 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFGuard: A Generative Framework with Privacy and Fairness Safeguards
Oct 03, 2024



Generative models must ensure both privacy and fairness for Trustworthy AI. While these goals have been pursued separately, recent studies propose to combine existing privacy and fairness techniques to achieve both goals. However, naively combining these techniques can be insufficient due to privacy-fairness conflicts, where a sample in a minority group may be amplified for fairness, only to be suppressed for privacy. We demonstrate how these conflicts lead to adverse effects, such as privacy violations and unexpected fairness-utility tradeoffs. To mitigate these risks, we propose PFGuard, a generative framework with privacy and fairness safeguards, which simultaneously addresses privacy, fairness, and utility. By using an ensemble of multiple teacher models, PFGuard balances privacy-fairness conflicts between fair and private training stages and achieves high utility based on ensemble learning. Extensive experiments show that PFGuard successfully generates synthetic data on high-dimensional data while providing both fairness convergence and strict DP guarantees - the first of its kind to our knowledge.
LEVI: Generalizable Fine-tuning via Layer-wise Ensemble of Different Views
Feb 07, 2024



Fine-tuning is becoming widely used for leveraging the power of pre-trained foundation models in new downstream tasks. While there are many successes of fine-tuning on various tasks, recent studies have observed challenges in the generalization of fine-tuned models to unseen distributions (i.e., out-of-distribution; OOD). To improve OOD generalization, some previous studies identify the limitations of fine-tuning data and regulate fine-tuning to preserve the general representation learned from pre-training data. However, potential limitations in the pre-training data and models are often ignored. In this paper, we contend that overly relying on the pre-trained representation may hinder fine-tuning from learning essential representations for downstream tasks and thus hurt its OOD generalization. It can be especially catastrophic when new tasks are from different (sub)domains compared to pre-training data. To address the issues in both pre-training and fine-tuning data, we propose a novel generalizable fine-tuning method LEVI, where the pre-trained model is adaptively ensembled layer-wise with a small task-specific model, while preserving training and inference efficiencies. By combining two complementing models, LEVI effectively suppresses problematic features in both the fine-tuning data and pre-trained model and preserves useful features for new tasks. Broad experiments with large language and vision models show that LEVI greatly improves fine-tuning generalization via emphasizing different views from fine-tuning data and pre-trained features.
Improving Fair Training under Correlation Shifts
Feb 05, 2023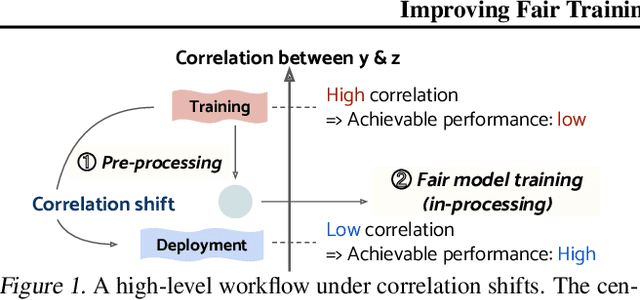
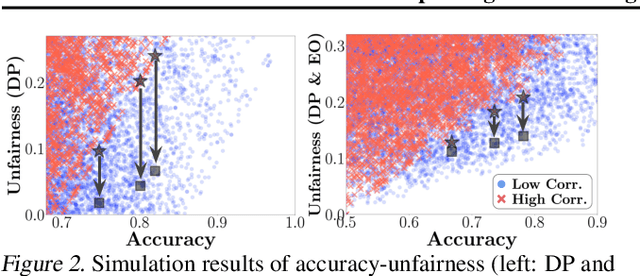
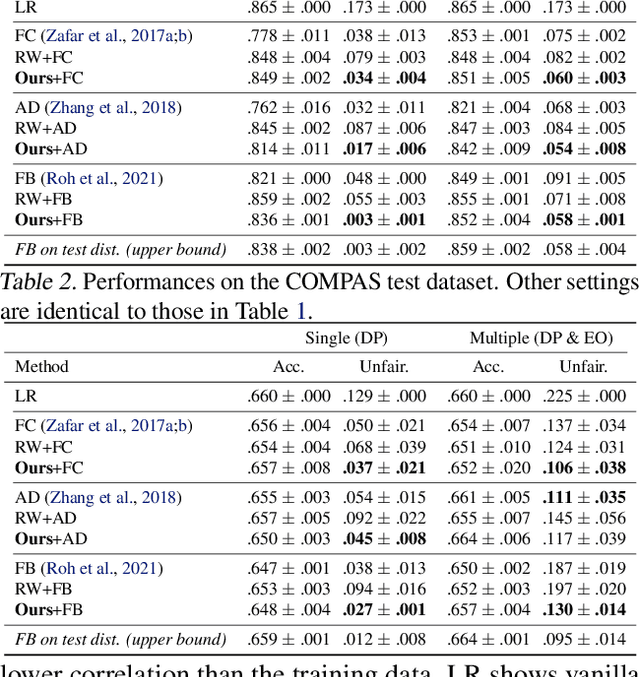
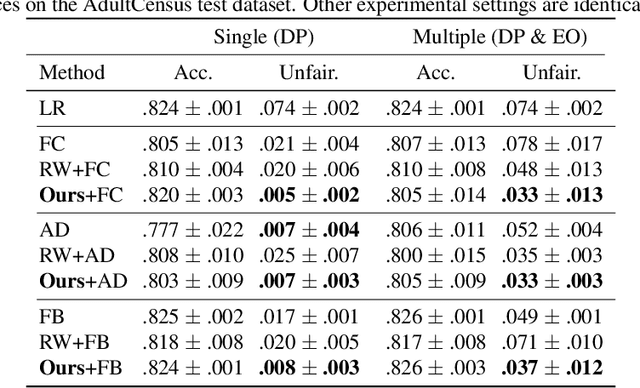
Model fairness is an essential element for Trustworthy AI. While many techniques for model fairness have been proposed, most of them assume that the training and deployment data distributions are identical, which is often not true in practice. In particular, when the bias between labels and sensitive groups changes, the fairness of the trained model is directly influenced and can worsen. We make two contributions for solving this problem. First, we analytically show that existing in-processing fair algorithms have fundamental limits in accuracy and group fairness. We introduce the notion of correlation shifts, which can explicitly capture the change of the above bias. Second, we propose a novel pre-processing step that samples the input data to reduce correlation shifts and thus enables the in-processing approaches to overcome their limitations. We formulate an optimization problem for adjusting the data ratio among labels and sensitive groups to reflect the shifted correlation. A key benefit of our approach lies in decoupling the roles of pre- and in-processing approaches: correlation adjustment via pre-processing and unfairness mitigation on the processed data via in-processing. Experiments show that our framework effectively improves existing in-processing fair algorithms w.r.t. accuracy and fairness, both on synthetic and real datasets.
Data Collection and Quality Challenges in Deep Learning: A Data-Centric AI Perspective
Dec 13, 2021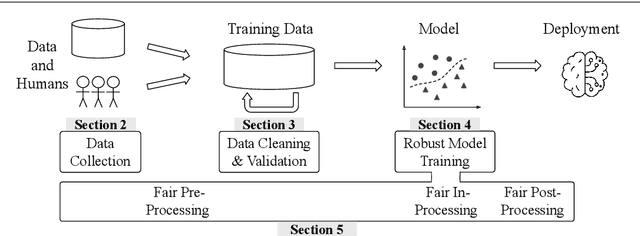
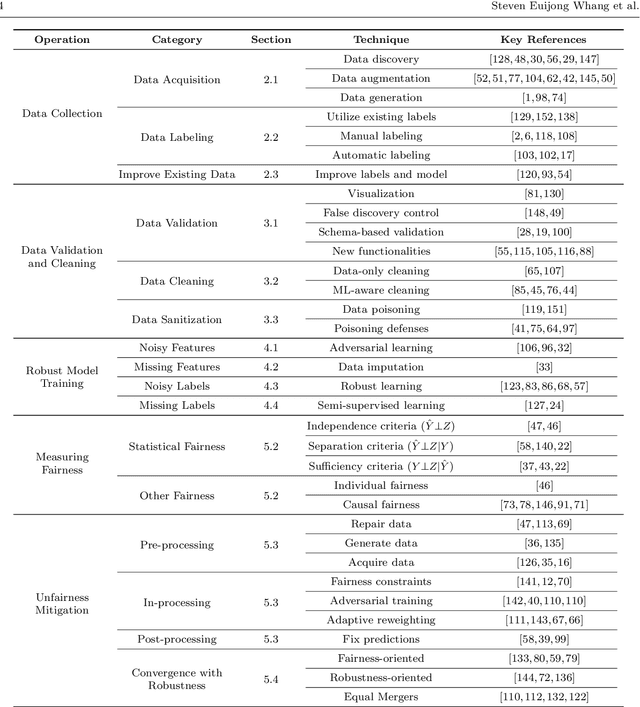
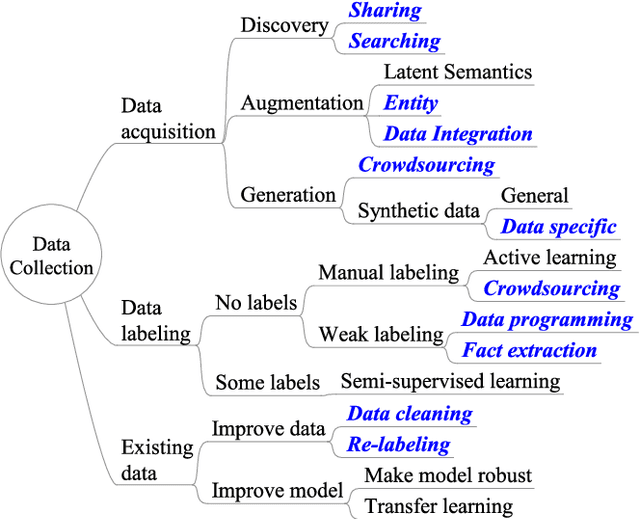
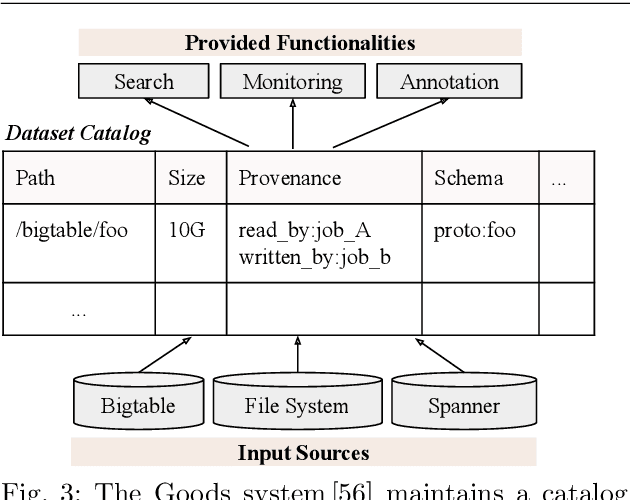
Software 2.0 is a fundamental shift in software engineering where machine learning becomes the new software, powered by big data and computing infrastructure. As a result, software engineering needs to be re-thought where data becomes a first-class citizen on par with code. One striking observation is that 80-90% of the machine learning process is spent on data preparation. Without good data, even the best machine learning algorithms cannot perform well. As a result, data-centric AI practices are now becoming mainstream. Unfortunately, many datasets in the real world are small, dirty, biased, and even poisoned. In this survey, we study the research landscape for data collection and data quality primarily for deep learning applications. Data collection is important because there is lesser need for feature engineering for recent deep learning approaches, but instead more need for large amounts of data. For data quality, we study data validation and data cleaning techniques. Even if the data cannot be fully cleaned, we can still cope with imperfect data during model training where using robust model training techniques. In addition, while bias and fairness have been less studied in traditional data management research, these issues become essential topics in modern machine learning applications. We thus study fairness measures and unfairness mitigation techniques that can be applied before, during, or after model training. We believe that the data management community is well poised to solve problems in these directions.
Sample Selection for Fair and Robust Training
Oct 27, 2021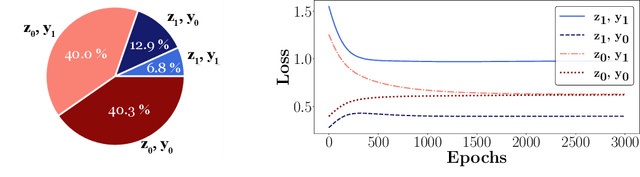
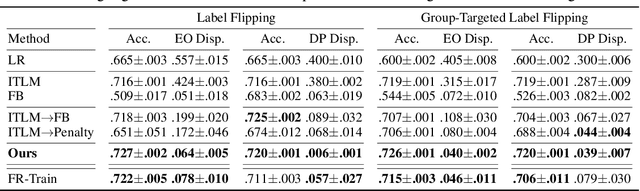
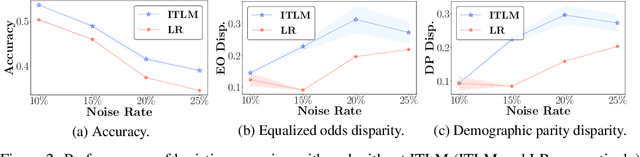
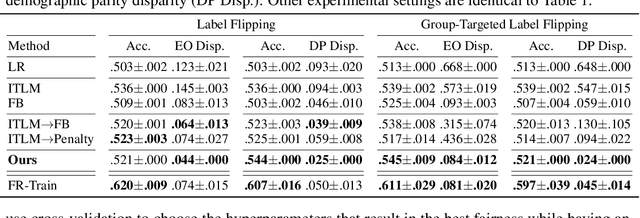
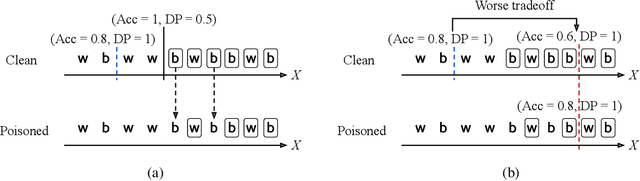
Fairness and robustness are critical elements of Trustworthy AI that need to be addressed together. Fairness is about learning an unbiased model while robustness is about learning from corrupted data, and it is known that addressing only one of them may have an adverse affect on the other. In this work, we propose a sample selection-based algorithm for fair and robust training. To this end, we formulate a combinatorial optimization problem for the unbiased selection of samples in the presence of data corruption. Observing that solving this optimization problem is strongly NP-hard, we propose a greedy algorithm that is efficient and effective in practice. Experiments show that our algorithm obtains fairness and robustness that are better than or comparable to the state-of-the-art technique, both on synthetic and benchmark real datasets. Moreover, unlike other fair and robust training baselines, our algorithm can be used by only modifying the sampling step in batch selection without changing the training algorithm or leveraging additional clean data.
Responsible AI Challenges in End-to-end Machine Learning
Jan 15, 2021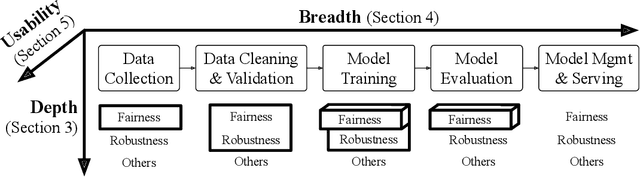
Responsible AI is becoming critical as AI is widely used in our everyday lives. Many companies that deploy AI publicly state that when training a model, we not only need to improve its accuracy, but also need to guarantee that the model does not discriminate against users (fairness), is resilient to noisy or poisoned data (robustness), is explainable, and more. In addition, these objectives are not only relevant to model training, but to all steps of end-to-end machine learning, which include data collection, data cleaning and validation, model training, model evaluation, and model management and serving. Finally, responsible AI is conceptually challenging, and supporting all the objectives must be as easy as possible. We thus propose three key research directions towards this vision - depth, breadth, and usability - to measure progress and introduce our ongoing research. First, responsible AI must be deeply supported where multiple objectives like fairness and robust must be handled together. To this end, we propose FR-Train, a holistic framework for fair and robust model training in the presence of data bias and poisoning. Second, responsible AI must be broadly supported, preferably in all steps of machine learning. Currently we focus on the data pre-processing steps and propose Slice Tuner, a selective data acquisition framework for training fair and accurate models, and MLClean, a data cleaning framework that also improves fairness and robustness. Finally, responsible AI must be usable where the techniques must be easy to deploy and actionable. We propose FairBatch, a batch selection approach for fairness that is effective and simple to use, and Slice Finder, a model evaluation tool that automatically finds problematic slices. We believe we scratched the surface of responsible AI for end-to-end machine learning and suggest research challenges moving forward.
FairBatch: Batch Selection for Model Fairness
Dec 03, 2020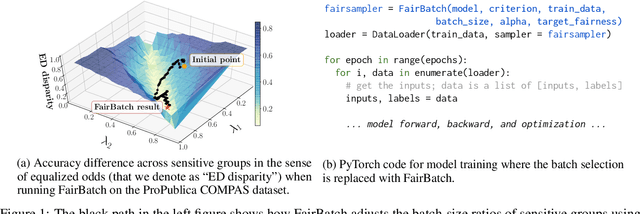
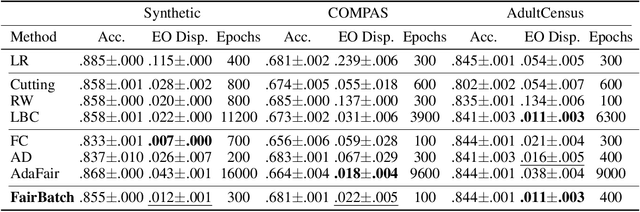
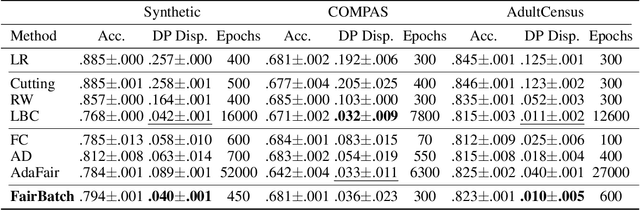
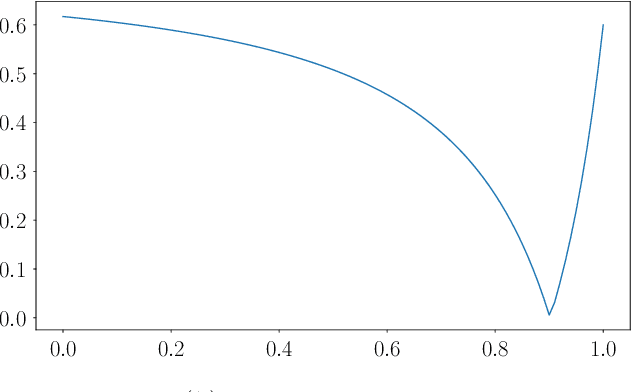
Training a fair machine learning model is essential to prevent demographic disparity. Existing techniques for improving model fairness require broad changes in either data preprocessing or model training, rendering themselves difficult-to-adopt for potentially already complex machine learning systems. We address this problem via the lens of bilevel optimization. While keeping the standard training algorithm as an inner optimizer, we incorporate an outer optimizer so as to equip the inner problem with an additional functionality: Adaptively selecting minibatch sizes for the purpose of improving model fairness. Our batch selection algorithm, which we call FairBatch, implements this optimization and supports prominent fairness measures: equal opportunity, equalized odds, and demographic parity. FairBatch comes with a significant implementation benefit -- it does not require any modification to data preprocessing or model training. For instance, a single-line change of PyTorch code for replacing batch selection part of model training suffices to employ FairBatch. Our experiments conducted both on synthetic and benchmark real data demonstrate that FairBatch can provide such functionalities while achieving comparable (or even greater) performances against the state of the arts. Furthermore, FairBatch can readily improve fairness of any pre-trained model simply via fine-tuning. It is also compatible with existing batch selection techniques intended for different purposes, such as faster convergence, thus gracefully achieving multiple purposes.
Inspector Gadget: A Data Programming-based Labeling System for Industrial Images
Apr 07, 2020
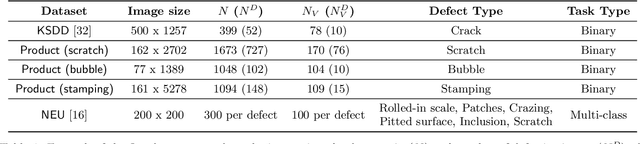
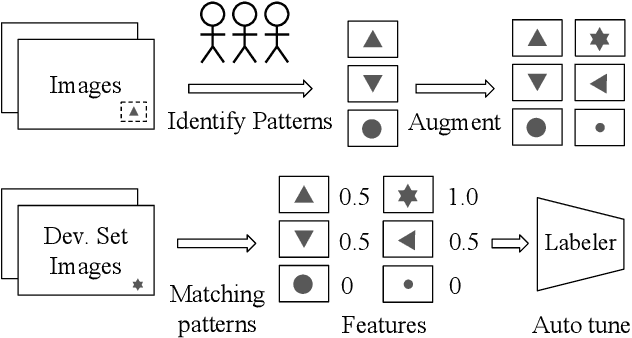
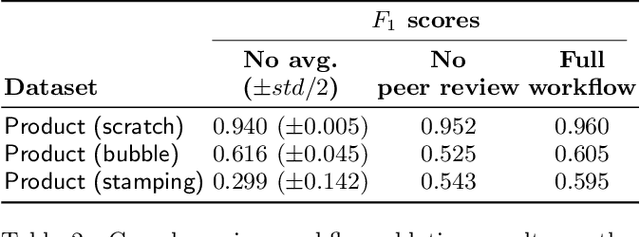
As machine learning for images becomes democratized in the Software 2.0 era, one of the serious bottlenecks is securing enough labeled data for training. This problem is especially critical in a manufacturing setting where smart factories rely on machine learning for product quality control by analyzing industrial images. Such images are typically large and may only need to be partially analyzed where only a small portion is problematic (e.g., identifying defects on a surface). Since manual labeling these images is expensive, weak supervision is an attractive alternative where the idea is to generate weak labels that are not perfect, but can be produced at scale. Data programming is a recent paradigm in this category where it uses human knowledge in the form of labeling functions and combines them into a generative model. Data programming has been successful in applications based on text or structured data and can also be applied to images usually if one can find a way to convert them into structured data. In this work, we expand the horizon of data programming by directly applying it to images without this conversion, which is a common scenario for industrial applications. We propose Inspector Gadget, an image labeling system that combines crowdsourcing, data augmentation, and data programming to produce weak labels at scale for image classification. We perform experiments on real industrial image datasets and show that Inspector Gadget obtains better accuracy than state-of-the-art techniques: Snuba, GOGGLES, and self-learning baselines using convolutional neural networks (CNNs) without pre-training.
FR-Train: A mutual information-based approach to fair and robust training
Feb 24, 2020
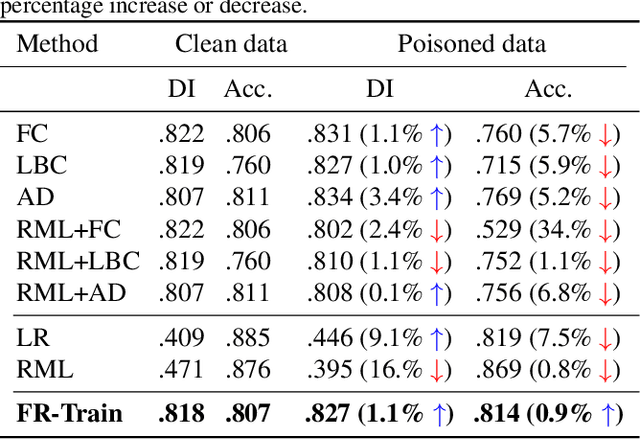
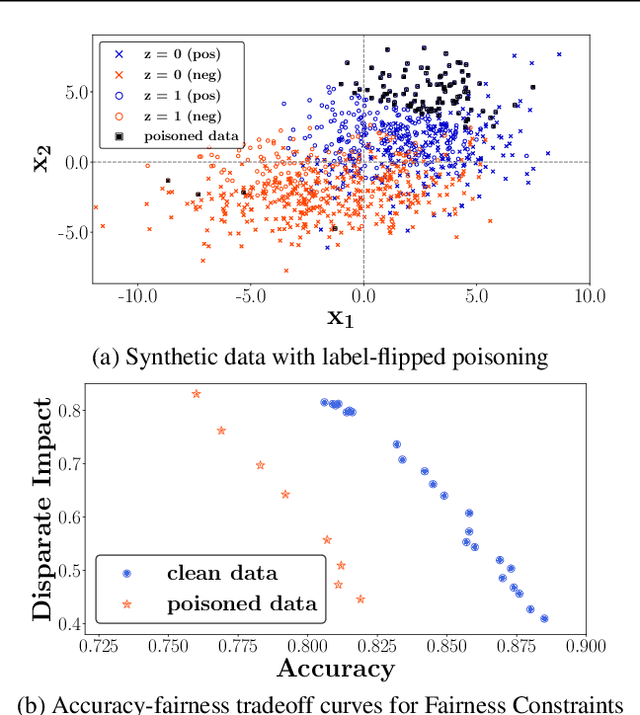
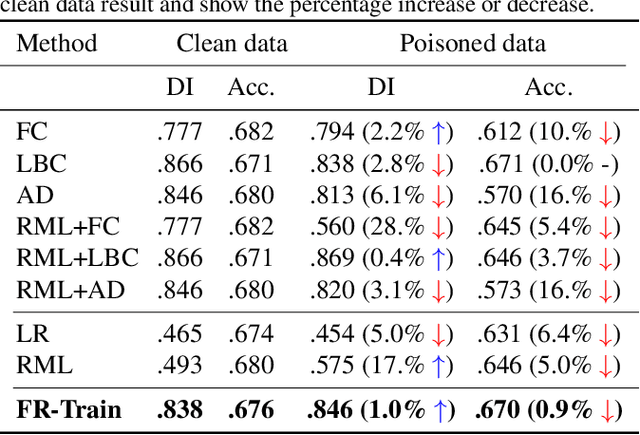
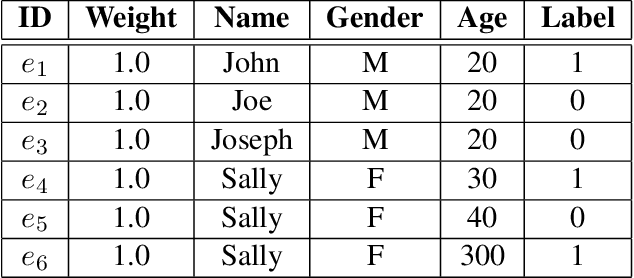
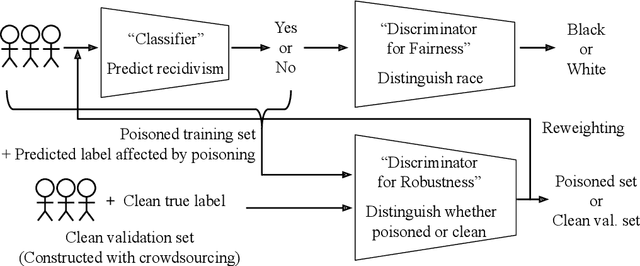
Trustworthy AI is a critical issue in machine learning where, in addition to training a model that is accurate, one must consider both fair and robust training in the presence of data bias and poisoning. However, the existing model fairness techniques mistakenly view poisoned data as an additional bias, resulting in severe performance degradation. To fix this problem, we propose FR-Train, which holistically performs fair and robust model training. We provide a mutual information-based interpretation of an existing adversarial training-based fairness-only method, and apply this idea to architect an additional discriminator that can identify poisoned data using a clean validation set and reduce its influence. In our experiments, FR-Train shows almost no decrease in fairness and accuracy in the presence of data poisoning by both mitigating the bias and defending against poisoning. We also demonstrate how to construct clean validation sets using crowdsourcing, and release new benchmark datasets.
Data Cleaning for Accurate, Fair, and Robust Models: A Big Data - AI Integration Approach
Apr 22, 2019
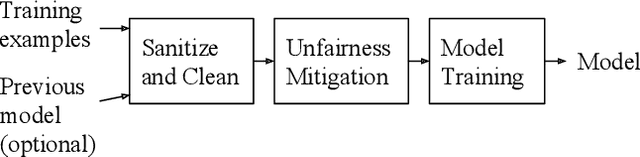
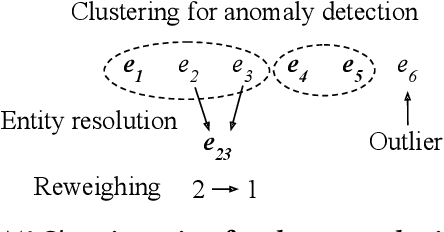
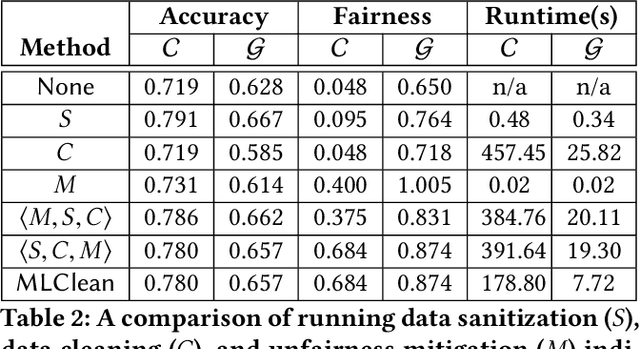
The wide use of machine learning is fundamentally changing the software development paradigm (a.k.a. Software 2.0) where data becomes a first-class citizen, on par with code. As machine learning is used in sensitive applications, it becomes imperative that the trained model is accurate, fair, and robust to attacks. While many techniques have been proposed to improve the model training process (in-processing approach) or the trained model itself (post-processing), we argue that the most effective method is to clean the root cause of error: the data the model is trained on (pre-processing). Historically, there are at least three research communities that have been separately studying this problem: data management, machine learning (model fairness), and security. Although a significant amount of research has been done by each community, ultimately the same datasets must be preprocessed, and there is little understanding how the techniques relate to each other and can possibly be integrated. We contend that it is time to extend the notion of data cleaning for modern machine learning needs. We identify dependencies among the data preprocessing techniques and propose MLClean, a unified data cleaning framework that integrates the techniques and helps train accurate and fair models. This work is part of a broader trend of Big data -- Artificial Intelligence (AI) integration.