 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Temporal Neural Processes with Covariance Loss
Apr 01, 2025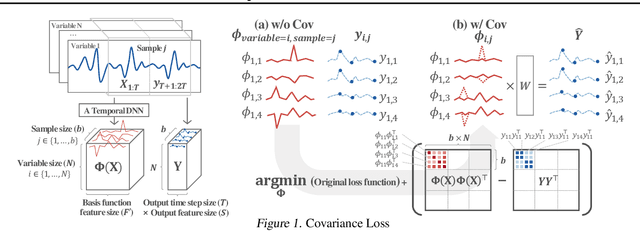



We introduce a novel loss function, Covariance Loss, which is conceptually equivalent to conditional neural processes and has a form of regularization so that is applicable to many kinds of neural networks. With the proposed loss, mappings from input variables to target variables are highly affected by dependencies of target variables as well as mean activation and mean dependencies of input and target variables. This nature enables the resulting neural networks to become more robust to noisy observations and recapture missing dependencies from prior information. In order to show the validity of the proposed loss, we conduct extensive sets of experiments on real-world datasets with state-of-the-art models and discuss the benefits and drawbacks of the proposed Covariance Loss.
* 11 pages, 18 figures
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Jun 20, 2024

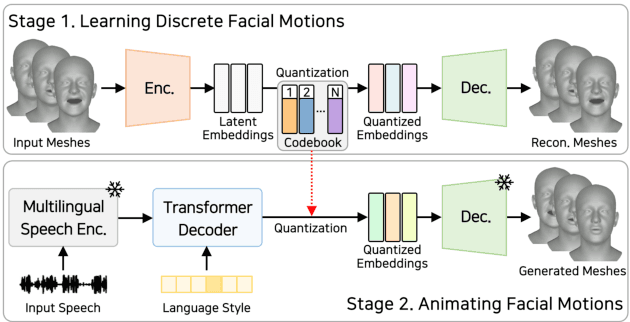

Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
LaughTalk: Expressive 3D Talking Head Generation with Laughter
Nov 02, 2023



Laughter is a unique expression, essential to affirmative social interactions of humans. Although current 3D talking head generation methods produce convincing verbal articulations, they often fail to capture the vitality and subtleties of laughter and smiles despite their importance in social context. In this paper, we introduce a novel task to generate 3D talking heads capable of both articulate speech and authentic laughter. Our newly curated dataset comprises 2D laughing videos paired with pseudo-annotated and human-validated 3D FLAME parameters and vertices. Given our proposed dataset, we present a strong baseline with a two-stage training scheme: the model first learns to talk and then acquires the ability to express laughter. Extensive experiments demonstrate that our method performs favorably compared to existing approaches in both talking head generation and expressing laughter signals. We further explore potential applications on top of our proposed method for rigging realistic avatars.
A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Oct 06, 2023We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset. We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior. Code and datasets will be available at https://neuface-dataset.github.io.
Grouped Convolutional Neural Networks for Multivariate Time Series
May 31, 2018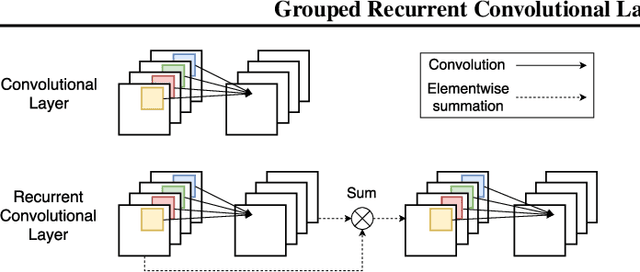
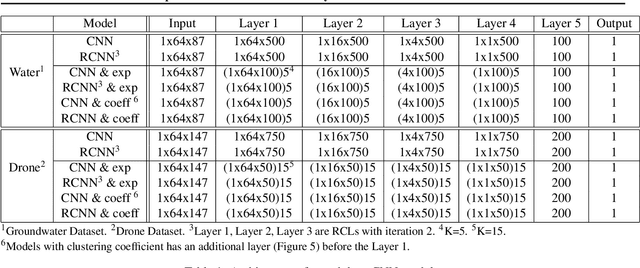
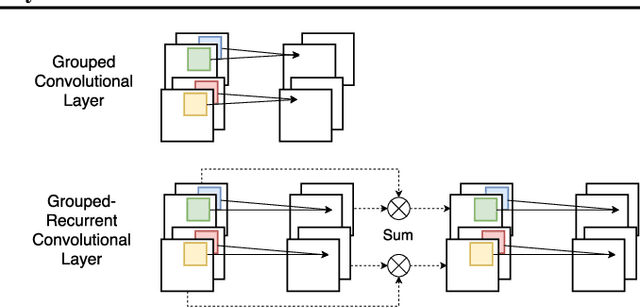
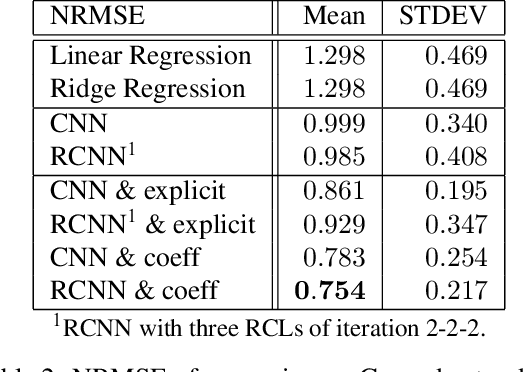
Analyzing multivariate time series data is important for many applications such as automated control, fault diagnosis and anomaly detection. One of the key challenges is to learn latent features automatically from dynamically changing multivariate input. In visual recognition tasks, convolutional neural networks (CNNs) have been successful to learn generalized feature extractors with shared parameters over the spatial domain. However, when high-dimensional multivariate time series is given, designing an appropriate CNN model structure becomes challenging because the kernels may need to be extended through the full dimension of the input volume. To address this issue, we present two structure learning algorithms for deep CNN models. Our algorithms exploit the covariance structure over multiple time series to partition input volume into groups. The first algorithm learns the group CNN structures explicitly by clustering individual input sequences. The second algorithm learns the group CNN structures implicitly from the error backpropagation. In experiments with two real-world datasets, we demonstrate that our group CNNs outperform existing CNN based regression methods.
Global Deconvolutional Networks for Semantic Segmentation
Aug 13, 2016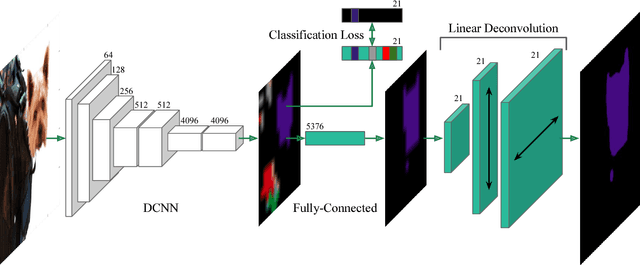
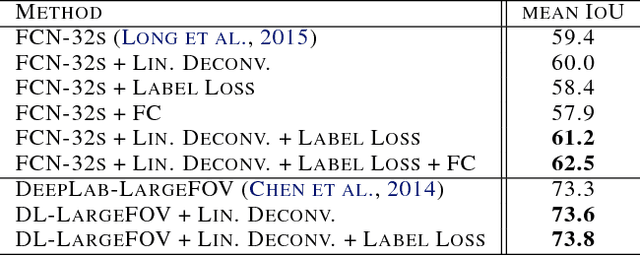


Semantic image segmentation is a principal problem in computer vision, where the aim is to correctly classify each individual pixel of an image into a semantic label. Its widespread use in many areas, including medical imaging and autonomous driving, has fostered extensive research in recent years. Empirical improvements in tackling this task have primarily been motivated by successful exploitation of Convolutional Neural Networks (CNNs) pre-trained for image classification and object recognition. However, the pixel-wise labelling with CNNs has its own unique challenges: (1) an accurate deconvolution, or upsampling, of low-resolution output into a higher-resolution segmentation mask and (2) an inclusion of global information, or context, within locally extracted features. To address these issues, we propose a novel architecture to conduct the equivalent of the deconvolution operation globally and acquire dense predictions. We demonstrate that it leads to improved performance of state-of-the-art semantic segmentation models on the PASCAL VOC 2012 benchmark, reaching 74.0% mean IU accuracy on the test set.