 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENG: End-to-end Neural Geometry for Robust Depth and Pose Estimation using CNNs
Nov 06, 2018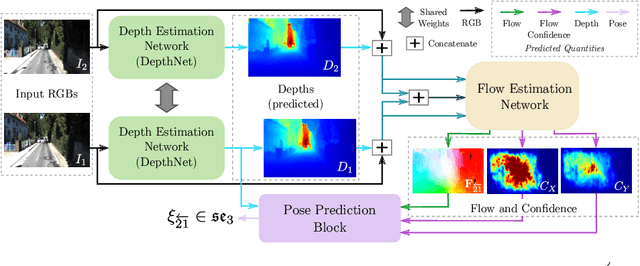
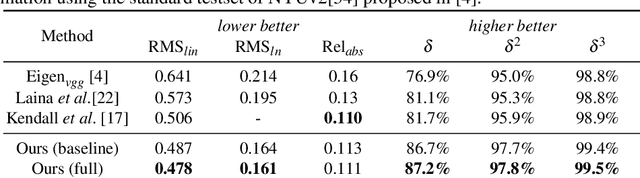
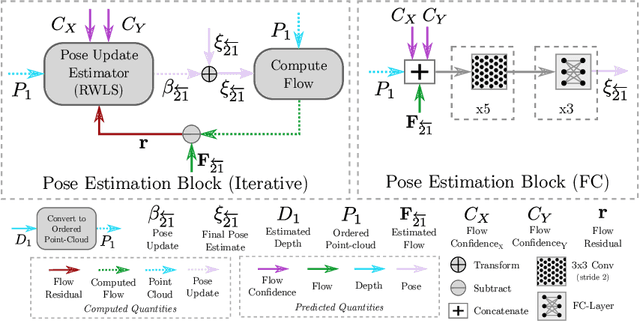
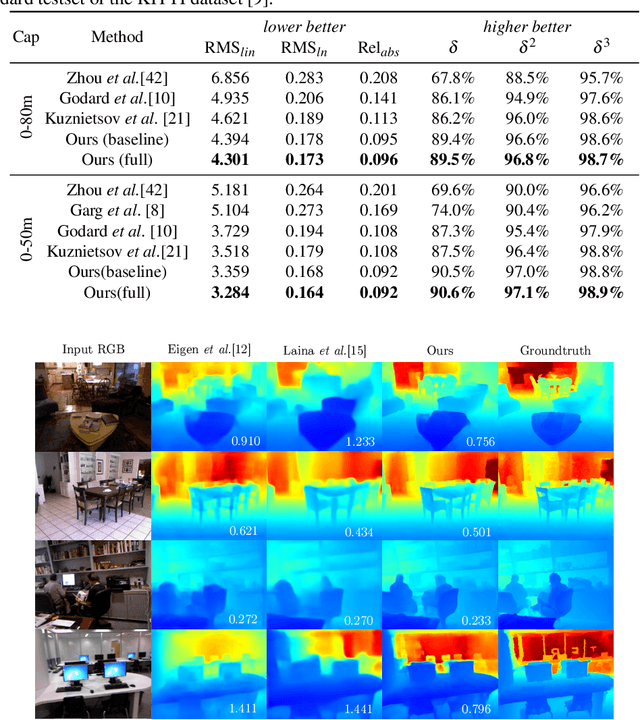
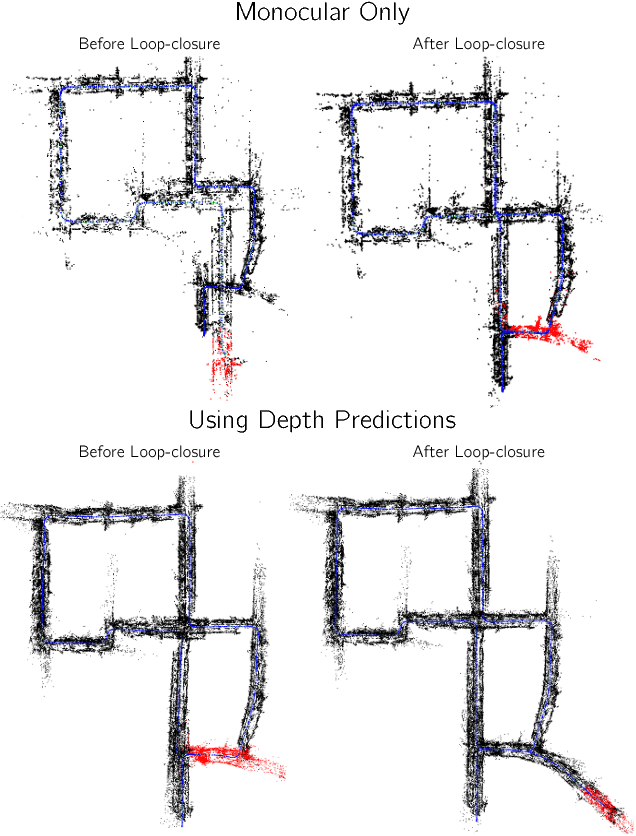
Recovering structure and motion parameters given a image pair or a sequence of images is a well studied problem in computer vision. This is often achieved by employing Structure from Motion (SfM) or Simultaneous Localization and Mapping (SLAM) algorithms based on the real-time requirements. Recently, with the advent of Convolutional Neural Networks (CNNs) researchers have explored the possibility of using machine learning techniques to reconstruct the 3D structure of a scene and jointly predict the camera pose. In this work, we present a framework that achieves state-of-the-art performance on single image depth prediction for both indoor and outdoor scenes. The depth prediction system is then extended to predict optical flow and ultimately the camera pose and trained end-to-end. Our motion estimation framework outperforms the previous motion prediction systems and we also demonstrate that the state-of-the-art metric depths can be further improved using the knowledge of pose.
Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations
Sep 13, 2018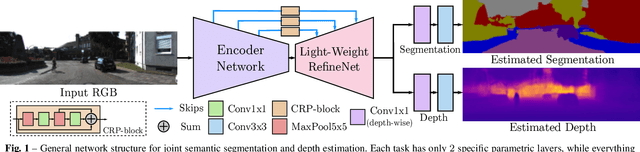

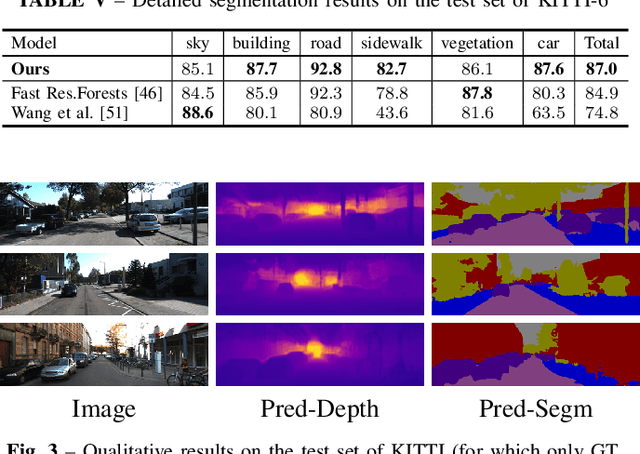

Deployment of deep learning models in robotics as sensory information extractors can be a daunting task to handle, even using generic GPU cards. Here, we address three of its most prominent hurdles, namely, i) the adaptation of a single model to perform multiple tasks at once (in this work, we consider depth estimation and semantic segmentation crucial for acquiring geometric and semantic understanding of the scene), while ii) doing it in real-time, and iii) using asymmetric datasets with uneven numbers of annotations per each modality. To overcome the first two issues, we adapt a recently proposed real-time semantic segmentation network, making few changes to further reduce the number of floating point operations. To approach the third issue, we embrace a simple solution based on hard knowledge distillation under the assumption of having access to a powerful `teacher' network. Finally, we showcase how our system can be easily extended to handle more tasks, and more datasets, all at once. Quantitatively, we achieve 42% mean iou, 0.56m RMSE (lin) and 0.20 RMSE (log) with a single model on NYUDv2-40, 87% mean iou, 3.45m RMSE (lin) and 0.18 RMSE (log) on KITTI-6 for segmentation and KITTI for depth estimation, with one forward pass costing just 17ms and 6.45 GFLOPs on 1200x350 inputs. All these results are either equivalent to (or better than) current state-of-the-art approaches, which were achieved with larger and slower models solving each task separately.
CReaM: Condensed Real-time Models for Depth Prediction using Convolutional Neural Networks
Jul 24, 2018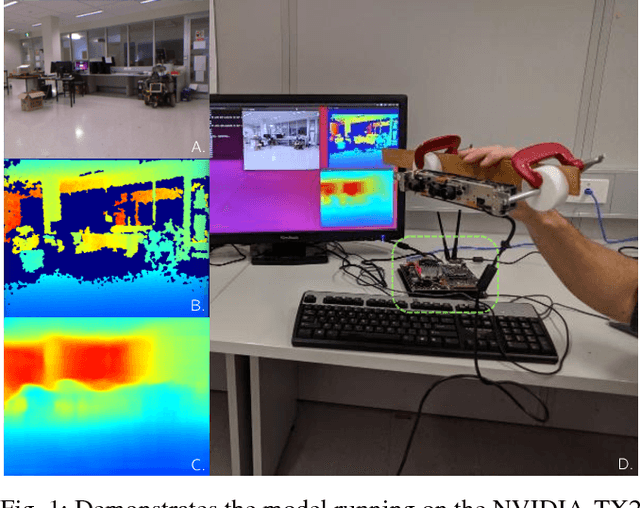
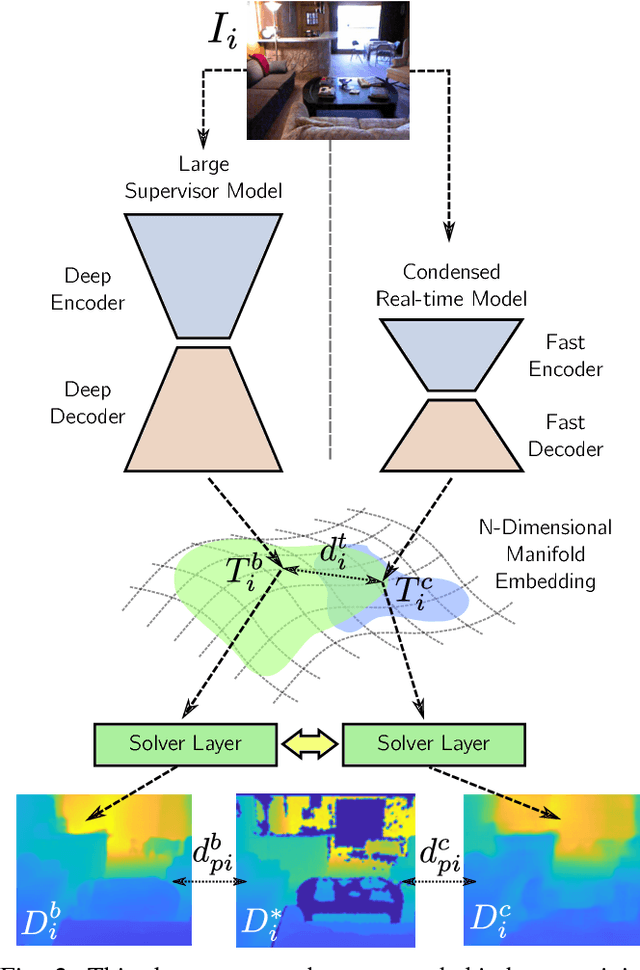
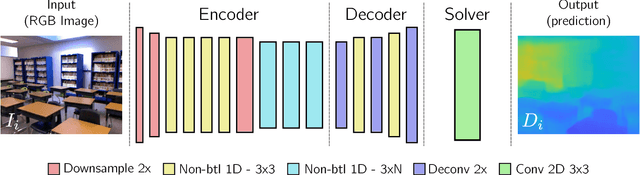
Since the resurgence of CNNs the robotic vision community has developed a range of algorithms that perform classification, semantic segmentation and structure prediction (depths, normals, surface curvature) using neural networks. While some of these models achieve state-of-the art results and super human level performance, deploying these models in a time critical robotic environment remains an ongoing challenge. Real-time frameworks are of paramount importance to build a robotic society where humans and robots integrate seamlessly. To this end, we present a novel real-time structure prediction framework that predicts depth at 30fps on an NVIDIA-TX2. At the time of writing, this is the first piece of work to showcase such a capability on a mobile platform. We also demonstrate with extensive experiments that neural networks with very large model capacities can be leveraged in order to train accurate condensed model architectures in a "from teacher to student" style knowledge transfer.
Joint Pose and Principal Curvature Refinement Using Quadrics
Jul 14, 2017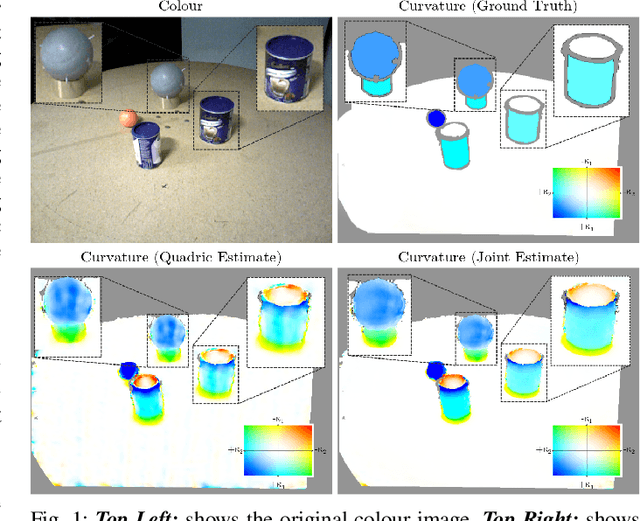
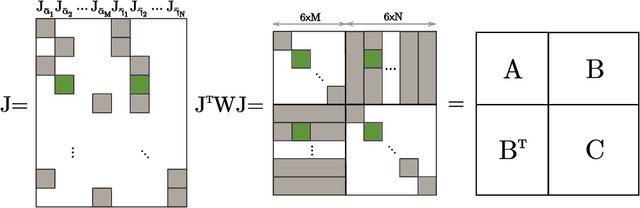
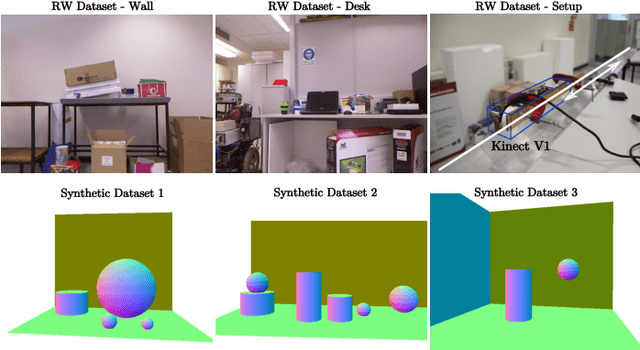
In this paper we present a novel joint approach for optimising surface curvature and pose alignment. We present two implementations of this joint optimisation strategy, including a fast implementation that uses two frames and an offline multi-frame approach. We demonstrate an order of magnitude improvement in simulation over state of the art dense relative point-to-plane Iterative Closest Point (ICP) pose alignment using our dense joint frame-to-frame approach and show comparable pose drift to dense point-to-plane ICP bundle adjustment using low-cost depth sensors. Additionally our improved joint quadric based approach can be used to more accurately estimate surface curvature on noisy point clouds than previous approaches.
A Fast Method For Computing Principal Curvatures From Range Images
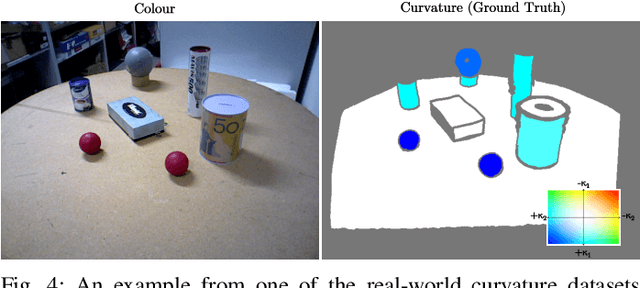
Jul 14, 2017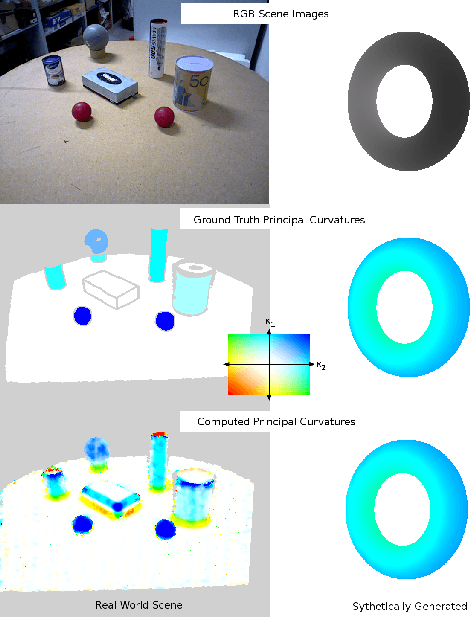
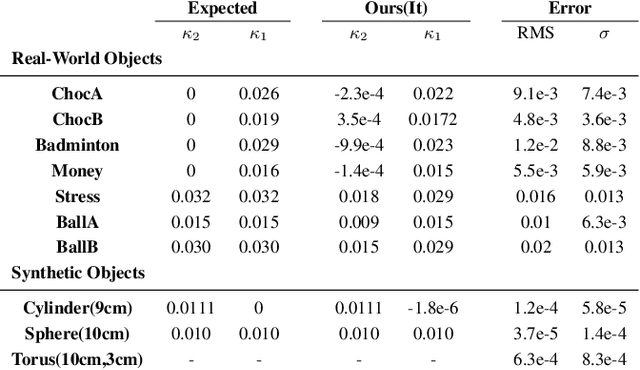
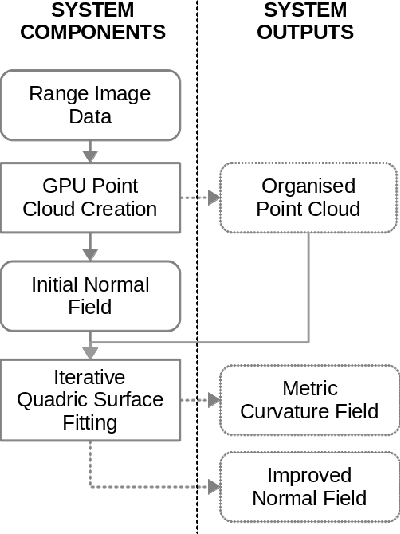
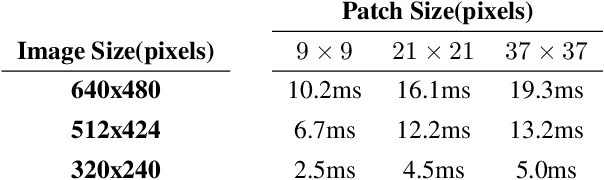
Estimation of surface curvature from range data is important for a range of tasks in computer vision and robotics, object segmentation, object recognition and robotic grasping estimation. This work presents a fast method of robustly computing accurate metric principal curvature values from noisy point clouds which was implemented on GPU. In contrast to existing readily available solutions which first differentiate the surface to estimate surface normals and then differentiate these to obtain curvature, amplifying noise, our method iteratively fits parabolic quadric surface patches to the data. Additionally previous methods with a similar formulation use less robust techniques less applicable to a high noise sensor. We demonstrate that our method is fast and provides better curvature estimates than existing techniques. In particular we compare our method to several alternatives to demonstrate the improvement.
Joint Prediction of Depths, Normals and Surface Curvature from RGB Images using CNNs
Jun 23, 2017
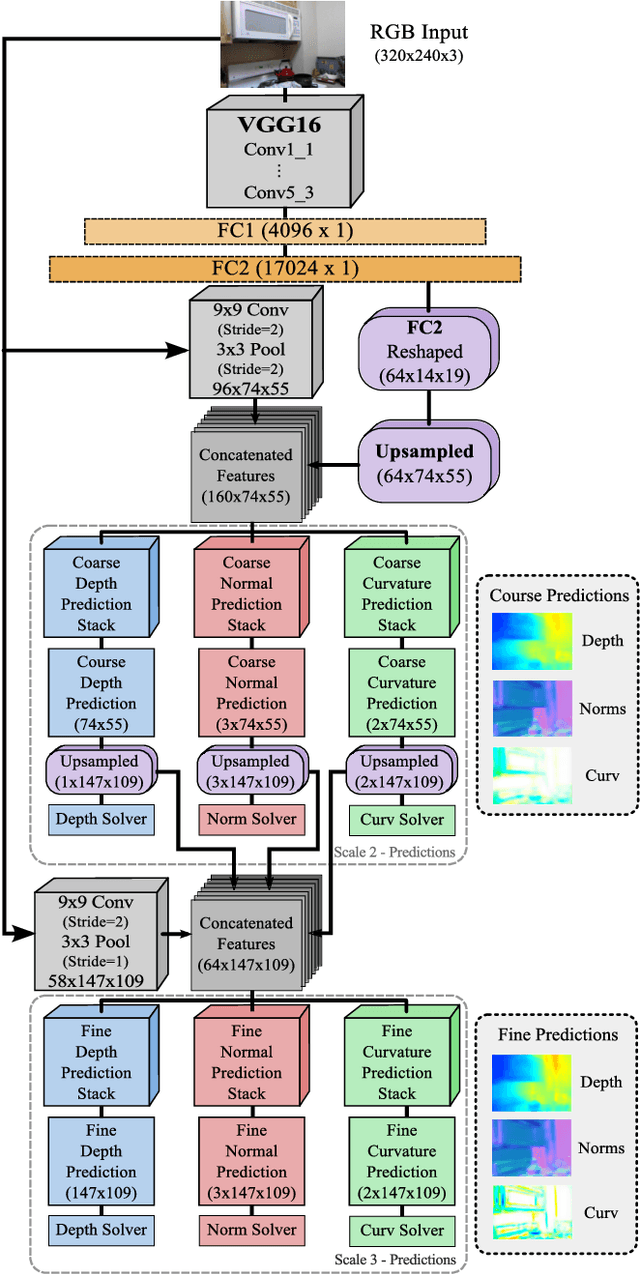
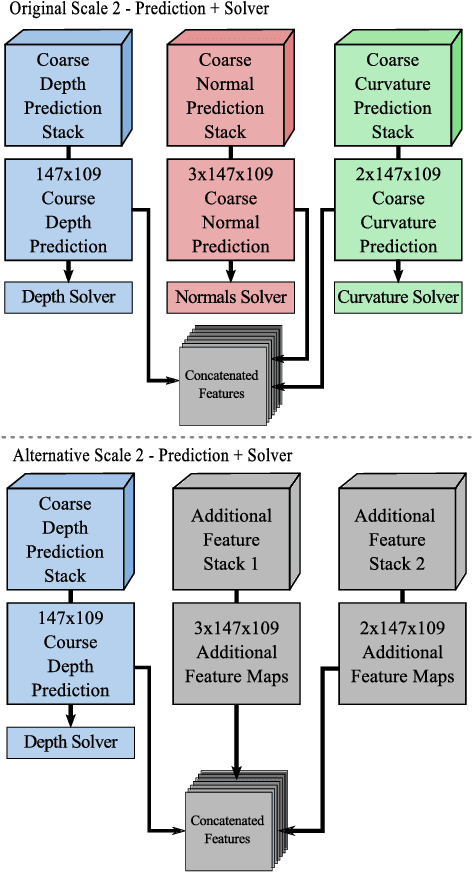

Understanding the 3D structure of a scene is of vital importance, when it comes to developing fully autonomous robots. To this end, we present a novel deep learning based framework that estimates depth, surface normals and surface curvature by only using a single RGB image. To the best of our knowledge this is the first work to estimate surface curvature from colour using a machine learning approach. Additionally, we demonstrate that by tuning the network to infer well designed features, such as surface curvature, we can achieve improved performance at estimating depth and normals.This indicates that network guidance is still a useful aspect of designing and training a neural network. We run extensive experiments where the network is trained to infer different tasks while the model capacity is kept constant resulting in different feature maps based on the tasks at hand. We outperform the previous state-of-the-art benchmarks which jointly estimate depths and surface normals while predicting surface curvature in parallel.