 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship Between Adversarial Robustness and Decision Region in Deep Neural Network
Jul 07, 2022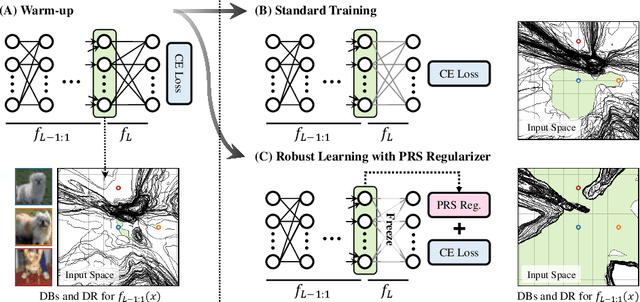
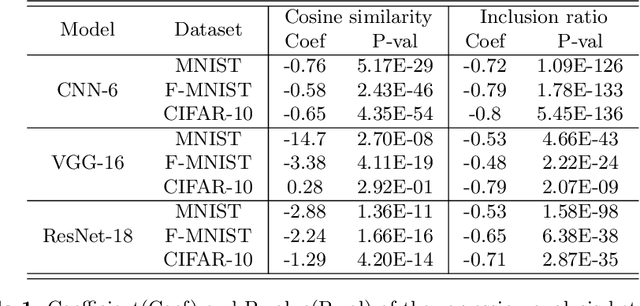
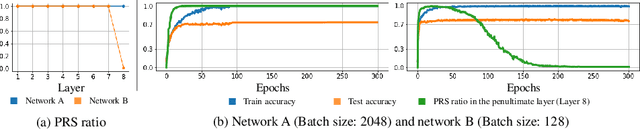
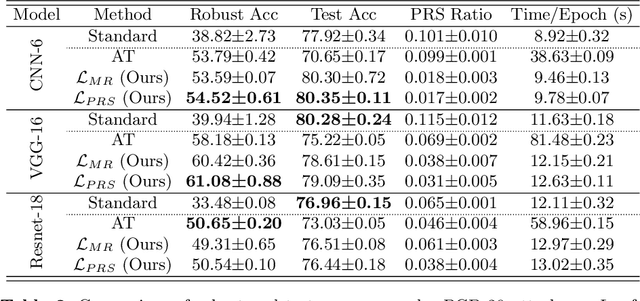
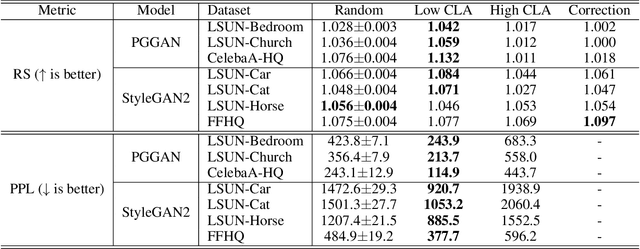
In general, Deep Neural Networks (DNNs) are evaluated by the generalization performance measured on unseen data excluded from the training phase. Along with the development of DNNs, the generalization performance converges to the state-of-the-art and it becomes difficult to evaluate DNNs solely based on this metric. The robustness against adversarial attack has been used as an additional metric to evaluate DNNs by measuring their vulnerability. However, few studies have been performed to analyze the adversarial robustness in terms of the geometry in DNNs. In this work, we perform an empirical study to analyze the internal properties of DNNs that affect model robustness under adversarial attacks. In particular, we propose the novel concept of the Populated Region Set (PRS), where training samples are populated more frequently, to represent the internal properties of DNNs in a practical setting. From systematic experiments with the proposed concept, we provide empirical evidence to validate that a low PRS ratio has a strong relationship with the adversarial robustness of DNNs. We also devise PRS regularizer leveraging the characteristics of PRS to improve the adversarial robustness without adversarial training.
An Unsupervised Way to Understand Artifact Generating Internal Units in Generative Neural Networks
Dec 16, 2021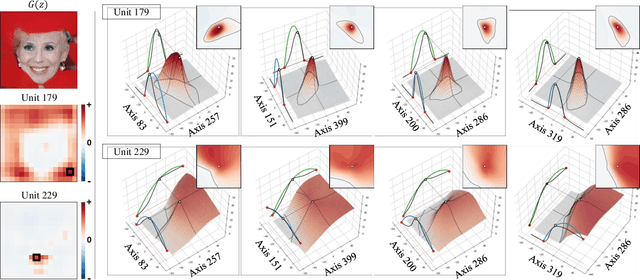

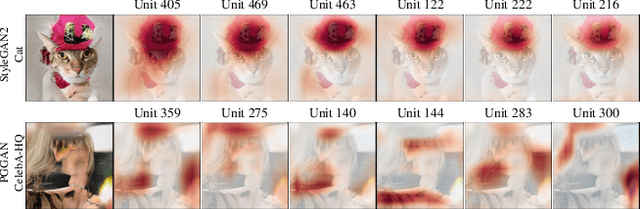
Despite significant improvements on the image generation performance of Generative Adversarial Networks (GANs), generations with low visual fidelity still have been observed. As widely used metrics for GANs focus more on the overall performance of the model, evaluation on the quality of individual generations or detection of defective generations is challenging. While recent studies try to detect featuremap units that cause artifacts and evaluate individual samples, these approaches require additional resources such as external networks or a number of training data to approximate the real data manifold. In this work, we propose the concept of local activation, and devise a metric on the local activation to detect artifact generations without additional supervision. We empirically verify that our approach can detect and correct artifact generations from GANs with various datasets. Finally, we discuss a geometrical analysis to partially reveal the relation between the proposed concept and low visual fidelity.
Automatic Correction of Internal Units in Generative Neural Networks
Apr 13, 2021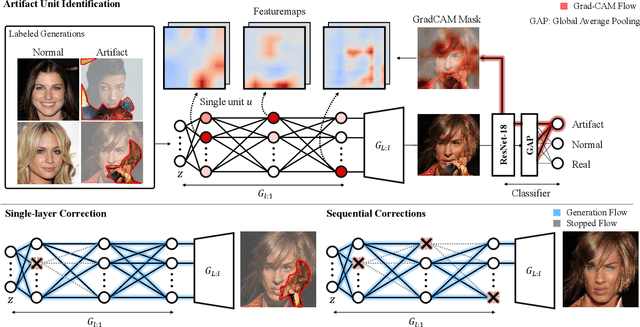



Generative Adversarial Networks (GANs) have shown satisfactory performance in synthetic image generation by devising complex network structure and adversarial training scheme. Even though GANs are able to synthesize realistic images, there exists a number of generated images with defective visual patterns which are known as artifacts. While most of the recent work tries to fix artifact generations by perturbing latent code, few investigate internal units of a generator to fix them. In this work, we devise a method that automatically identifies the internal units generating various types of artifact images. We further propose the sequential correction algorithm which adjusts the generation flow by modifying the detected artifact units to improve the quality of generation while preserving the original outline. Our method outperforms the baseline method in terms of FID-score and shows satisfactory results with human evaluation.
An Efficient Explorative Sampling Considering the Generative Boundaries of Deep Generative Neural Networks
Dec 12, 2019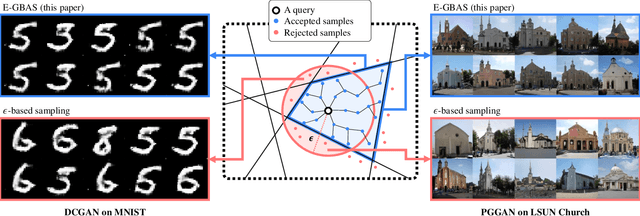


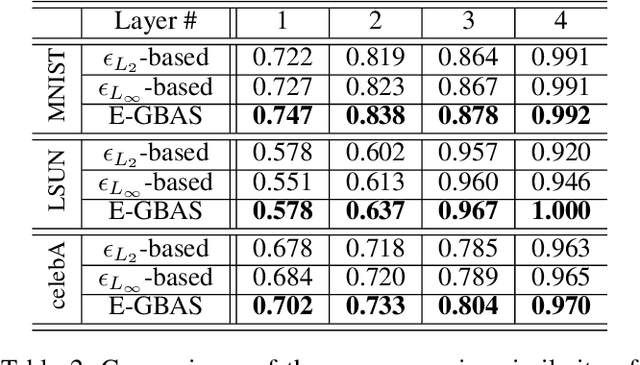
Deep generative neural networks (DGNNs) have achieved realistic and high-quality data generation. In particular, the adversarial training scheme has been applied to many DGNNs and has exhibited powerful performance. Despite of recent advances in generative networks, identifying the image generation mechanism still remains challenging. In this paper, we present an explorative sampling algorithm to analyze generation mechanism of DGNNs. Our method efficiently obtains samples with identical attributes from a query image in a perspective of the trained model. We define generative boundaries which determine the activation of nodes in the internal layer and probe inside the model with this information. To handle a large number of boundaries, we obtain the essential set of boundaries using optimization. By gathering samples within the region surrounded by generative boundaries, we can empirically reveal the characteristics of the internal layers of DGNNs. We also demonstrate that our algorithm can find more homogeneous, the model specific samples compared to the variations of {\epsilon}-based sampling method.