 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Distributed Representations of Concepts in Deep Neural Networks without Supervision
Dec 28, 2023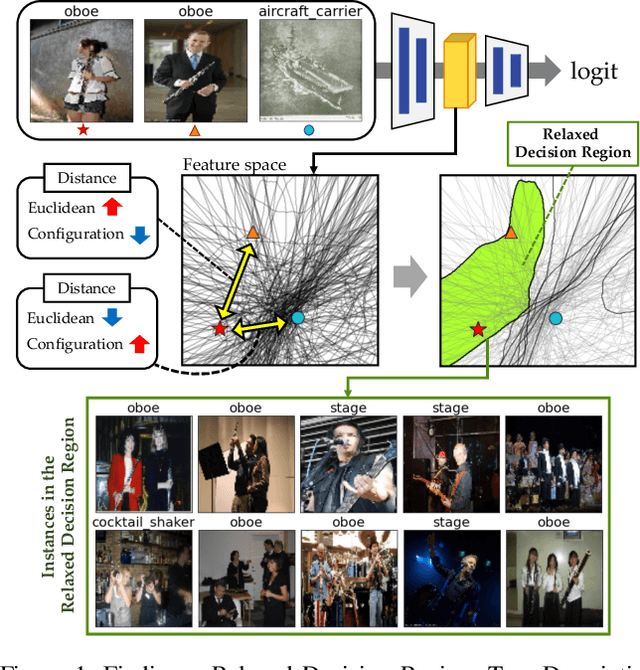
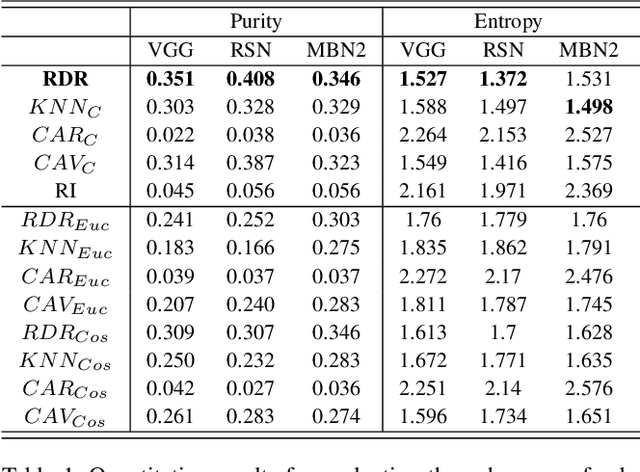
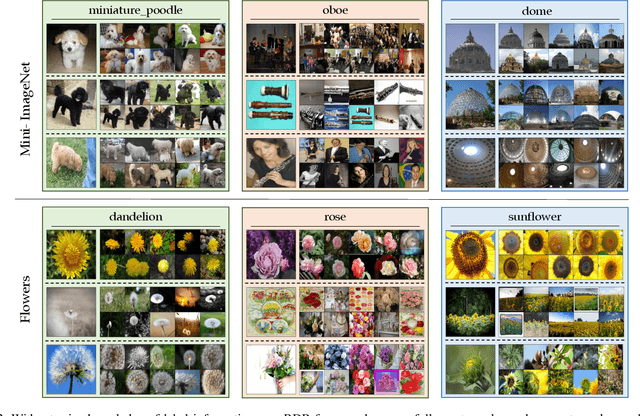
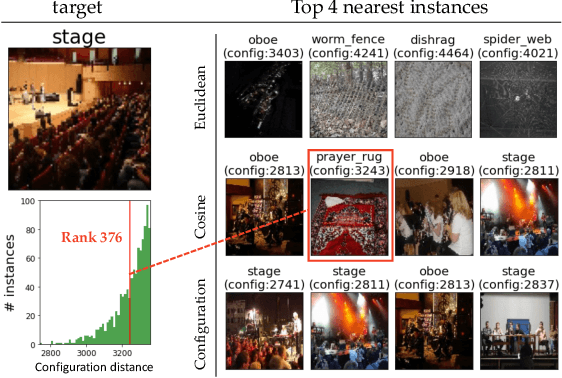
Understanding intermediate representations of the concepts learned by deep learning classifiers is indispensable for interpreting general model behaviors. Existing approaches to reveal learned concepts often rely on human supervision, such as pre-defined concept sets or segmentation processes. In this paper, we propose a novel unsupervised method for discovering distributed representations of concepts by selecting a principal subset of neurons. Our empirical findings demonstrate that instances with similar neuron activation states tend to share coherent concepts. Based on the observations, the proposed method selects principal neurons that construct an interpretable region, namely a Relaxed Decision Region (RDR), encompassing instances with coherent concepts in the feature space. It can be utilized to identify unlabeled subclasses within data and to detect the causes of misclassifications. Furthermore, the applicability of our method across various layers discloses distinct distributed representations over the layers, which provides deeper insights into the internal mechanisms of the deep learning model.
Edge-oriented Implicit Neural Representation with Channel Tuning
Sep 22, 2022



Implicit neural representation, which expresses an image as a continuous function rather than a discrete grid form, is widely used for image processing. Despite its outperforming results, there are still remaining limitations on restoring clear shapes of a given signal such as the edges of an image. In this paper, we propose Gradient Magnitude Adjustment algorithm which calculates the gradient of an image for training the implicit representation. In addition, we propose Edge-oriented Representation Network (EoREN) that can reconstruct the image with clear edges by fitting gradient information (Edge-oriented module). Furthermore, we add Channel-tuning module to adjust the distribution of given signals so that it solves a chronic problem of fitting gradients. By separating backpropagation paths of the two modules, EoREN can learn true color of the image without hindering the role for gradients. We qualitatively show that our model can reconstruct complex signals and demonstrate general reconstruction ability of our model with quantitative results.
Can We Find Neurons that Cause Unrealistic Images in Deep Generative Networks?
Jan 20, 2022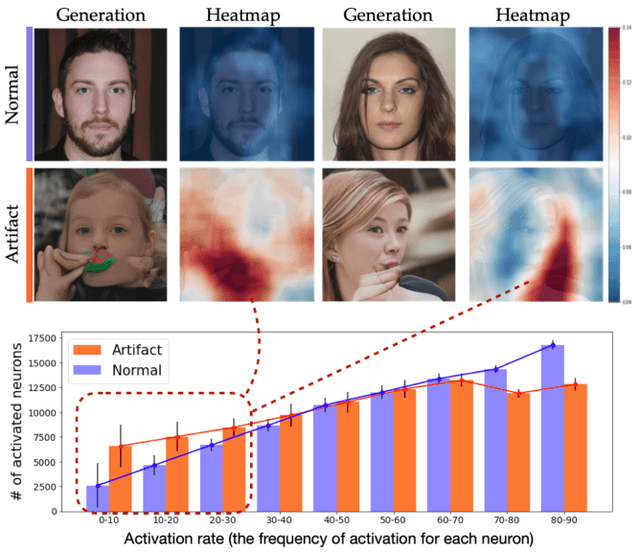
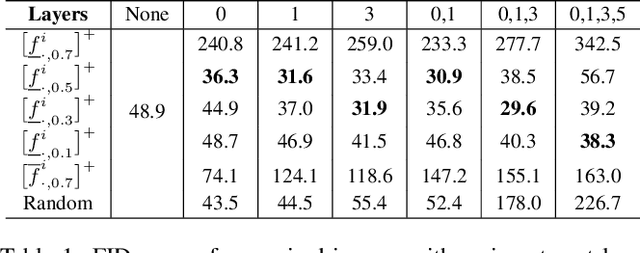
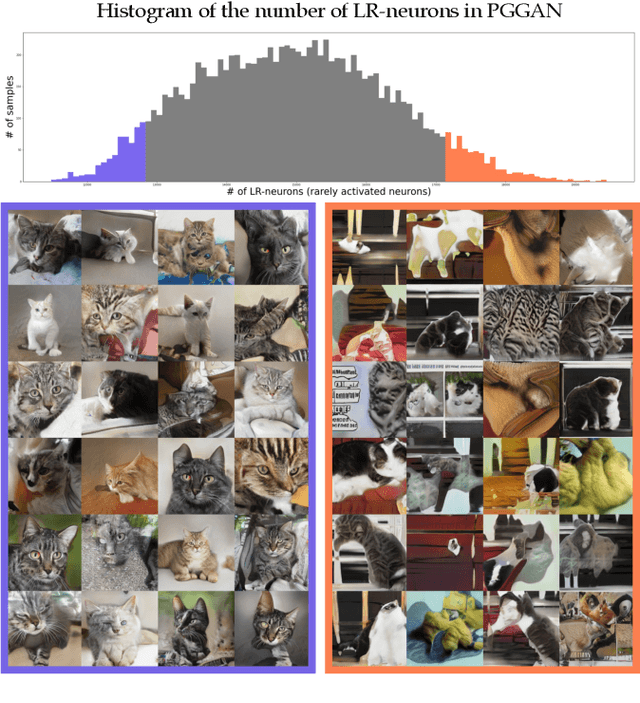
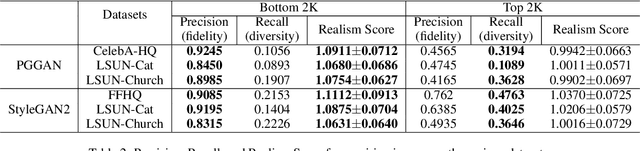
Even though image generation with Generative Adversarial Networks has been showing remarkable ability to generate high-quality images, GANs do not always guarantee photorealistic images will be generated. Sometimes they generate images that have defective or unnatural objects, which are referred to as 'artifacts'. Research to determine why the artifacts emerge and how they can be detected and removed has not been sufficiently carried out. To analyze this, we first hypothesize that rarely activated neurons and frequently activated neurons have different purposes and responsibilities for the progress of generating images. By analyzing the statistics and the roles for those neurons, we empirically show that rarely activated neurons are related to failed results of making diverse objects and lead to artifacts. In addition, we suggest a correction method, called 'sequential ablation', to repair the defective part of the generated images without complex computational cost and manual efforts.