 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture Search of Dynamic Cells for Semantic Video Segmentation
Apr 04, 2019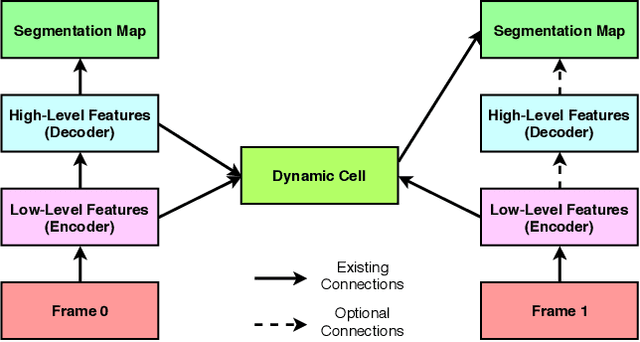

In semantic video segmentation the goal is to acquire consistent dense semantic labelling across image frames. To this end, recent approaches have been reliant on manually arranged operations applied on top of static semantic segmentation networks - with the most prominent building block being the optical flow able to provide information about scene dynamics. Related to that is the line of research concerned with speeding up static networks by approximating expensive parts of them with cheaper alternatives, while propagating information from previous frames. In this work we attempt to come up with generalisation of those methods, and instead of manually designing contextual blocks that connect per-frame outputs, we propose a neural architecture search solution, where the choice of operations together with their sequential arrangement are being predicted by a separate neural network. We showcase that such generalisation leads to stable and accurate results across common benchmarks, such as CityScapes and CamVid datasets. Importantly, the proposed methodology takes only 2 GPU-days, finds high-performing cells and does not rely on the expensive optical flow computation.
Template-Based Automatic Search of Compact Semantic Segmentation Architectures
Apr 04, 2019
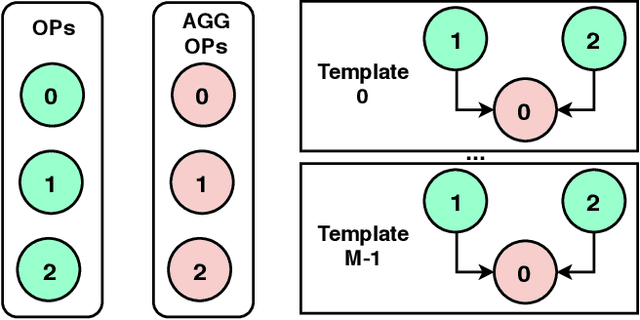
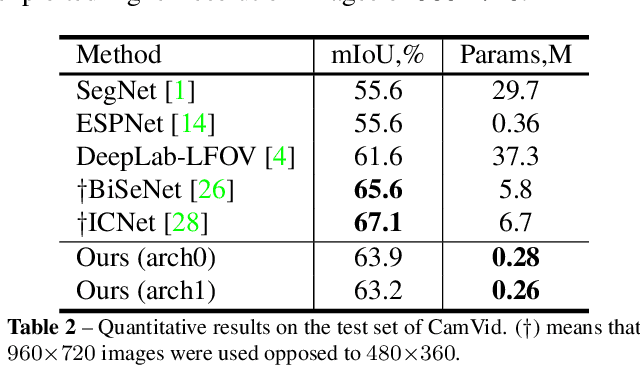
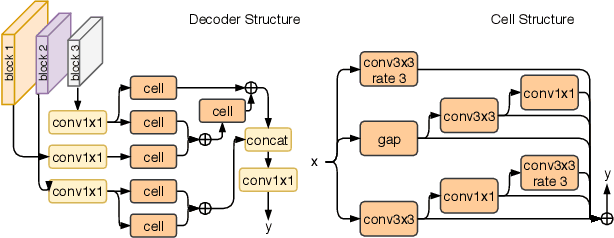
Automatic search of neural architectures for various vision and natural language tasks is becoming a prominent tool as it allows to discover high-performing structures on any dataset of interest. Nevertheless, on more difficult domains, such as dense per-pixel classification, current automatic approaches are limited in their scope - due to their strong reliance on existing image classifiers they tend to search only for a handful of additional layers with discovered architectures still containing a large number of parameters. In contrast, in this work we propose a novel solution able to find light-weight and accurate segmentation architectures starting from only few blocks of a pre-trained classification network. To this end, we progressively build up a methodology that relies on templates of sets of operations, predicts which template and how many times should be applied at each step, while also generating the connectivity structure and downsampling factors. All these decisions are being made by a recurrent neural network that is rewarded based on the score of the emitted architecture on the holdout set and trained using reinforcement learning. One discovered architecture achieves 63.2% mean IoU on CamVid and 67.8% on CityScapes having only 270K parameters.
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Oct 25, 2018
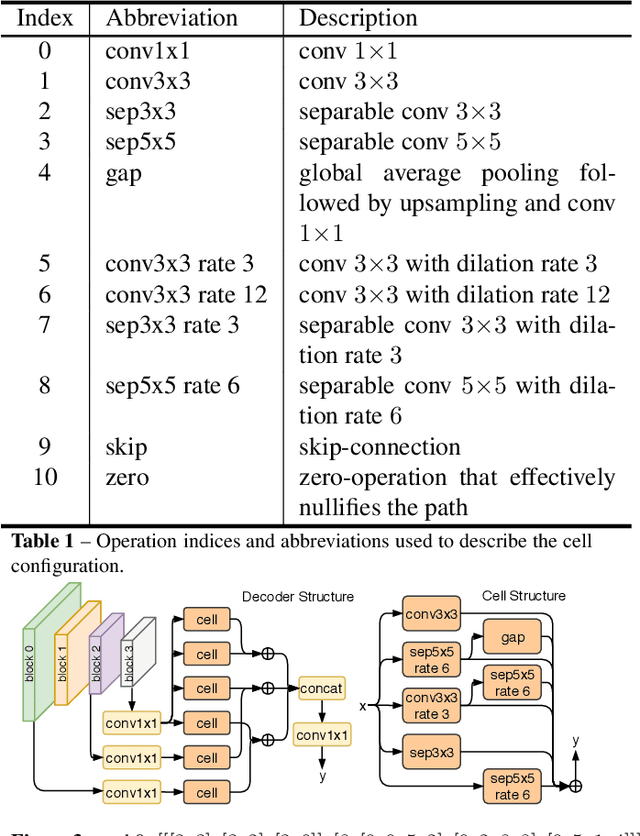
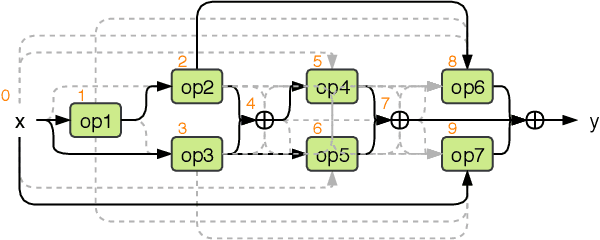

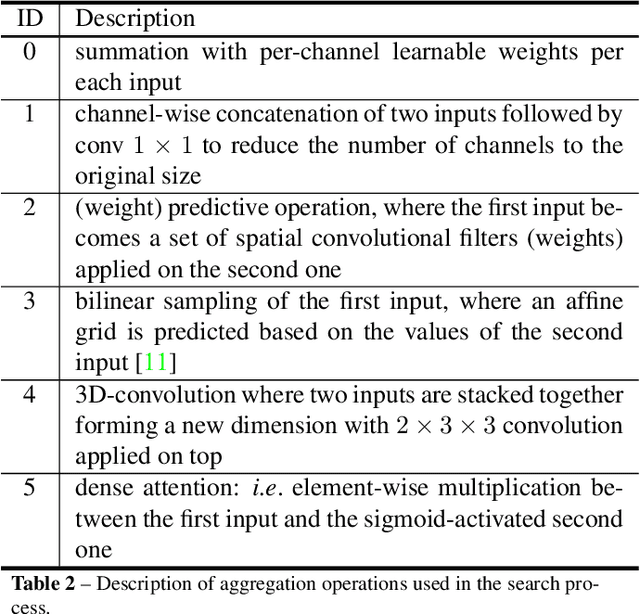
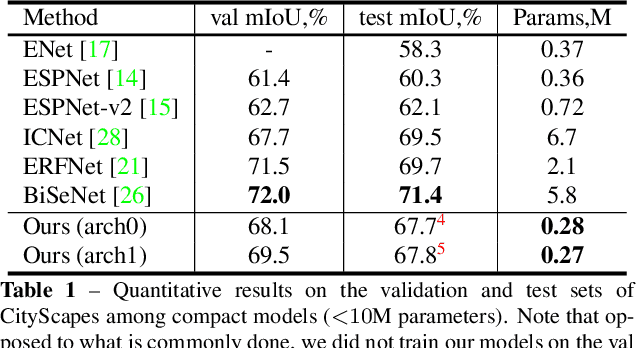
Automated design of architectures tailored for a specific task at hand is an extremely promising, albeit inherently difficult, venue to explore. While most results in this domain have been achieved on image classification and language modelling problems, here we concentrate on dense per-pixel tasks, in particular, semantic image segmentation using fully convolutional networks. In contrast to the aforementioned areas, the design choice of a fully convolutional network requires several changes, ranging from the sort of operations that need to be used - e.g., dilated convolutions - to solving of a more difficult optimisation problem. In this work, we are particularly interested in searching for high-performance compact segmentation architectures, able to run in real-time using limited resources. To achieve that, we intentionally over-parameterise the architecture during the training time via a set of auxiliary cells that provide an intermediate supervisory signal and can be omitted during the evaluation phase. The design of the auxiliary cell is emitted by a controller, a neural architecture with the fixed structure trained using reinforcement learning. More crucially, we demonstrate how to efficiently search for these architectures within limited time and computational budgets. In particular, we rely on a progressive strategy that terminates non-promising architectures from being further trained, and on Polyak averaging coupled with knowledge distillation to speed-up the convergence. Quantitatively, in 8 GPU-days our approach discovers a set of architectures performing on-par with state-of-the-art among compact models.
Light-Weight RefineNet for Real-Time Semantic Segmentation
Oct 08, 2018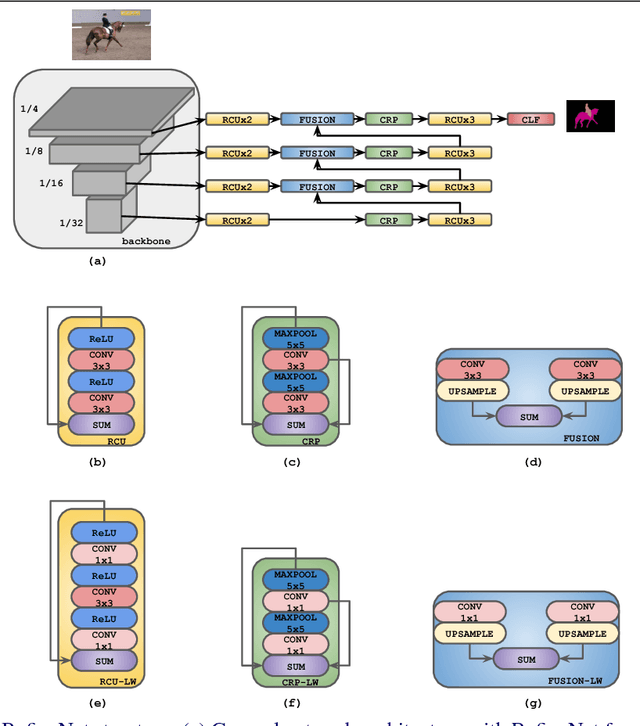

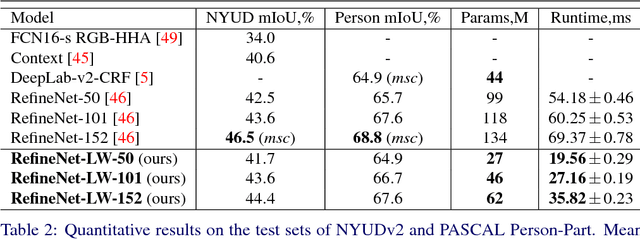

We consider an important task of effective and efficient semantic image segmentation. In particular, we adapt a powerful semantic segmentation architecture, called RefineNet, into the more compact one, suitable even for tasks requiring real-time performance on high-resolution inputs. To this end, we identify computationally expensive blocks in the original setup, and propose two modifications aimed to decrease the number of parameters and floating point operations. By doing that, we achieve more than twofold model reduction, while keeping the performance levels almost intact. Our fastest model undergoes a significant speed-up boost from 20 FPS to 55 FPS on a generic GPU card on 512x512 inputs with solid 81.1% mean iou performance on the test set of PASCAL VOC, while our slowest model with 32 FPS (from original 17 FPS) shows 82.7% mean iou on the same dataset. Alternatively, we showcase that our approach is easily mixable with light-weight classification networks: we attain 79.2% mean iou on PASCAL VOC using a model that contains only 3.3M parameters and performs only 9.3B floating point operations.
Diagnostics in Semantic Segmentation
Sep 27, 2018
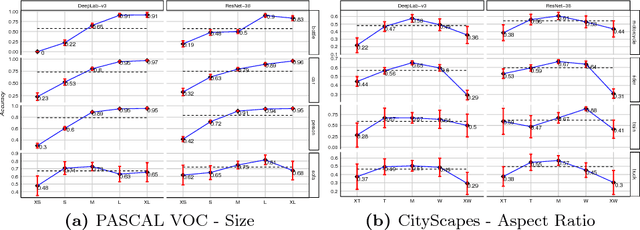
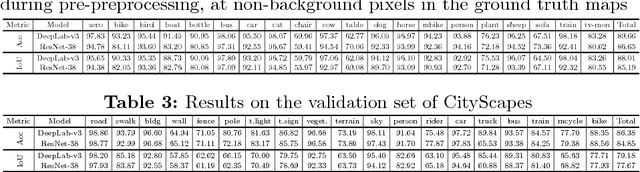
Over the past years, computer vision community has contributed to enormous progress in semantic image segmentation, a per-pixel classification task, crucial for dense scene understanding and rapidly becoming vital in lots of real-world applications, including driverless cars and medical imaging. Most recent models are now reaching previously unthinkable numbers (e.g., 89% mean iou on PASCAL VOC, 83% on CityScapes), and, while intersection-over-union and a range of other metrics provide the general picture of model performance, in this paper we aim to extend them into other meaningful and important for applications characteristics, answering such questions as 'how accurate the model segmentation is on small objects in the general scene?', or 'what are the sources of uncertainty that cause the model to make an erroneous prediction?'. Besides establishing a methodology that covers the performance of a single model from different perspectives, we also showcase several extensions that can be worth pursuing in order to further improve current results in semantic segmentation.
Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations
Sep 13, 2018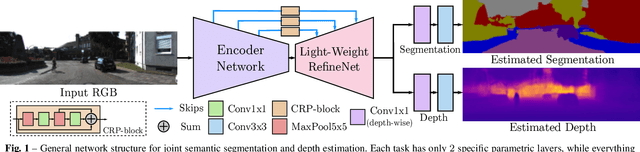

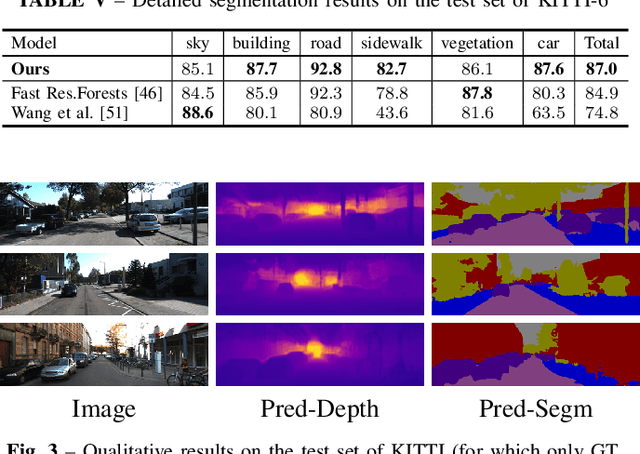

Deployment of deep learning models in robotics as sensory information extractors can be a daunting task to handle, even using generic GPU cards. Here, we address three of its most prominent hurdles, namely, i) the adaptation of a single model to perform multiple tasks at once (in this work, we consider depth estimation and semantic segmentation crucial for acquiring geometric and semantic understanding of the scene), while ii) doing it in real-time, and iii) using asymmetric datasets with uneven numbers of annotations per each modality. To overcome the first two issues, we adapt a recently proposed real-time semantic segmentation network, making few changes to further reduce the number of floating point operations. To approach the third issue, we embrace a simple solution based on hard knowledge distillation under the assumption of having access to a powerful `teacher' network. Finally, we showcase how our system can be easily extended to handle more tasks, and more datasets, all at once. Quantitatively, we achieve 42% mean iou, 0.56m RMSE (lin) and 0.20 RMSE (log) with a single model on NYUDv2-40, 87% mean iou, 3.45m RMSE (lin) and 0.18 RMSE (log) on KITTI-6 for segmentation and KITTI for depth estimation, with one forward pass costing just 17ms and 6.45 GFLOPs on 1200x350 inputs. All these results are either equivalent to (or better than) current state-of-the-art approaches, which were achieved with larger and slower models solving each task separately.
Global Deconvolutional Networks for Semantic Segmentation
Aug 13, 2016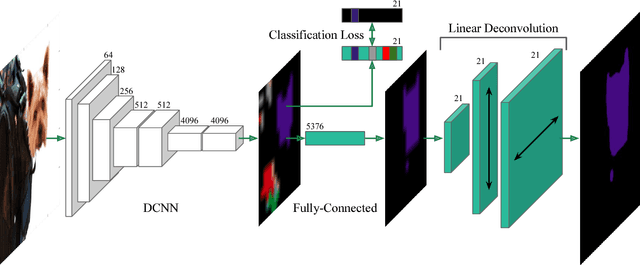
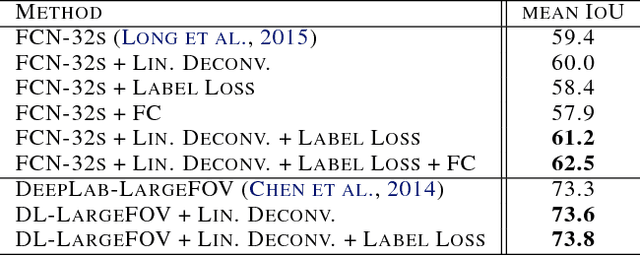


Semantic image segmentation is a principal problem in computer vision, where the aim is to correctly classify each individual pixel of an image into a semantic label. Its widespread use in many areas, including medical imaging and autonomous driving, has fostered extensive research in recent years. Empirical improvements in tackling this task have primarily been motivated by successful exploitation of Convolutional Neural Networks (CNNs) pre-trained for image classification and object recognition. However, the pixel-wise labelling with CNNs has its own unique challenges: (1) an accurate deconvolution, or upsampling, of low-resolution output into a higher-resolution segmentation mask and (2) an inclusion of global information, or context, within locally extracted features. To address these issues, we propose a novel architecture to conduct the equivalent of the deconvolution operation globally and acquire dense predictions. We demonstrate that it leads to improved performance of state-of-the-art semantic segmentation models on the PASCAL VOC 2012 benchmark, reaching 74.0% mean IU accuracy on the test set.