prompts are expressed (e.g., "A is better than B" vs. "B is worse than A") -- as an underexplored contributor to this gap. We first introduce the concept of "framing disparity" to quantify the impact of framing on fairness evaluation. By augmenting fairness evaluation benchmarks with alternative framings, we find that (1) fairness scores vary significantly with framing and (2) existing debiasing methods improve overall (i.e., frame-averaged) fairness, but often fail to reduce framing-induced disparities. To address this, we propose a framing-aware debiasing method that encourages LLMs to be more consistent across framings. Experiments demonstrate that our approach reduces overall bias and improves robustness against framing disparities, enabling LLMs to produce fairer and more consistent responses.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Differentially Private Federated Clustering with Random Rebalancing
Aug 08, 2025Federated clustering aims to group similar clients into clusters and produce one model for each cluster. Such a personalization approach typically improves model performance compared with training a single model to serve all clients, but can be more vulnerable to privacy leakage. Directly applying client-level differentially private (DP) mechanisms to federated clustering could degrade the utilities significantly. We identify that such deficiencies are mainly due to the difficulties of averaging privacy noise within each cluster (following standard privacy mechanisms), as the number of clients assigned to the same clusters is uncontrolled. To this end, we propose a simple and effective technique, named RR-Cluster, that can be viewed as a light-weight add-on to many federated clustering algorithms. RR-Cluster achieves reduced privacy noise via randomly rebalancing cluster assignments, guaranteeing a minimum number of clients assigned to each cluster. We analyze the tradeoffs between decreased privacy noise variance and potentially increased bias from incorrect assignments and provide convergence bounds for RR-Clsuter. Empirically, we demonstrate the RR-Cluster plugged into strong federated clustering algorithms results in significantly improved privacy/utility tradeoffs across both synthetic and real-world datasets.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
NEXT-EVAL: Next Evaluation of Traditional and LLM Web Data Record Extraction
May 21, 2025Effective evaluation of web data record extraction methods is crucial, yet hampered by static, domain-specific benchmarks and opaque scoring practices. This makes fair comparison between traditional algorithmic techniques, which rely on structural heuristics, and Large Language Model (LLM)-based approaches, offering zero-shot extraction across diverse layouts, particularly challenging. To overcome these limitations, we introduce a concrete evaluation framework. Our framework systematically generates evaluation datasets from arbitrary MHTML snapshots, annotates XPath-based supervision labels, and employs structure-aware metrics for consistent scoring, specifically preventing text hallucination and allowing only for the assessment of positional hallucination. It also incorporates preprocessing strategies to optimize input for LLMs while preserving DOM semantics: HTML slimming, Hierarchical JSON, and Flat JSON. Additionally, we created a publicly available synthetic dataset by transforming DOM structures and modifying content. We benchmark deterministic heuristic algorithms and off-the-shelf LLMs across these multiple input formats. Our benchmarking shows that Flat JSON input enables LLMs to achieve superior extraction accuracy (F1 score of 0.9567) and minimal hallucination compared to other input formats like Slimmed HTML and Hierarchical JSON. We establish a standardized foundation for rigorous benchmarking, paving the way for the next principled advancements in web data record extraction.
Reasoning Models Better Express Their Confidence
May 20, 2025Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.
Explainable AI-Based Interface System for Weather Forecasting Model
Apr 01, 2025Machine learning (ML) is becoming increasingly popular in meteorological decision-making. Although the literature on explainable artificial intelligence (XAI) is growing steadily, user-centered XAI studies have not extend to this domain yet. This study defines three requirements for explanations of black-box models in meteorology through user studies: statistical model performance for different rainfall scenarios to identify model bias, model reasoning, and the confidence of model outputs. Appropriate XAI methods are mapped to each requirement, and the generated explanations are tested quantitatively and qualitatively. An XAI interface system is designed based on user feedback. The results indicate that the explanations increase decision utility and user trust. Users prefer intuitive explanations over those based on XAI algorithms even for potentially easy-to-recognize examples. These findings can provide evidence for future research on user-centered XAI algorithms, as well as a basis to improve the usability of AI systems in practice.
* 19 pages, 16 figures
Example-Based Concept Analysis Framework for Deep Weather Forecast Models
Apr 01, 2025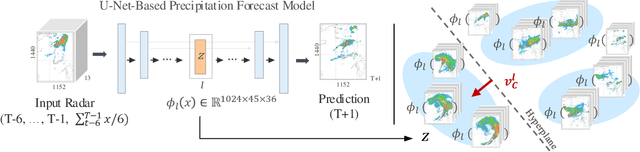
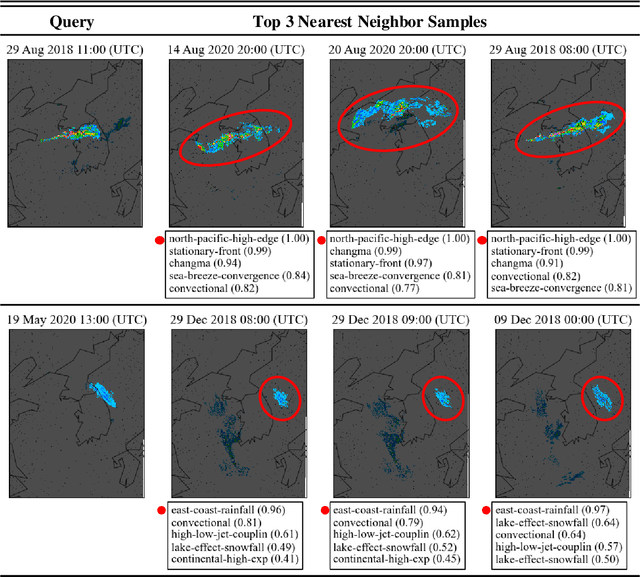
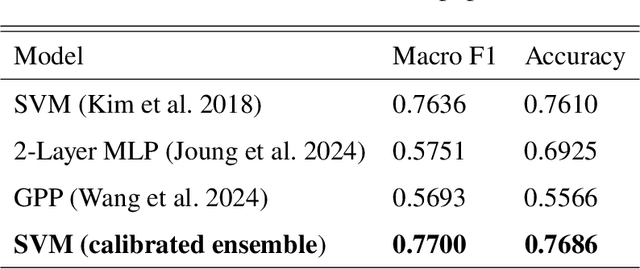
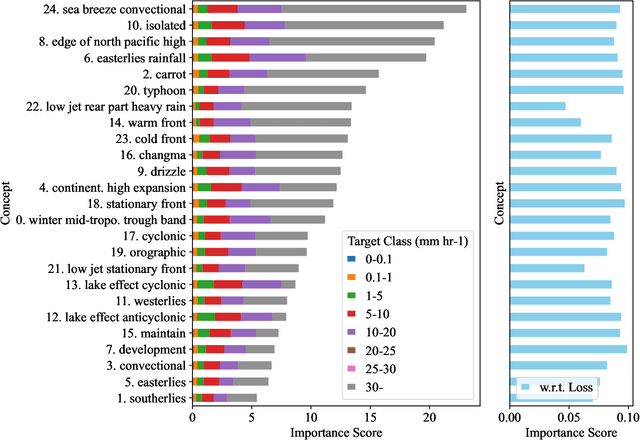
To improve the trustworthiness of an AI model, finding consistent, understandable representations of its inference process is essential. This understanding is particularly important in high-stakes operations such as weather forecasting, where the identification of underlying meteorological mechanisms is as critical as the accuracy of the predictions. Despite the growing literature that addresses this issue through explainable AI, the applicability of their solutions is often limited due to their AI-centric development. To fill this gap, we follow a user-centric process to develop an example-based concept analysis framework, which identifies cases that follow a similar inference process as the target instance in a target model and presents them in a user-comprehensible format. Our framework provides the users with visually and conceptually analogous examples, including the probability of concept assignment to resolve ambiguities in weather mechanisms. To bridge the gap between vector representations identified from models and human-understandable explanations, we compile a human-annotated concept dataset and implement a user interface to assist domain experts involved in the the framework development.
* 39 pages, 10 figures
Conditional Temporal Neural Processes with Covariance Loss
Apr 01, 2025We introduce a novel loss function, Covariance Loss, which is conceptually equivalent to conditional neural processes and has a form of regularization so that is applicable to many kinds of neural networks. With the proposed loss, mappings from input variables to target variables are highly affected by dependencies of target variables as well as mean activation and mean dependencies of input and target variables. This nature enables the resulting neural networks to become more robust to noisy observations and recapture missing dependencies from prior information. In order to show the validity of the proposed loss, we conduct extensive sets of experiments on real-world datasets with state-of-the-art models and discuss the benefits and drawbacks of the proposed Covariance Loss.
* 11 pages, 18 figures
EXAONE Deep: Reasoning Enhanced Language Models
Mar 16, 2025We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE