 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deeper Insight into the UnDEMoN: Unsupervised Deep Network for Depth and Ego-Motion Estimation
Paper and Code
Sep 10, 2018

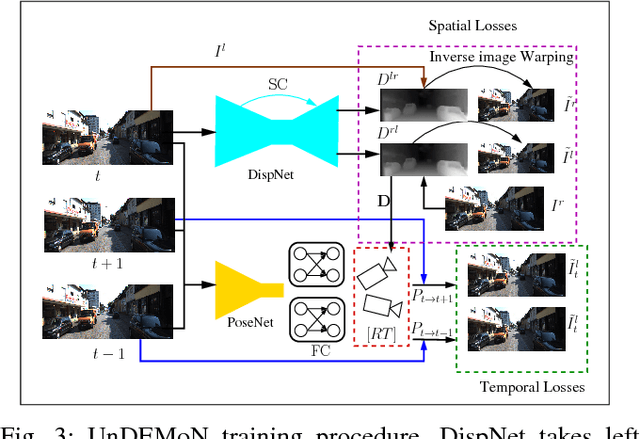
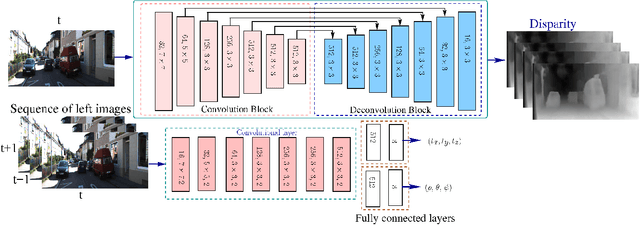
This paper presents an unsupervised deep learning framework called UnDEMoN for estimating dense depth map and 6-DoF camera pose information directly from monocular images. The proposed network is trained using unlabeled monocular stereo image pairs and is shown to provide superior performance in depth and ego-motion estimation compared to the existing state-of-the-art. These improvements are achieved by introducing a new objective function that aims to minimize spatial as well as temporal reconstruction losses simultaneously. These losses are defined using bi-linear sampling kernel and penalized using the Charbonnier penalty function. The objective function, thus created, provides robustness to image gradient noises thereby improving the overall estimation accuracy without resorting to any coarse to fine strategies which are currently prevalent in the literature. Another novelty lies in the fact that we combine a disparity-based depth estimation network with a pose estimation network to obtain absolute scale-aware 6 DOF Camera pose and superior depth map. The effectiveness of the proposed approach is demonstrated through performance comparison with the existing supervised and unsupervised methods on the KITTI driving dataset.