 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMPNet: Neural Localisation and Mapping Using Embedded Memory Points
Aug 02, 2019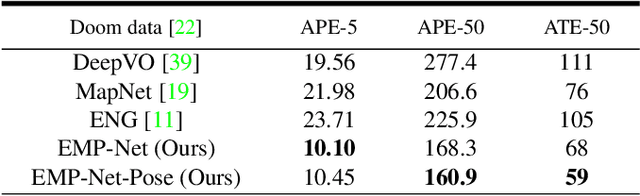
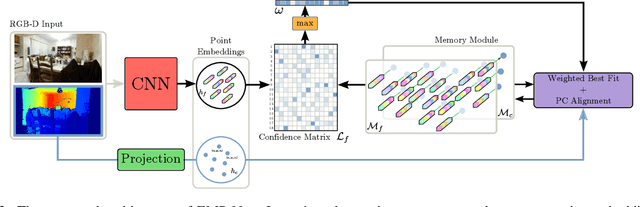
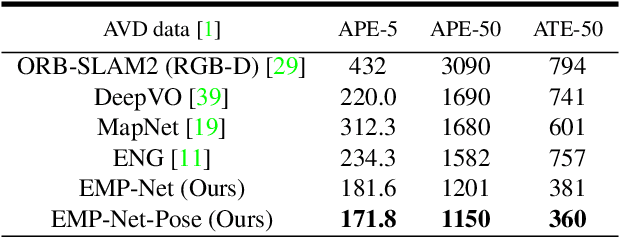
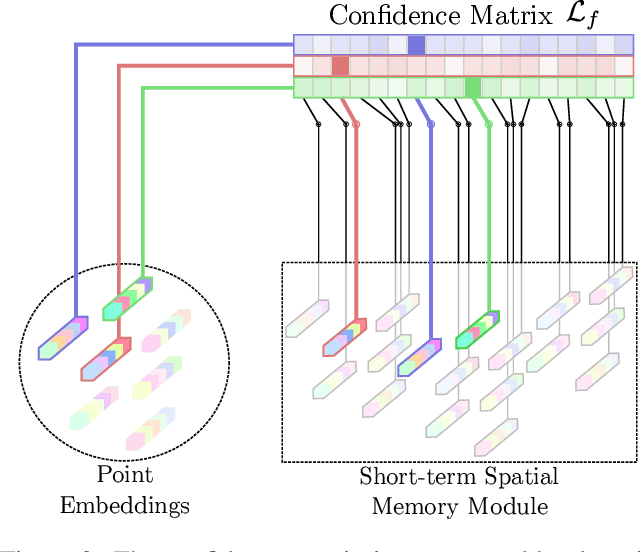
Continuously estimating an agent's state space and a representation of its surroundings has proven vital towards full autonomy. A shared common ground among systems which successfully achieve this feat is the integration of previously encountered observations into the current state being estimated. This necessitates the use of a memory module for incorporating previously visited states whilst simultaneously offering an internal representation of the observed environment. In this work we develop a memory module which contains rigidly aligned point-embeddings that represent a coherent scene structure acquired from an RGB-D sequence of observations. The point-embeddings are extracted using modern convolutional neural network architectures, and alignment is performed by computing a dense correspondence matrix between a new observation and the current embeddings residing in the memory module. The whole framework is end-to-end trainable, resulting in a recurrent joint optimisation of the point-embeddings contained in the memory. This process amplifies the shared information across states, providing increased robustness and accuracy. We show significant improvement of our method across a set of experiments performed on the synthetic VIZDoom environment and a real world Active Vision Dataset.
Look No Deeper: Recognizing Places from Opposing Viewpoints under Varying Scene Appearance using Single-View Depth Estimation
Feb 20, 2019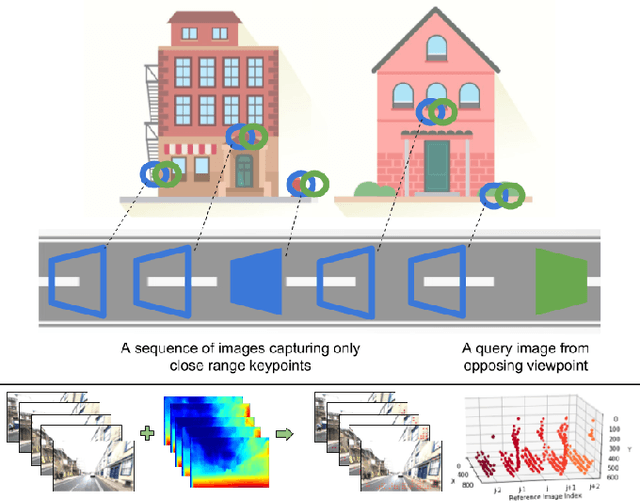
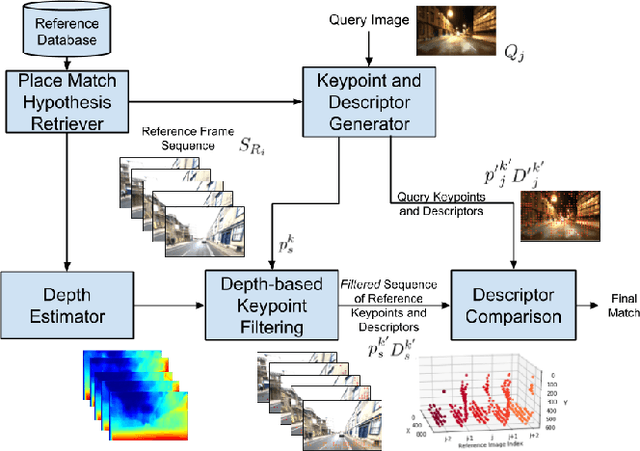

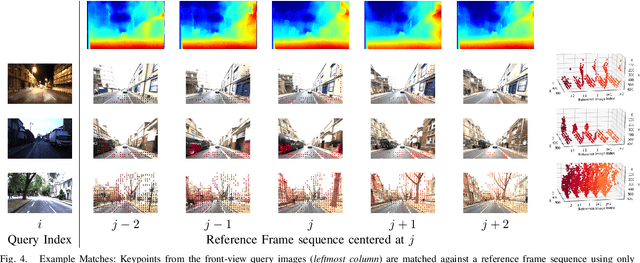
Visual place recognition (VPR) - the act of recognizing a familiar visual place - becomes difficult when there is extreme environmental appearance change or viewpoint change. Particularly challenging is the scenario where both phenomena occur simultaneously, such as when returning for the first time along a road at night that was previously traversed during the day in the opposite direction. While such problems can be solved with panoramic sensors, humans solve this problem regularly with limited field of view vision and without needing to constantly turn around. In this paper, we present a new depth- and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
ENG: End-to-end Neural Geometry for Robust Depth and Pose Estimation using CNNs
Nov 06, 2018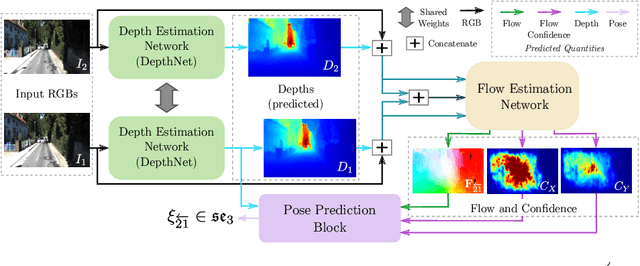
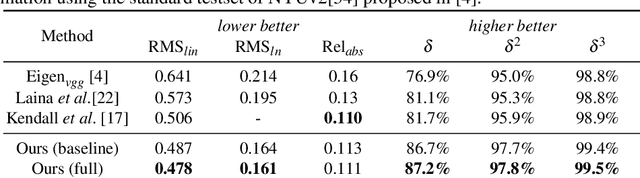
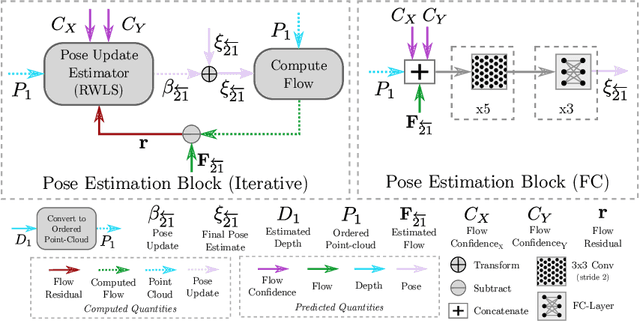
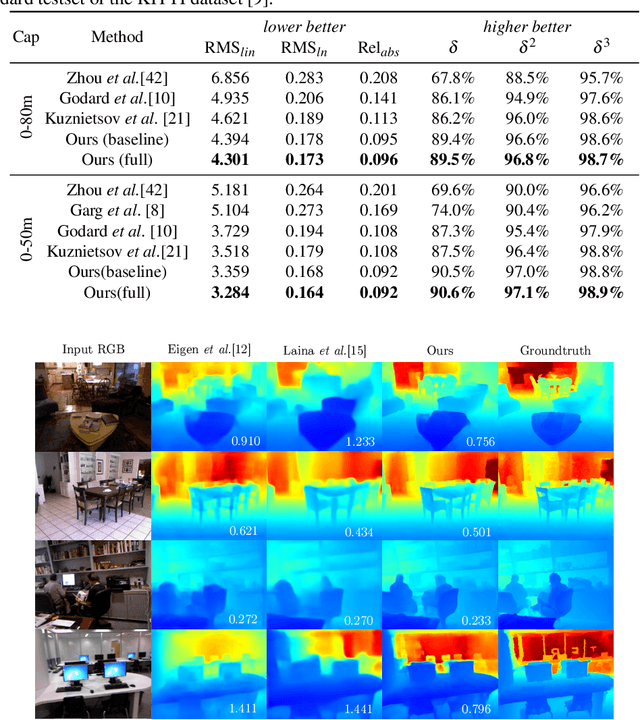
Recovering structure and motion parameters given a image pair or a sequence of images is a well studied problem in computer vision. This is often achieved by employing Structure from Motion (SfM) or Simultaneous Localization and Mapping (SLAM) algorithms based on the real-time requirements. Recently, with the advent of Convolutional Neural Networks (CNNs) researchers have explored the possibility of using machine learning techniques to reconstruct the 3D structure of a scene and jointly predict the camera pose. In this work, we present a framework that achieves state-of-the-art performance on single image depth prediction for both indoor and outdoor scenes. The depth prediction system is then extended to predict optical flow and ultimately the camera pose and trained end-to-end. Our motion estimation framework outperforms the previous motion prediction systems and we also demonstrate that the state-of-the-art metric depths can be further improved using the knowledge of pose.
Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations
Sep 13, 2018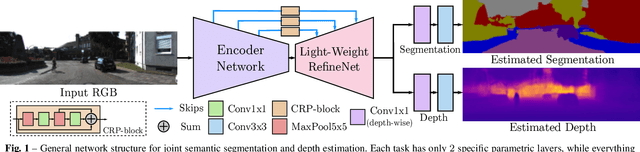

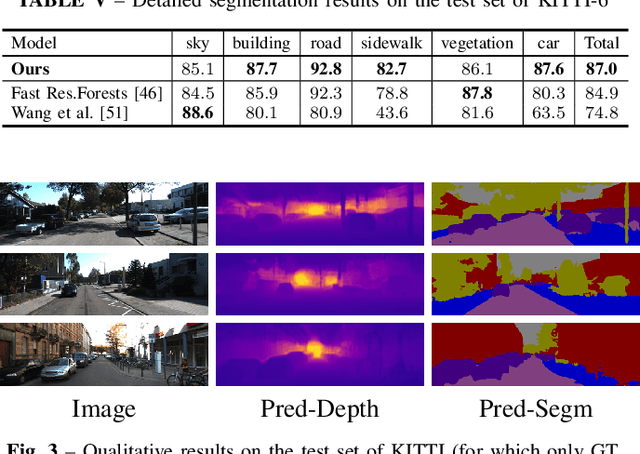

Deployment of deep learning models in robotics as sensory information extractors can be a daunting task to handle, even using generic GPU cards. Here, we address three of its most prominent hurdles, namely, i) the adaptation of a single model to perform multiple tasks at once (in this work, we consider depth estimation and semantic segmentation crucial for acquiring geometric and semantic understanding of the scene), while ii) doing it in real-time, and iii) using asymmetric datasets with uneven numbers of annotations per each modality. To overcome the first two issues, we adapt a recently proposed real-time semantic segmentation network, making few changes to further reduce the number of floating point operations. To approach the third issue, we embrace a simple solution based on hard knowledge distillation under the assumption of having access to a powerful `teacher' network. Finally, we showcase how our system can be easily extended to handle more tasks, and more datasets, all at once. Quantitatively, we achieve 42% mean iou, 0.56m RMSE (lin) and 0.20 RMSE (log) with a single model on NYUDv2-40, 87% mean iou, 3.45m RMSE (lin) and 0.18 RMSE (log) on KITTI-6 for segmentation and KITTI for depth estimation, with one forward pass costing just 17ms and 6.45 GFLOPs on 1200x350 inputs. All these results are either equivalent to (or better than) current state-of-the-art approaches, which were achieved with larger and slower models solving each task separately.
CReaM: Condensed Real-time Models for Depth Prediction using Convolutional Neural Networks
Jul 24, 2018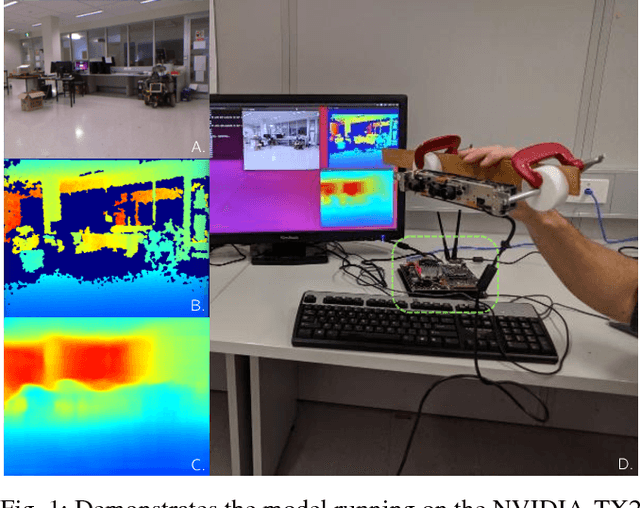
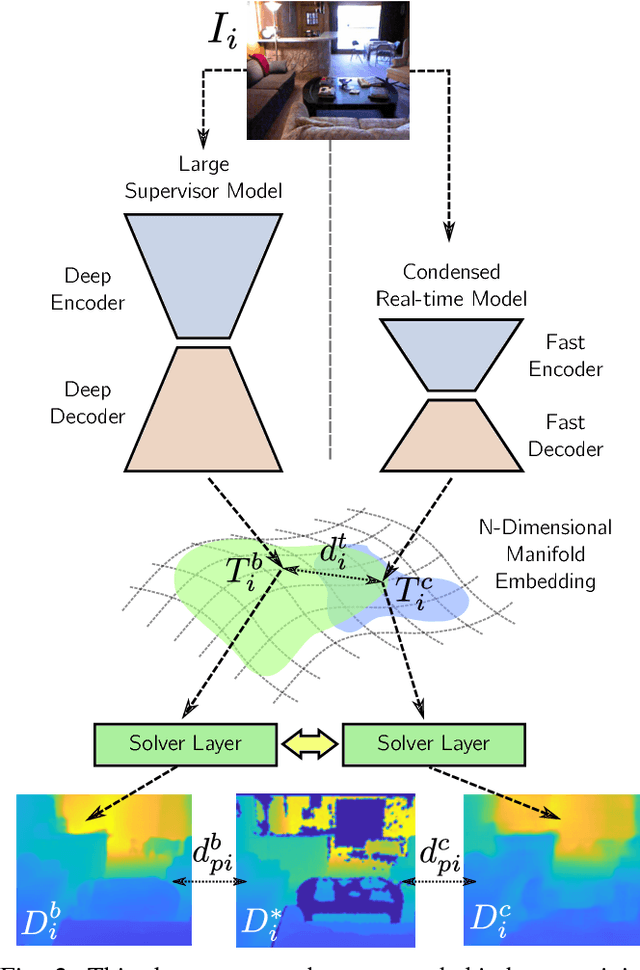
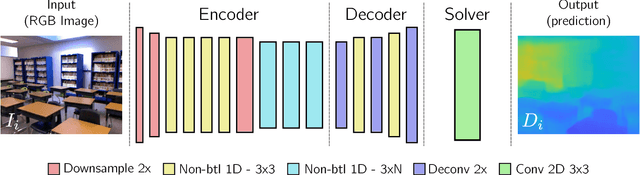
Since the resurgence of CNNs the robotic vision community has developed a range of algorithms that perform classification, semantic segmentation and structure prediction (depths, normals, surface curvature) using neural networks. While some of these models achieve state-of-the art results and super human level performance, deploying these models in a time critical robotic environment remains an ongoing challenge. Real-time frameworks are of paramount importance to build a robotic society where humans and robots integrate seamlessly. To this end, we present a novel real-time structure prediction framework that predicts depth at 30fps on an NVIDIA-TX2. At the time of writing, this is the first piece of work to showcase such a capability on a mobile platform. We also demonstrate with extensive experiments that neural networks with very large model capacities can be leveraged in order to train accurate condensed model architectures in a "from teacher to student" style knowledge transfer.
Just-in-Time Reconstruction: Inpainting Sparse Maps using Single View Depth Predictors as Priors
May 11, 2018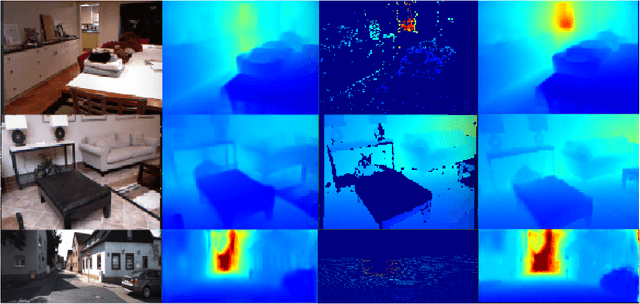

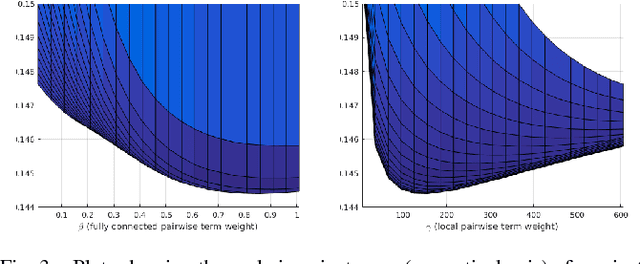
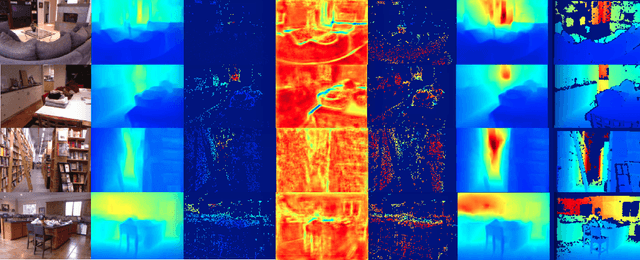
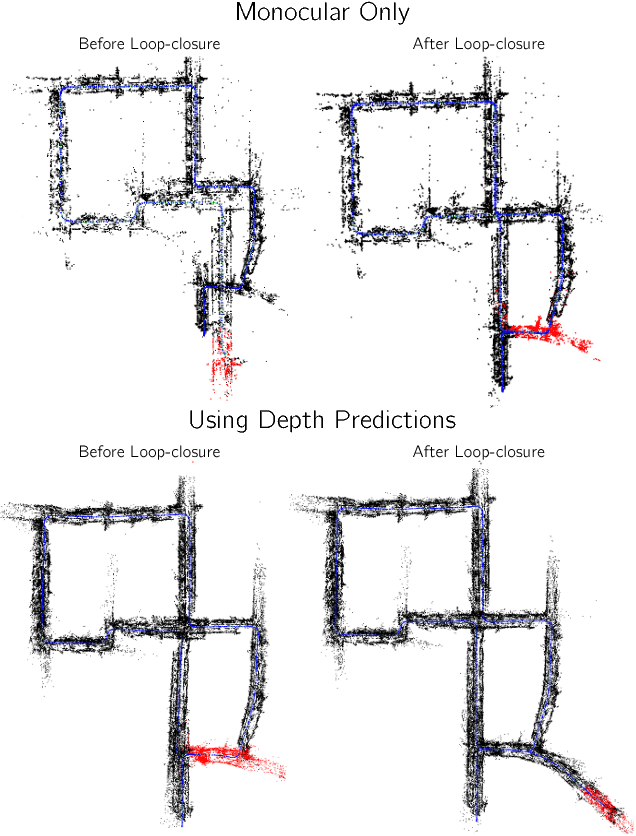
We present ``just-in-time reconstruction" as real-time image-guided inpainting of a map with arbitrary scale and sparsity to generate a fully dense depth map for the image. In particular, our goal is to inpaint a sparse map --- obtained from either a monocular visual SLAM system or a sparse sensor --- using a single-view depth prediction network as a virtual depth sensor. We adopt a fairly standard approach to data fusion, to produce a fused depth map by performing inference over a novel fully-connected Conditional Random Field (CRF) which is parameterized by the input depth maps and their pixel-wise confidence weights. Crucially, we obtain the confidence weights that parameterize the CRF model in a data-dependent manner via Convolutional Neural Networks (CNNs) which are trained to model the conditional depth error distributions given each source of input depth map and the associated RGB image. Our CRF model penalises absolute depth error in its nodes and pairwise scale-invariant depth error in its edges, and the confidence-based fusion minimizes the impact of outlier input depth values on the fused result. We demonstrate the flexibility of our method by real-time inpainting of ORB-SLAM, Kinect, and LIDAR depth maps acquired both indoors and outdoors at arbitrary scale and varied amount of irregular sparsity.
Joint Prediction of Depths, Normals and Surface Curvature from RGB Images using CNNs
Jun 23, 2017
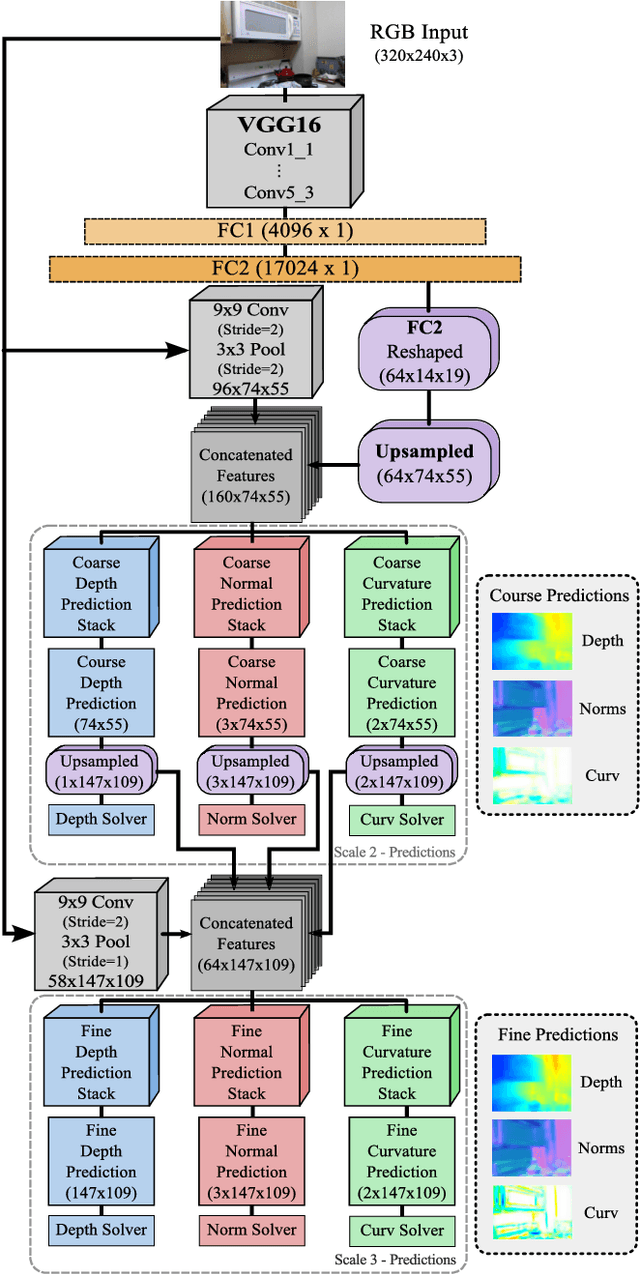
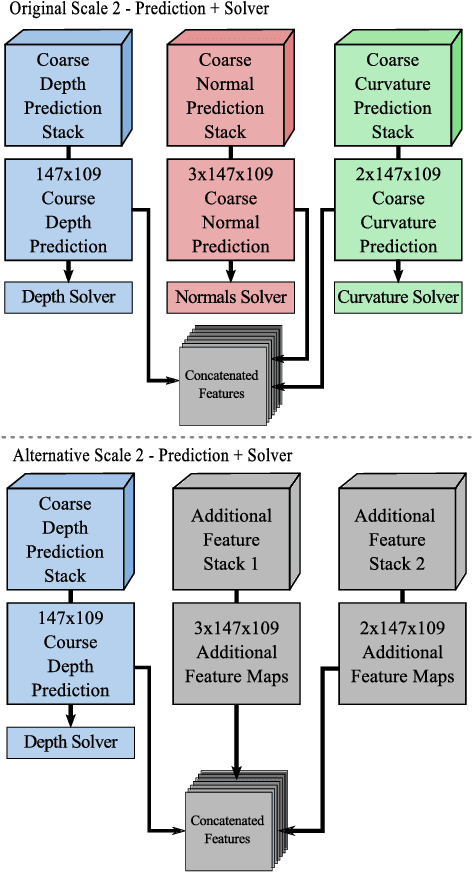

Understanding the 3D structure of a scene is of vital importance, when it comes to developing fully autonomous robots. To this end, we present a novel deep learning based framework that estimates depth, surface normals and surface curvature by only using a single RGB image. To the best of our knowledge this is the first work to estimate surface curvature from colour using a machine learning approach. Additionally, we demonstrate that by tuning the network to infer well designed features, such as surface curvature, we can achieve improved performance at estimating depth and normals.This indicates that network guidance is still a useful aspect of designing and training a neural network. We run extensive experiments where the network is trained to infer different tasks while the model capacity is kept constant resulting in different feature maps based on the tasks at hand. We outperform the previous state-of-the-art benchmarks which jointly estimate depths and surface normals while predicting surface curvature in parallel.