 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Diffusion Planner for Reliable Behavior Synthesis by Automatic Detection of Infeasible Plans
Oct 30, 2023Diffusion-based planning has shown promising results in long-horizon, sparse-reward tasks by training trajectory diffusion models and conditioning the sampled trajectories using auxiliary guidance functions. However, due to their nature as generative models, diffusion models are not guaranteed to generate feasible plans, resulting in failed execution and precluding planners from being useful in safety-critical applications. In this work, we propose a novel approach to refine unreliable plans generated by diffusion models by providing refining guidance to error-prone plans. To this end, we suggest a new metric named restoration gap for evaluating the quality of individual plans generated by the diffusion model. A restoration gap is estimated by a gap predictor which produces restoration gap guidance to refine a diffusion planner. We additionally present an attribution map regularizer to prevent adversarial refining guidance that could be generated from the sub-optimal gap predictor, which enables further refinement of infeasible plans. We demonstrate the effectiveness of our approach on three different benchmarks in offline control settings that require long-horizon planning. We also illustrate that our approach presents explainability by presenting the attribution maps of the gap predictor and highlighting error-prone transitions, allowing for a deeper understanding of the generated plans.
Variational Curriculum Reinforcement Learning for Unsupervised Discovery of Skills
Oct 30, 2023Mutual information-based reinforcement learning (RL) has been proposed as a promising framework for retrieving complex skills autonomously without a task-oriented reward function through mutual information (MI) maximization or variational empowerment. However, learning complex skills is still challenging, due to the fact that the order of training skills can largely affect sample efficiency. Inspired by this, we recast variational empowerment as curriculum learning in goal-conditioned RL with an intrinsic reward function, which we name Variational Curriculum RL (VCRL). From this perspective, we propose a novel approach to unsupervised skill discovery based on information theory, called Value Uncertainty Variational Curriculum (VUVC). We prove that, under regularity conditions, VUVC accelerates the increase of entropy in the visited states compared to the uniform curriculum. We validate the effectiveness of our approach on complex navigation and robotic manipulation tasks in terms of sample efficiency and state coverage speed. We also demonstrate that the skills discovered by our method successfully complete a real-world robot navigation task in a zero-shot setup and that incorporating these skills with a global planner further increases the performance.
Adaptive and Explainable Deployment of Navigation Skills via Hierarchical Deep Reinforcement Learning
May 31, 2023For robotic vehicles to navigate robustly and safely in unseen environments, it is crucial to decide the most suitable navigation policy. However, most existing deep reinforcement learning based navigation policies are trained with a hand-engineered curriculum and reward function which are difficult to be deployed in a wide range of real-world scenarios. In this paper, we propose a framework to learn a family of low-level navigation policies and a high-level policy for deploying them. The main idea is that, instead of learning a single navigation policy with a fixed reward function, we simultaneously learn a family of policies that exhibit different behaviors with a wide range of reward functions. We then train the high-level policy which adaptively deploys the most suitable navigation skill. We evaluate our approach in simulation and the real world and demonstrate that our method can learn diverse navigation skills and adaptively deploy them. We also illustrate that our proposed hierarchical learning framework presents explainability by providing semantics for the behavior of an autonomous agent.
Confirmatory Bayesian Online Change Point Detection in the Covariance Structure of Gaussian Processes
May 30, 2019

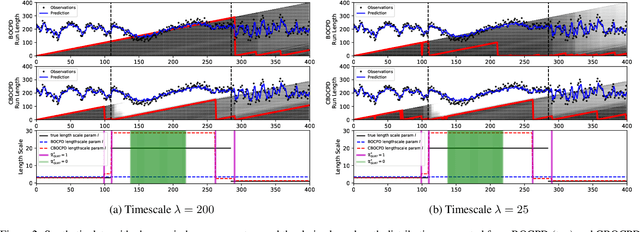
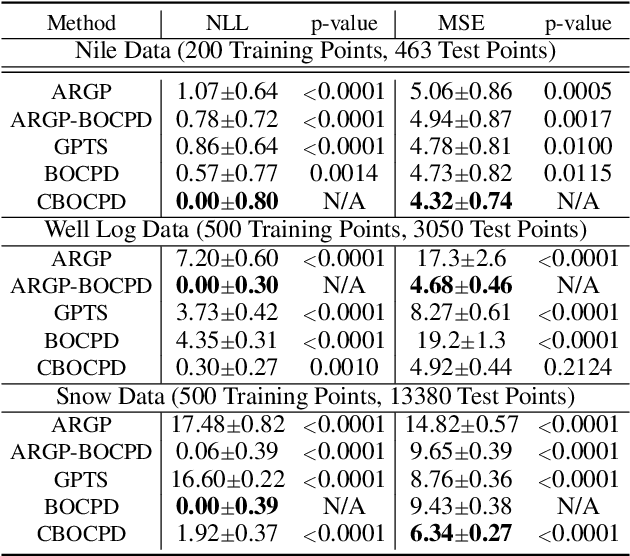
In the analysis of sequential data, the detection of abrupt changes is important in predicting future changes. In this paper, we propose statistical hypothesis tests for detecting covariance structure changes in locally smooth time series modeled by Gaussian Processes (GPs). We provide theoretically justified thresholds for the tests, and use them to improve Bayesian Online Change Point Detection (BOCPD) by confirming statistically significant changes and non-changes. Our Confirmatory BOCPD (CBOCPD) algorithm finds multiple structural breaks in GPs even when hyperparameters are not tuned precisely. We also provide conditions under which CBOCPD provides the lower prediction error compared to BOCPD. Experimental results on synthetic and real-world datasets show that our new tests correctly detect changes in the covariance structure in GPs. The proposed algorithm also outperforms existing methods for the prediction of nonstationarity in terms of both regression error and log likelihood.