 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Creative Generation on Stable Diffusion-based Models
Mar 30, 2025Recent text-to-image generative models, particularly Stable Diffusion and its distilled variants, have achieved impressive fidelity and strong text-image alignment. However, their creative capability remains constrained, as including `creative' in prompts seldom yields the desired results. This paper introduces C3 (Creative Concept Catalyst), a training-free approach designed to enhance creativity in Stable Diffusion-based models. C3 selectively amplifies features during the denoising process to foster more creative outputs. We offer practical guidelines for choosing amplification factors based on two main aspects of creativity. C3 is the first study to enhance creativity in diffusion models without extensive computational costs. We demonstrate its effectiveness across various Stable Diffusion-based models.
Diverse Rare Sample Generation with Pretrained GANs
Dec 27, 2024



Deep generative models are proficient in generating realistic data but struggle with producing rare samples in low density regions due to their scarcity of training datasets and the mode collapse problem. While recent methods aim to improve the fidelity of generated samples, they often reduce diversity and coverage by ignoring rare and novel samples. This study proposes a novel approach for generating diverse rare samples from high-resolution image datasets with pretrained GANs. Our method employs gradient-based optimization of latent vectors within a multi-objective framework and utilizes normalizing flows for density estimation on the feature space. This enables the generation of diverse rare images, with controllable parameters for rarity, diversity, and similarity to a reference image. We demonstrate the effectiveness of our approach both qualitatively and quantitatively across various datasets and GANs without retraining or fine-tuning the pretrained GANs.
Why Do Neural Language Models Still Need Commonsense Knowledge to Handle Semantic Variations in Question Answering?
Sep 01, 2022


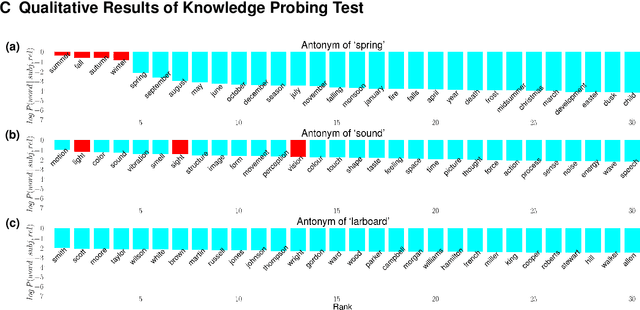
Many contextualized word representations are now learned by intricate neural network models, such as masked neural language models (MNLMs) which are made up of huge neural network structures and trained to restore the masked text. Such representations demonstrate superhuman performance in some reading comprehension (RC) tasks which extract a proper answer in the context given a question. However, identifying the detailed knowledge trained in MNLMs is challenging owing to numerous and intermingled model parameters. This paper provides new insights and empirical analyses on commonsense knowledge included in pretrained MNLMs. First, we use a diagnostic test that evaluates whether commonsense knowledge is properly trained in MNLMs. We observe that a large proportion of commonsense knowledge is not appropriately trained in MNLMs and MNLMs do not often understand the semantic meaning of relations accurately. In addition, we find that the MNLM-based RC models are still vulnerable to semantic variations that require commonsense knowledge. Finally, we discover the fundamental reason why some knowledge is not trained. We further suggest that utilizing an external commonsense knowledge repository can be an effective solution. We exemplify the possibility to overcome the limitations of the MNLM-based RC models by enriching text with the required knowledge from an external commonsense knowledge repository in controlled experiments.
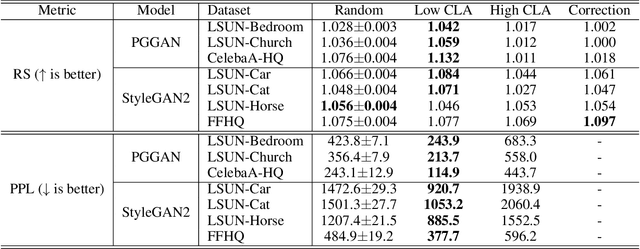
Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images
Jun 26, 2022
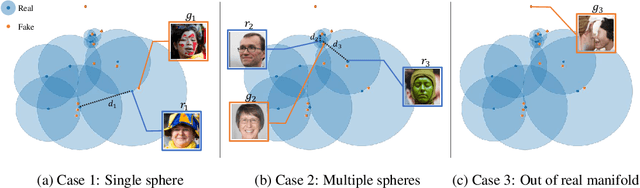

Evaluation metrics in image synthesis play a key role to measure performances of generative models. However, most metrics mainly focus on image fidelity. Existing diversity metrics are derived by comparing distributions, and thus they cannot quantify the diversity or rarity degree of each generated image. In this work, we propose a new evaluation metric, called `rarity score', to measure the individual rarity of each image synthesized by generative models. We first show empirical observation that common samples are close to each other and rare samples are far from each other in nearest-neighbor distances of feature space. We then use our metric to demonstrate that the extent to which different generative models produce rare images can be effectively compared. We also propose a method to compare rarities between datasets that share the same concept such as CelebA-HQ and FFHQ. Finally, we analyze the use of metrics in different designs of feature spaces to better understand the relationship between feature spaces and resulting sparse images. Code will be publicly available online for the research community.
An Unsupervised Way to Understand Artifact Generating Internal Units in Generative Neural Networks
Dec 16, 2021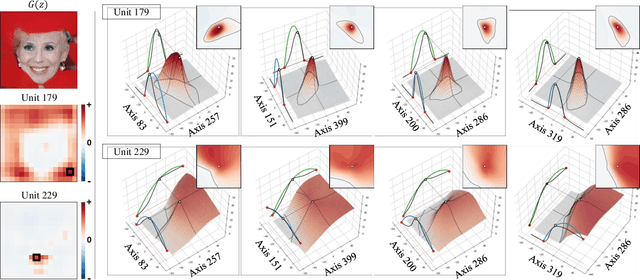

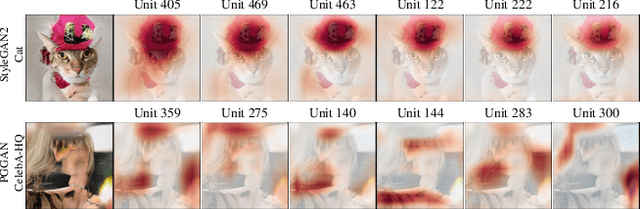
Despite significant improvements on the image generation performance of Generative Adversarial Networks (GANs), generations with low visual fidelity still have been observed. As widely used metrics for GANs focus more on the overall performance of the model, evaluation on the quality of individual generations or detection of defective generations is challenging. While recent studies try to detect featuremap units that cause artifacts and evaluate individual samples, these approaches require additional resources such as external networks or a number of training data to approximate the real data manifold. In this work, we propose the concept of local activation, and devise a metric on the local activation to detect artifact generations without additional supervision. We empirically verify that our approach can detect and correct artifact generations from GANs with various datasets. Finally, we discuss a geometrical analysis to partially reveal the relation between the proposed concept and low visual fidelity.
Automatic Correction of Internal Units in Generative Neural Networks
Apr 13, 2021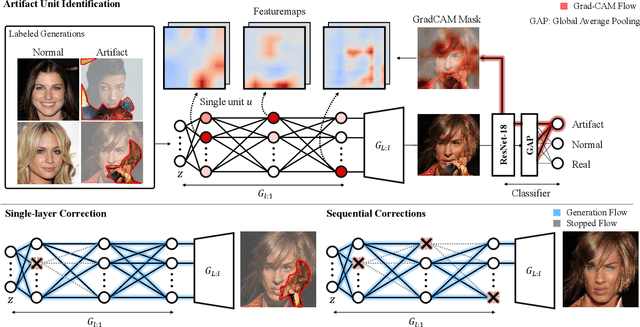



Generative Adversarial Networks (GANs) have shown satisfactory performance in synthetic image generation by devising complex network structure and adversarial training scheme. Even though GANs are able to synthesize realistic images, there exists a number of generated images with defective visual patterns which are known as artifacts. While most of the recent work tries to fix artifact generations by perturbing latent code, few investigate internal units of a generator to fix them. In this work, we devise a method that automatically identifies the internal units generating various types of artifact images. We further propose the sequential correction algorithm which adjusts the generation flow by modifying the detected artifact units to improve the quality of generation while preserving the original outline. Our method outperforms the baseline method in terms of FID-score and shows satisfactory results with human evaluation.
Why Do Masked Neural Language Models Still Need Common Sense Knowledge?
Nov 08, 2019

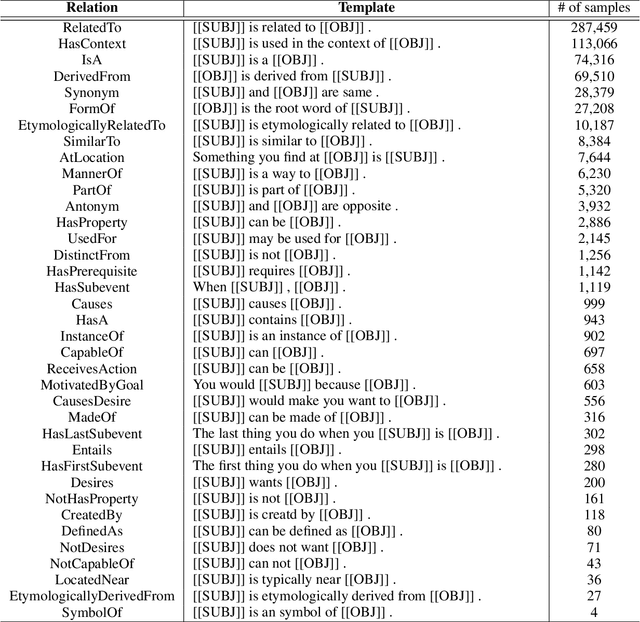

Currently, contextualized word representations are learned by intricate neural network models, such as masked neural language models (MNLMs). The new representations significantly enhanced the performance in automated question answering by reading paragraphs. However, identifying the detailed knowledge trained in the MNLMs is difficult owing to numerous and intermingled parameters. This paper provides empirical but insightful analyses on the pretrained MNLMs with respect to common sense knowledge. First, we propose a test that measures what types of common sense knowledge do pretrained MNLMs understand. From the test, we observed that MNLMs partially understand various types of common sense knowledge but do not accurately understand the semantic meaning of relations. In addition, based on the difficulty of the question-answering task problems, we observed that pretrained MLM-based models are still vulnerable to problems that require common sense knowledge. We also experimentally demonstrated that we can elevate existing MNLM-based models by combining knowledge from an external common sense repository.
Confirmatory Bayesian Online Change Point Detection in the Covariance Structure of Gaussian Processes
May 30, 2019

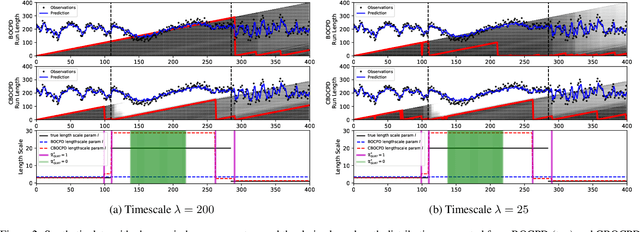
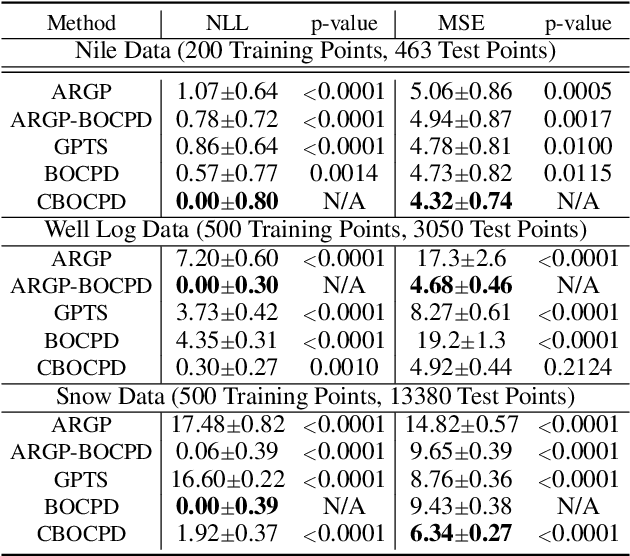
In the analysis of sequential data, the detection of abrupt changes is important in predicting future changes. In this paper, we propose statistical hypothesis tests for detecting covariance structure changes in locally smooth time series modeled by Gaussian Processes (GPs). We provide theoretically justified thresholds for the tests, and use them to improve Bayesian Online Change Point Detection (BOCPD) by confirming statistically significant changes and non-changes. Our Confirmatory BOCPD (CBOCPD) algorithm finds multiple structural breaks in GPs even when hyperparameters are not tuned precisely. We also provide conditions under which CBOCPD provides the lower prediction error compared to BOCPD. Experimental results on synthetic and real-world datasets show that our new tests correctly detect changes in the covariance structure in GPs. The proposed algorithm also outperforms existing methods for the prediction of nonstationarity in terms of both regression error and log likelihood.