 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection
May 26, 2023



Anomaly detection is crucial to the advanced identification of product defects such as incorrect parts, misaligned components, and damages in industrial manufacturing. Due to the rare observations and unknown types of defects, anomaly detection is considered to be challenging in machine learning. To overcome this difficulty, recent approaches utilize the common visual representations from natural image datasets and distill the relevant features. However, existing approaches still have the discrepancy between the pre-trained feature and the target data, or require the input augmentation which should be carefully designed particularly for the industrial dataset. In this paper, we introduce ReConPatch, which constructs discriminative features for anomaly detection by training a linear modulation attached to a pre-trained model. ReConPatch employs contrastive representation learning to collect and distribute features in a way that produces a target-oriented and easily separable representation. To address the absence of labeled pairs for the contrastive learning, we utilize two similarity measures, pairwise and contextual similarities, between data representations as a pseudo-label. Unlike previous work, ReConPatch achieves robust anomaly detection performance without extensive input augmentation. Our method achieves the state-of-the-art anomaly detection performance (99.72%) for the widely used and challenging MVTec AD dataset.
On the Relationship Between Adversarial Robustness and Decision Region in Deep Neural Network
Jul 07, 2022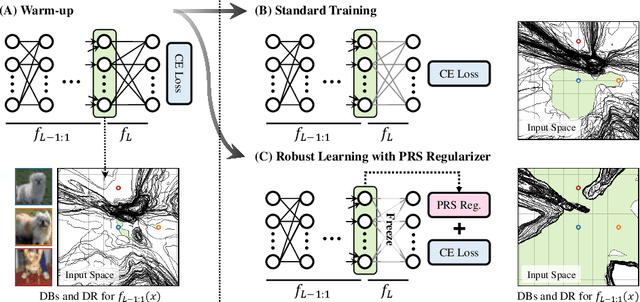
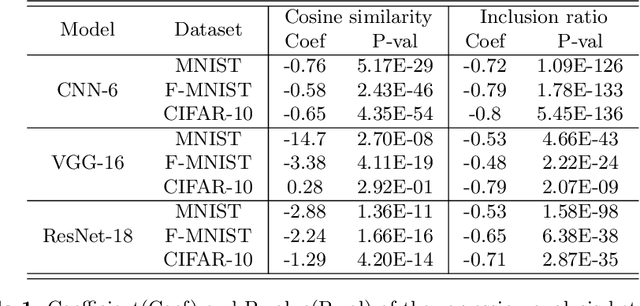
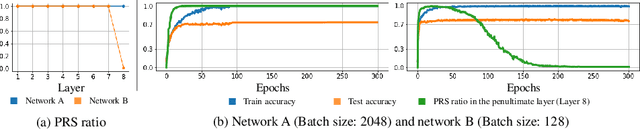
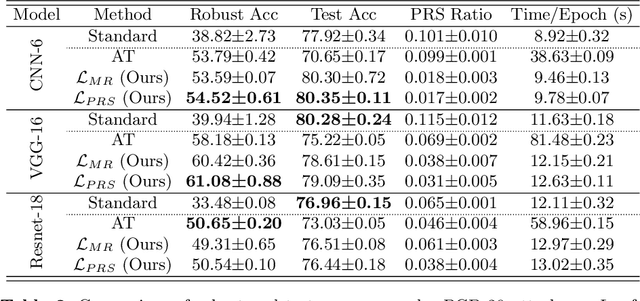
In general, Deep Neural Networks (DNNs) are evaluated by the generalization performance measured on unseen data excluded from the training phase. Along with the development of DNNs, the generalization performance converges to the state-of-the-art and it becomes difficult to evaluate DNNs solely based on this metric. The robustness against adversarial attack has been used as an additional metric to evaluate DNNs by measuring their vulnerability. However, few studies have been performed to analyze the adversarial robustness in terms of the geometry in DNNs. In this work, we perform an empirical study to analyze the internal properties of DNNs that affect model robustness under adversarial attacks. In particular, we propose the novel concept of the Populated Region Set (PRS), where training samples are populated more frequently, to represent the internal properties of DNNs in a practical setting. From systematic experiments with the proposed concept, we provide empirical evidence to validate that a low PRS ratio has a strong relationship with the adversarial robustness of DNNs. We also devise PRS regularizer leveraging the characteristics of PRS to improve the adversarial robustness without adversarial training.
An Efficient Explorative Sampling Considering the Generative Boundaries of Deep Generative Neural Networks
Dec 12, 2019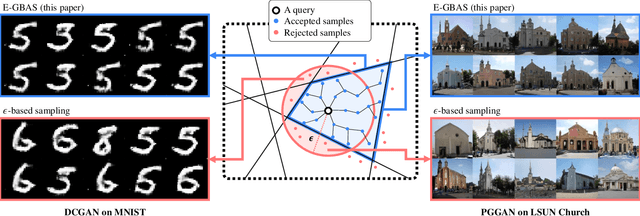


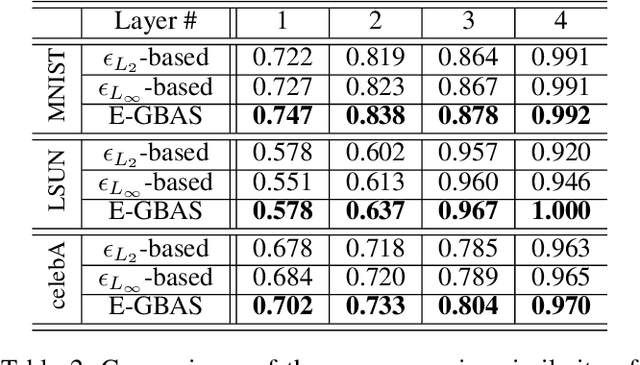
Deep generative neural networks (DGNNs) have achieved realistic and high-quality data generation. In particular, the adversarial training scheme has been applied to many DGNNs and has exhibited powerful performance. Despite of recent advances in generative networks, identifying the image generation mechanism still remains challenging. In this paper, we present an explorative sampling algorithm to analyze generation mechanism of DGNNs. Our method efficiently obtains samples with identical attributes from a query image in a perspective of the trained model. We define generative boundaries which determine the activation of nodes in the internal layer and probe inside the model with this information. To handle a large number of boundaries, we obtain the essential set of boundaries using optimization. By gathering samples within the region surrounded by generative boundaries, we can empirically reveal the characteristics of the internal layers of DGNNs. We also demonstrate that our algorithm can find more homogeneous, the model specific samples compared to the variations of {\epsilon}-based sampling method.