 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnostics in Semantic Segmentation
Paper and Code

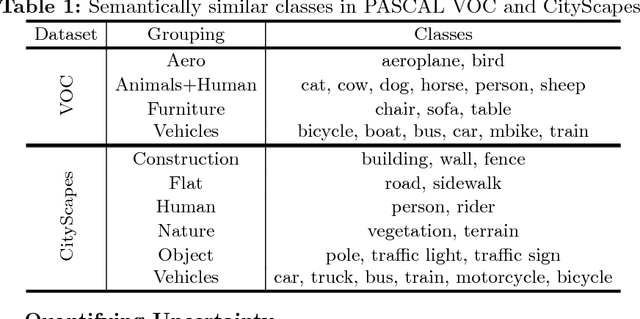
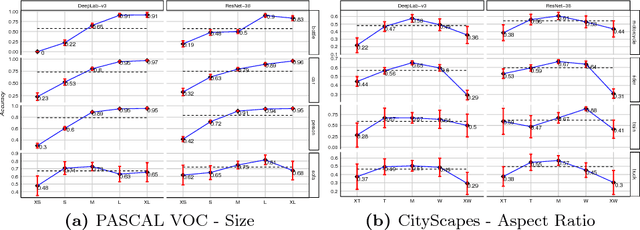
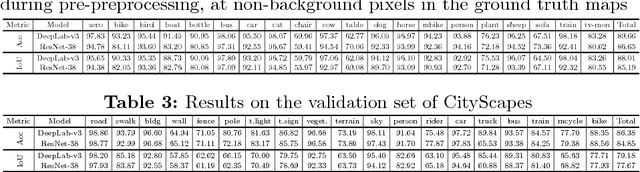
Over the past years, computer vision community has contributed to enormous progress in semantic image segmentation, a per-pixel classification task, crucial for dense scene understanding and rapidly becoming vital in lots of real-world applications, including driverless cars and medical imaging. Most recent models are now reaching previously unthinkable numbers (e.g., 89% mean iou on PASCAL VOC, 83% on CityScapes), and, while intersection-over-union and a range of other metrics provide the general picture of model performance, in this paper we aim to extend them into other meaningful and important for applications characteristics, answering such questions as 'how accurate the model segmentation is on small objects in the general scene?', or 'what are the sources of uncertainty that cause the model to make an erroneous prediction?'. Besides establishing a methodology that covers the performance of a single model from different perspectives, we also showcase several extensions that can be worth pursuing in order to further improve current results in semantic segmentation.