 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Label Shift in Tabular In-Context Learning via Test-Time Posterior Adjustment
May 06, 2026TabPFN has recently gained attention as a foundation model for tabular datasets, achieving strong performance by leveraging in-context learning on synthetic data. However, we find that TabPFN is vulnerable to label shift, often overfitting to the majority class in the training dataset. To address this limitation, we propose DistPFN, the first test-time posterior adjustment method designed for tabular foundation models. DistPFN rescales predicted class probabilities by downweighting the influence of the training prior (i.e., the class distribution of the context) and emphasizing the contribution of the model's predicted posterior, without architectural modification or additional training. We further introduce DistPFN-T, which incorporates temperature scaling to adaptively control the adjustment strength based on the discrepancy between prior and posterior. We evaluate our methods on over 250 OpenML datasets, demonstrating substantial improvements for various TabPFN-based models in classification tasks under label shift, while maintaining strong performance in standard settings without label shift. Code is available at this repository: https://github.com/seunghan96/DistPFN.
FinSTaR: Towards Financial Reasoning with Time Series Reasoning Models
May 05, 2026Time series (TS) reasoning models (TSRMs) have shown promising capabilities in general domains, yet they consistently fail on financial domain, which exhibit unique characteristics. We propose a general 2x2 capability taxonomy for TSRMs by crossing 1) single-entity vs. multi-entity analysis with 2) assessment of the current state vs. prediction of future behavior. We instantiate this taxonomy in the financial domain -- where the distinction between deterministic assessment and stochastic prediction is particularly critical -- as ten financial reasoning tasks, forming the FinTSR-Bench benchmark based on S&P stocks. To this end, we propose FinSTaR (Financial Time Series Thinking and Reasoning), trained on FinTSR-Bench with distinct chain-of-thought (CoT) strategies tailored to each category. For assessment, which is deterministic (i.e., computable from observable data), we employ Compute-in-CoT, a programmatic CoT that enables models to derive answers directly from raw prices. For prediction, which is inherently stochastic (i.e., subject to unobservable factors), we adopt Scenario-Aware CoT, which generates diverse scenarios before making a judgment, mirroring how financial analysts reason under uncertainty. The proposed method achieves 78.9% average accuracy on FinTSR-Bench, substantially outperforming LLM and TSRM baselines. Furthermore, we show that the four capability categories are complementary and mutually reinforcing through joint training, and that Scenario-Aware CoT consistently improves prediction accuracy over standard CoT. Code is publicly available at: https://github.com/seunghan96/FinSTaR.
Rethinking Multimodal Fusion for Time Series: Auxiliary Modalities Need Constrained Fusion
Mar 23, 2026Recent advances in multimodal learning have motivated the integration of auxiliary modalities such as text or vision into time series (TS) forecasting. However, most existing methods provide limited gains, often improving performance only in specific datasets or relying on architecture-specific designs that limit generalization. In this paper, we show that multimodal models with naive fusion strategies (e.g., simple addition or concatenation) often underperform unimodal TS models, which we attribute to the uncontrolled integration of auxiliary modalities which may introduce irrelevant information. Motivated by this observation, we explore various constrained fusion methods designed to control such integration and find that they consistently outperform naive fusion methods. Furthermore, we propose Controlled Fusion Adapter (CFA), a simple plug-in method that enables controlled cross-modal interactions without modifying the TS backbone, integrating only relevant textual information aligned with TS dynamics. CFA employs low-rank adapters to filter irrelevant textual information before fusing it into temporal representations. We conduct over 20K experiments across various datasets and TS/text models, demonstrating the effectiveness of the constrained fusion methods including CFA. Code is publicly available at: https://github.com/seunghan96/cfa/.
Cross-RAG: Zero-Shot Retrieval-Augmented Time Series Forecasting via Cross-Attention
Mar 16, 2026Recent advances in time series foundation models (TSFMs) demonstrate strong expressive capacity through large-scale pretraining across diverse time series domains. Zero-shot time series forecasting with TSFMs, however, exhibits limited generalization to unseen datasets, which retrieval-augmented forecasting addresses by leveraging an external knowledge base. Existing approaches rely on a fixed number of retrieved samples that may introduce irrelevant information. To this end, we propose Cross-RAG, a zero-shot retrieval-augmented forecasting framework that selectively attends to query-relevant retrieved samples. Cross-RAG models input-level relevance between the query and retrieved samples via query-retrieval cross-attention, while jointly incorporating information from the query and retrieved samples. Extensive experiments demonstrate that Cross-RAG consistently improves zero-shot forecasting performance across various TSFMs and RAG methods, and additional analyses confirm its effectiveness across diverse retrieval scenarios. Code is available at https://github.com/seunghan96/cross-rag/.
FinTexTS: Financial Text-Paired Time-Series Dataset via Semantic-Based and Multi-Level Pairing
Mar 03, 2026The financial domain involves a variety of important time-series problems. Recently, time-series analysis methods that jointly leverage textual and numerical information have gained increasing attention. Accordingly, numerous efforts have been made to construct text-paired time-series datasets in the financial domain. However, financial markets are characterized by complex interdependencies, in which a company's stock price is influenced not only by company-specific events but also by events in other companies and broader macroeconomic factors. Existing approaches that pair text with financial time-series data based on simple keyword matching often fail to capture such complex relationships. To address this limitation, we propose a semantic-based and multi-level pairing framework. Specifically, we extract company-specific context for the target company from SEC filings and apply an embedding-based matching mechanism to retrieve semantically relevant news articles based on this context. Furthermore, we classify news articles into four levels (macro-level, sector-level, related company-level, and target-company level) using large language models (LLMs), enabling multi-level pairing of news articles with the target company. Applying this framework to publicly-available news datasets, we construct \textbf{FinTexTS}, a new large-scale text-paired stock price dataset. Experimental results on \textbf{FinTexTS} demonstrate the effectiveness of our semantic-based and multi-level pairing strategy in stock price forecasting. In addition to publicly-available news underlying \textbf{FinTexTS}, we show that applying our method to proprietary yet carefully curated news sources leads to higher-quality paired data and improved stock price forecasting performance.
EXAONE Path 2.0: Pathology Foundation Model with End-to-End Supervision
Jul 09, 2025In digital pathology, whole-slide images (WSIs) are often difficult to handle due to their gigapixel scale, so most approaches train patch encoders via self-supervised learning (SSL) and then aggregate the patch-level embeddings via multiple instance learning (MIL) or slide encoders for downstream tasks. However, patch-level SSL may overlook complex domain-specific features that are essential for biomarker prediction, such as mutation status and molecular characteristics, as SSL methods rely only on basic augmentations selected for natural image domains on small patch-level area. Moreover, SSL methods remain less data efficient than fully supervised approaches, requiring extensive computational resources and datasets to achieve competitive performance. To address these limitations, we present EXAONE Path 2.0, a pathology foundation model that learns patch-level representations under direct slide-level supervision. Using only 37k WSIs for training, EXAONE Path 2.0 achieves state-of-the-art average performance across 10 biomarker prediction tasks, demonstrating remarkable data efficiency.
Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images
Jun 26, 2022
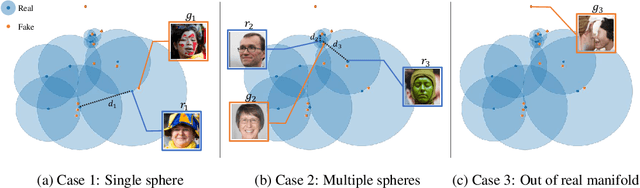
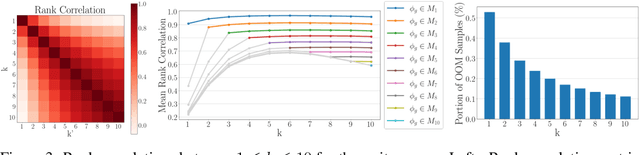

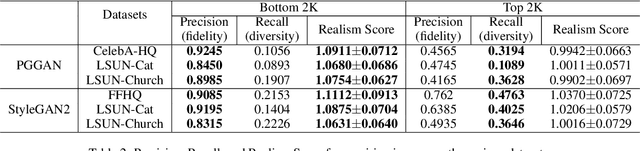
Evaluation metrics in image synthesis play a key role to measure performances of generative models. However, most metrics mainly focus on image fidelity. Existing diversity metrics are derived by comparing distributions, and thus they cannot quantify the diversity or rarity degree of each generated image. In this work, we propose a new evaluation metric, called `rarity score', to measure the individual rarity of each image synthesized by generative models. We first show empirical observation that common samples are close to each other and rare samples are far from each other in nearest-neighbor distances of feature space. We then use our metric to demonstrate that the extent to which different generative models produce rare images can be effectively compared. We also propose a method to compare rarities between datasets that share the same concept such as CelebA-HQ and FFHQ. Finally, we analyze the use of metrics in different designs of feature spaces to better understand the relationship between feature spaces and resulting sparse images. Code will be publicly available online for the research community.
Can We Find Neurons that Cause Unrealistic Images in Deep Generative Networks?
Jan 20, 2022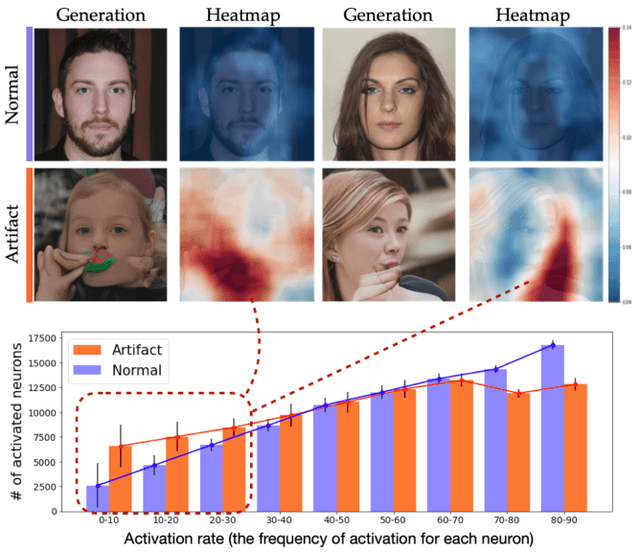
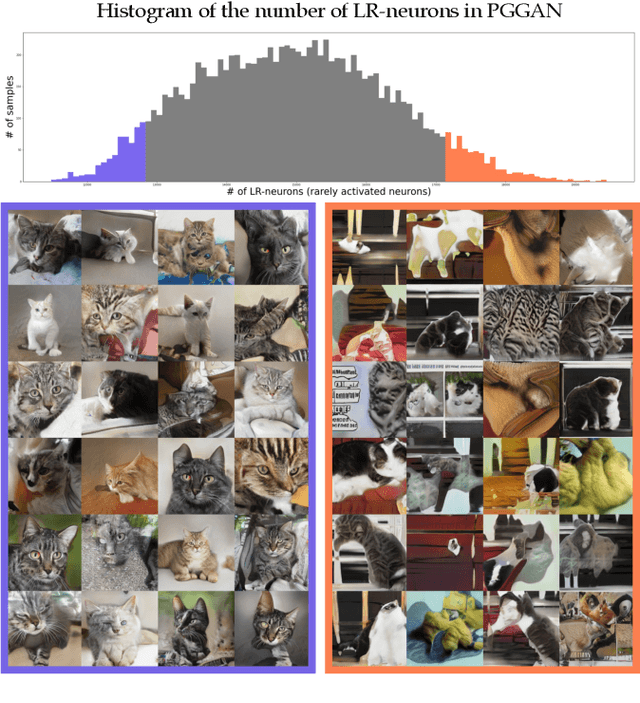
Even though image generation with Generative Adversarial Networks has been showing remarkable ability to generate high-quality images, GANs do not always guarantee photorealistic images will be generated. Sometimes they generate images that have defective or unnatural objects, which are referred to as 'artifacts'. Research to determine why the artifacts emerge and how they can be detected and removed has not been sufficiently carried out. To analyze this, we first hypothesize that rarely activated neurons and frequently activated neurons have different purposes and responsibilities for the progress of generating images. By analyzing the statistics and the roles for those neurons, we empirically show that rarely activated neurons are related to failed results of making diverse objects and lead to artifacts. In addition, we suggest a correction method, called 'sequential ablation', to repair the defective part of the generated images without complex computational cost and manual efforts.
Automatic Correction of Internal Units in Generative Neural Networks
Apr 13, 2021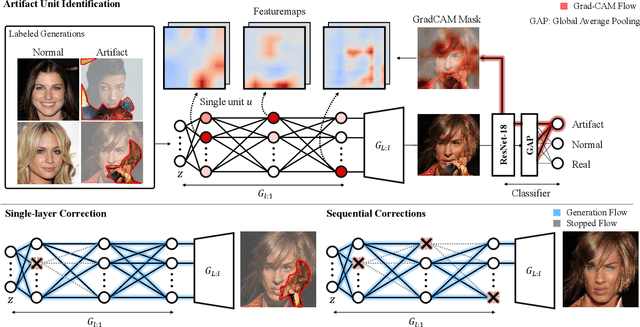



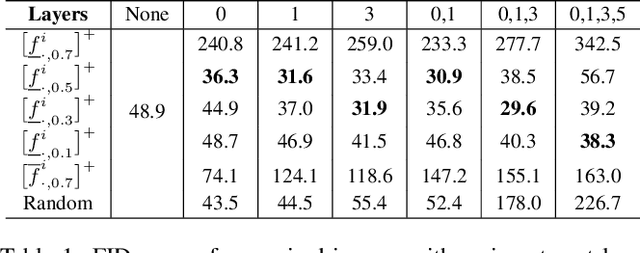
Generative Adversarial Networks (GANs) have shown satisfactory performance in synthetic image generation by devising complex network structure and adversarial training scheme. Even though GANs are able to synthesize realistic images, there exists a number of generated images with defective visual patterns which are known as artifacts. While most of the recent work tries to fix artifact generations by perturbing latent code, few investigate internal units of a generator to fix them. In this work, we devise a method that automatically identifies the internal units generating various types of artifact images. We further propose the sequential correction algorithm which adjusts the generation flow by modifying the detected artifact units to improve the quality of generation while preserving the original outline. Our method outperforms the baseline method in terms of FID-score and shows satisfactory results with human evaluation.