 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook No Deeper: Recognizing Places from Opposing Viewpoints under Varying Scene Appearance using Single-View Depth Estimation
Feb 20, 2019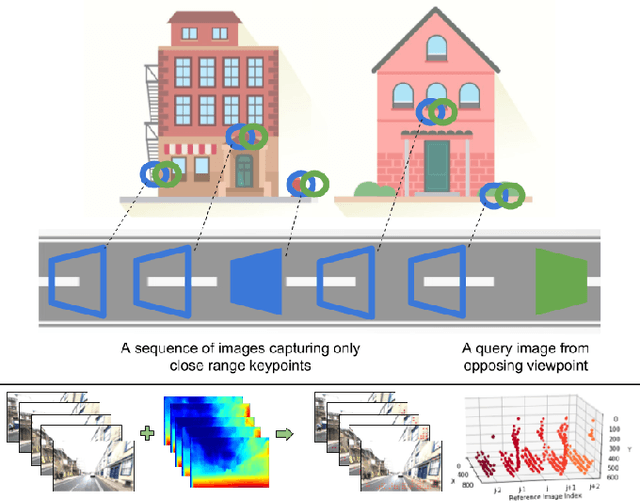
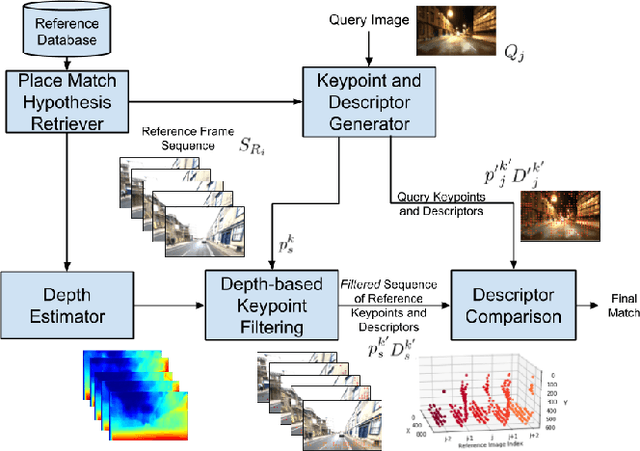

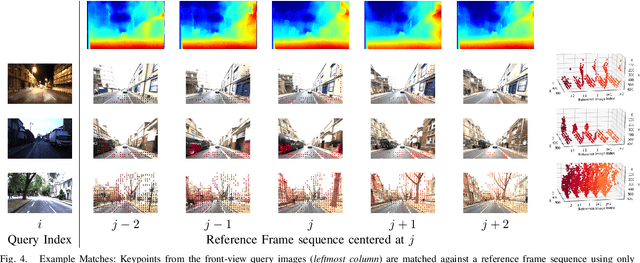
Visual place recognition (VPR) - the act of recognizing a familiar visual place - becomes difficult when there is extreme environmental appearance change or viewpoint change. Particularly challenging is the scenario where both phenomena occur simultaneously, such as when returning for the first time along a road at night that was previously traversed during the day in the opposite direction. While such problems can be solved with panoramic sensors, humans solve this problem regularly with limited field of view vision and without needing to constantly turn around. In this paper, we present a new depth- and temporal-aware visual place recognition system that solves the opposing viewpoint, extreme appearance-change visual place recognition problem. Our system performs sequence-to-single matching by extracting depth-filtered keypoints using a state-of-the-art depth estimation pipeline, constructing a keypoint sequence over multiple frames from the reference dataset, and comparing those keypoints to those in a single query image. We evaluate the system on a challenging benchmark dataset and show that it consistently outperforms state-of-the-art techniques. We also develop a range of diagnostic simulation experiments that characterize the contribution of depth-filtered keypoint sequences with respect to key domain parameters including degree of appearance change and camera motion.
UnDEMoN 2.0: Improved Depth and Ego Motion Estimation through Deep Image Sampling
Nov 27, 2018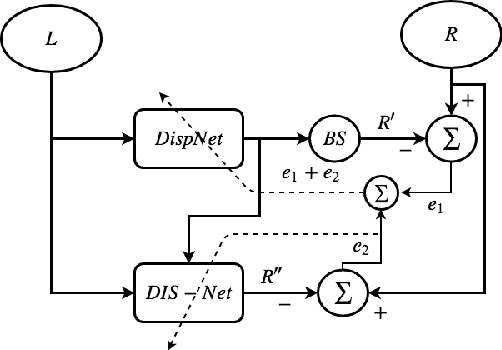
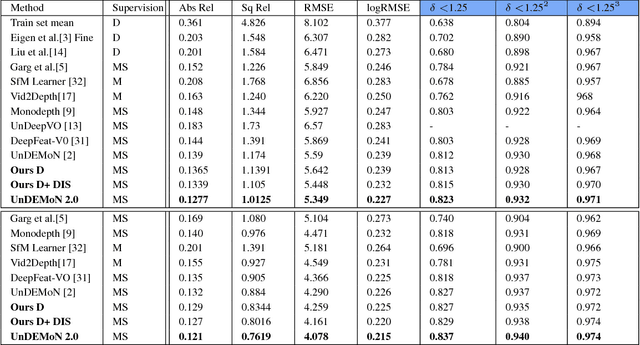


In this paper, we provide an improved version of UnDEMoN model for depth and ego motion estimation from monocular images. The improvement is achieved by combining the standard bi-linear sampler with a deep network based image sampling model (DIS-NET) to provide better image reconstruction capabilities on which the depth estimation accuracy depends in un-supervised learning models. While DIS-NET provides higher order regression and larger input search space, the bi-linear sampler provides geometric constraints necessary for reducing the size of the solution space for an ill-posed problem of this kind. This combination is shown to provide significant improvement in depth and pose estimation accuracy outperforming all existing state-of-the-art methods in this category. In addition, the modified network uses far less number of tunable parameters making it one of the lightest deep network model for depth estimation. The proposed model is labeled as "UnDEMoN 2.0" indicating an improvement over the existing UnDEMoN model. The efficacy of the proposed model is demonstrated through rigorous experimental analysis on the standard KITTI dataset.
A Deeper Insight into the UnDEMoN: Unsupervised Deep Network for Depth and Ego-Motion Estimation
Sep 10, 2018

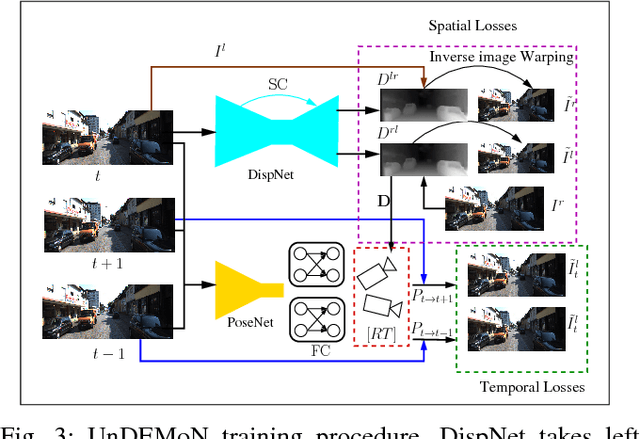
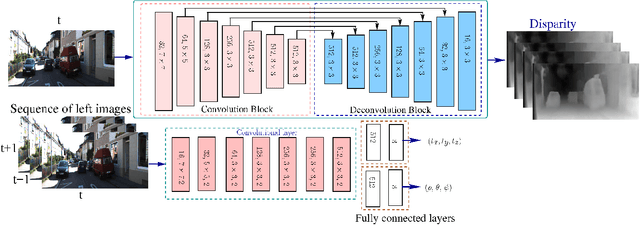
This paper presents an unsupervised deep learning framework called UnDEMoN for estimating dense depth map and 6-DoF camera pose information directly from monocular images. The proposed network is trained using unlabeled monocular stereo image pairs and is shown to provide superior performance in depth and ego-motion estimation compared to the existing state-of-the-art. These improvements are achieved by introducing a new objective function that aims to minimize spatial as well as temporal reconstruction losses simultaneously. These losses are defined using bi-linear sampling kernel and penalized using the Charbonnier penalty function. The objective function, thus created, provides robustness to image gradient noises thereby improving the overall estimation accuracy without resorting to any coarse to fine strategies which are currently prevalent in the literature. Another novelty lies in the fact that we combine a disparity-based depth estimation network with a pose estimation network to obtain absolute scale-aware 6 DOF Camera pose and superior depth map. The effectiveness of the proposed approach is demonstrated through performance comparison with the existing supervised and unsupervised methods on the KITTI driving dataset.