 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEVI: Generalizable Fine-tuning via Layer-wise Ensemble of Different Views
Feb 07, 2024



Fine-tuning is becoming widely used for leveraging the power of pre-trained foundation models in new downstream tasks. While there are many successes of fine-tuning on various tasks, recent studies have observed challenges in the generalization of fine-tuned models to unseen distributions (i.e., out-of-distribution; OOD). To improve OOD generalization, some previous studies identify the limitations of fine-tuning data and regulate fine-tuning to preserve the general representation learned from pre-training data. However, potential limitations in the pre-training data and models are often ignored. In this paper, we contend that overly relying on the pre-trained representation may hinder fine-tuning from learning essential representations for downstream tasks and thus hurt its OOD generalization. It can be especially catastrophic when new tasks are from different (sub)domains compared to pre-training data. To address the issues in both pre-training and fine-tuning data, we propose a novel generalizable fine-tuning method LEVI, where the pre-trained model is adaptively ensembled layer-wise with a small task-specific model, while preserving training and inference efficiencies. By combining two complementing models, LEVI effectively suppresses problematic features in both the fine-tuning data and pre-trained model and preserves useful features for new tasks. Broad experiments with large language and vision models show that LEVI greatly improves fine-tuning generalization via emphasizing different views from fine-tuning data and pre-trained features.
Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems
Nov 10, 2023



Learning feature interaction is the critical backbone to building recommender systems. In web-scale applications, learning feature interaction is extremely challenging due to the sparse and large input feature space; meanwhile, manually crafting effective feature interactions is infeasible because of the exponential solution space. We propose to leverage a Transformer-based architecture with attention layers to automatically capture feature interactions. Transformer architectures have witnessed great success in many domains, such as natural language processing and computer vision. However, there has not been much adoption of Transformer architecture for feature interaction modeling in industry. We aim at closing the gap. We identify two key challenges for applying the vanilla Transformer architecture to web-scale recommender systems: (1) Transformer architecture fails to capture the heterogeneous feature interactions in the self-attention layer; (2) The serving latency of Transformer architecture might be too high to be deployed in web-scale recommender systems. We first propose a heterogeneous self-attention layer, which is a simple yet effective modification to the self-attention layer in Transformer, to take into account the heterogeneity of feature interactions. We then introduce \textsc{Hiformer} (\textbf{H}eterogeneous \textbf{I}nteraction Trans\textbf{former}) to further improve the model expressiveness. With low-rank approximation and model pruning, \hiformer enjoys fast inference for online deployment. Extensive offline experiment results corroborates the effectiveness and efficiency of the \textsc{Hiformer} model. We have successfully deployed the \textsc{Hiformer} model to a real world large scale App ranking model at Google Play, with significant improvement in key engagement metrics (up to +2.66\%).
Talking Models: Distill Pre-trained Knowledge to Downstream Models via Interactive Communication
Oct 04, 2023



Many recent breakthroughs in machine learning have been enabled by the pre-trained foundation models. By scaling up model parameters, training data, and computation resources, foundation models have significantly advanced the state-of-the-art in many applications. However, it is still an open question of how to use these models to perform downstream tasks efficiently. Knowledge distillation (KD) has been explored to tackle this challenge. KD transfers knowledge from a large teacher model to a smaller student model. While KD has been successful in improving student model performance, recent research has discovered that a powerful teacher does not necessarily lead to a powerful student, due to their huge capacity gap. In addition, the potential distribution shifts between the pre-training data and downstream tasks can make knowledge transfer in KD sub-optimal for improving downstream task performance. In this paper, we extend KD with an interactive communication process to help students of downstream tasks learn effectively from pre-trained foundation models. Our design is inspired by the way humans learn from teachers who can explain knowledge in a way that meets the students' needs. Specifically, we let each model (i.e., student and teacher) train two components: (1) an encoder encoding the model's hidden states to a message and (2) a decoder decoding any messages to its own hidden states. With encoder and decoder, not only can the teacher transfer rich information by encoding its hidden states, but also the student can send messages with information of downstream tasks to the teacher. Therefore, knowledge passing from teacher to student can be tailored to the student's capacity and downstream tasks' distributions. We conducted experiments on benchmark datasets to show that our communication mechanism outperforms state-of-the-art distillation techniques.
Expert Finding in Heterogeneous Bibliographic Networks with Locally-trained Embeddings
Mar 09, 2018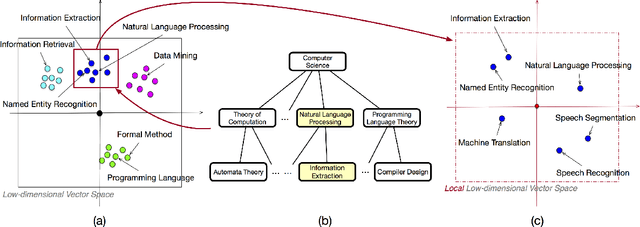

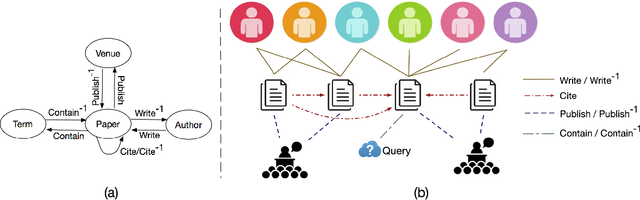

Expert finding is an important task in both industry and academia. It is challenging to rank candidates with appropriate expertise for various queries. In addition, different types of objects interact with one another, which naturally forms heterogeneous information networks. We study the task of expert finding in heterogeneous bibliographical networks based on two aspects: textual content analysis and authority ranking. Regarding the textual content analysis, we propose a new method for query expansion via locally-trained embedding learning with concept hierarchy as guidance, which is particularly tailored for specific queries with narrow semantic meanings. Compared with global embedding learning, locally-trained embedding learning projects the terms into a latent semantic space constrained on relevant topics, therefore it preserves more precise and subtle information for specific queries. Considering the candidate ranking, the heterogeneous information network structure, while being largely ignored in the previous studies of expert finding, provides additional information. Specifically, different types of interactions among objects play different roles. We propose a ranking algorithm to estimate the authority of objects in the network, treating each strongly-typed edge type individually. To demonstrate the effectiveness of the proposed framework, we apply the proposed method to a large-scale bibliographical dataset with over two million entries and one million researcher candidates. The experiment results show that the proposed framework outperforms existing methods for both general and specific queries.
AspEm: Embedding Learning by Aspects in Heterogeneous Information Networks
Mar 05, 2018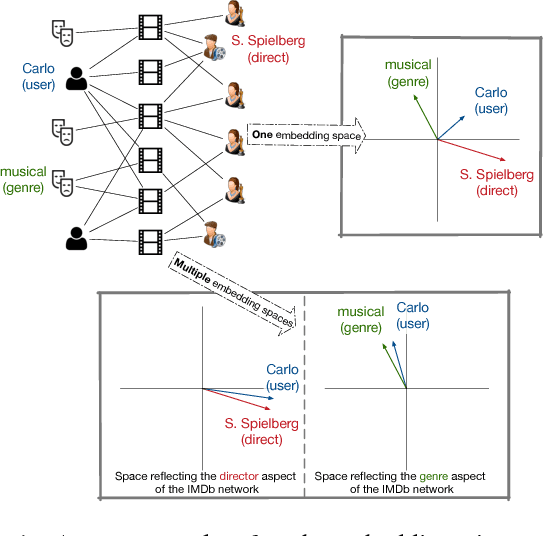
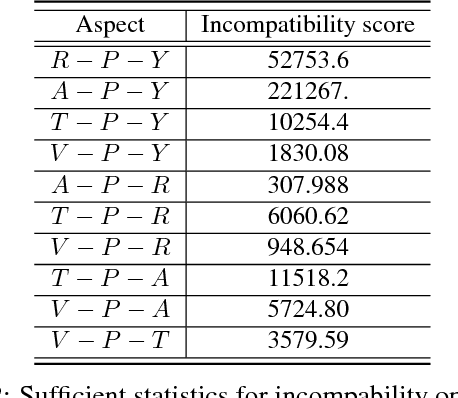
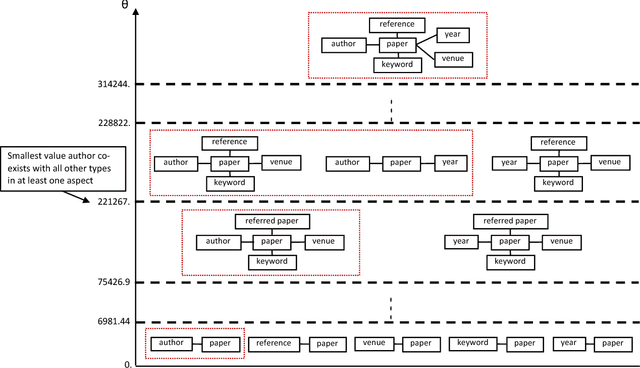
Heterogeneous information networks (HINs) are ubiquitous in real-world applications. Due to the heterogeneity in HINs, the typed edges may not fully align with each other. In order to capture the semantic subtlety, we propose the concept of aspects with each aspect being a unit representing one underlying semantic facet. Meanwhile, network embedding has emerged as a powerful method for learning network representation, where the learned embedding can be used as features in various downstream applications. Therefore, we are motivated to propose a novel embedding learning framework---AspEm---to preserve the semantic information in HINs based on multiple aspects. Instead of preserving information of the network in one semantic space, AspEm encapsulates information regarding each aspect individually. In order to select aspects for embedding purpose, we further devise a solution for AspEm based on dataset-wide statistics. To corroborate the efficacy of AspEm, we conducted experiments on two real-words datasets with two types of applications---classification and link prediction. Experiment results demonstrate that AspEm can outperform baseline network embedding learning methods by considering multiple aspects, where the aspects can be selected from the given HIN in an unsupervised manner.
Empower Sequence Labeling with Task-Aware Neural Language Model
Nov 23, 2017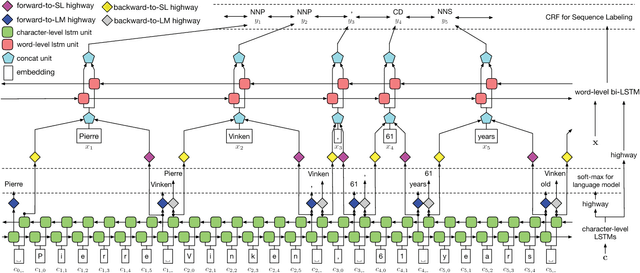

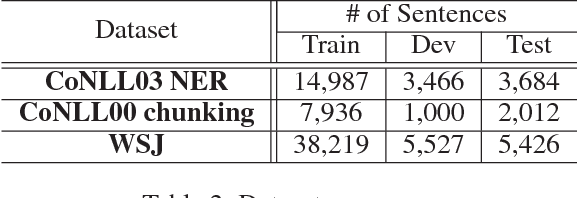
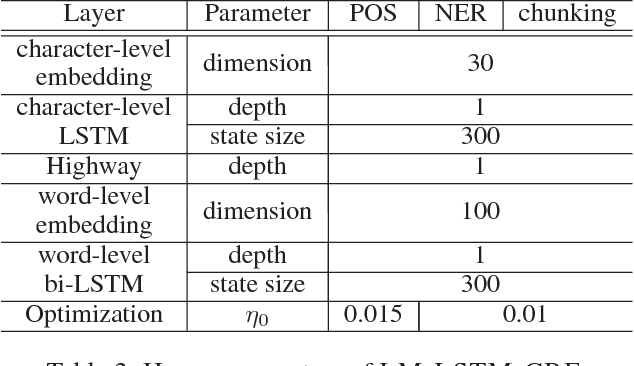
Linguistic sequence labeling is a general modeling approach that encompasses a variety of problems, such as part-of-speech tagging and named entity recognition. Recent advances in neural networks (NNs) make it possible to build reliable models without handcrafted features. However, in many cases, it is hard to obtain sufficient annotations to train these models. In this study, we develop a novel neural framework to extract abundant knowledge hidden in raw texts to empower the sequence labeling task. Besides word-level knowledge contained in pre-trained word embeddings, character-aware neural language models are incorporated to extract character-level knowledge. Transfer learning techniques are further adopted to mediate different components and guide the language model towards the key knowledge. Comparing to previous methods, these task-specific knowledge allows us to adopt a more concise model and conduct more efficient training. Different from most transfer learning methods, the proposed framework does not rely on any additional supervision. It extracts knowledge from self-contained order information of training sequences. Extensive experiments on benchmark datasets demonstrate the effectiveness of leveraging character-level knowledge and the efficiency of co-training. For example, on the CoNLL03 NER task, model training completes in about 6 hours on a single GPU, reaching F1 score of 91.71$\pm$0.10 without using any extra annotation.
Heterogeneous Supervision for Relation Extraction: A Representation Learning Approach
Aug 01, 2017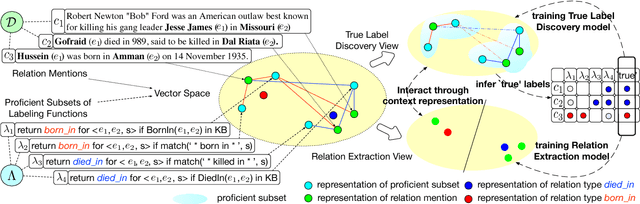

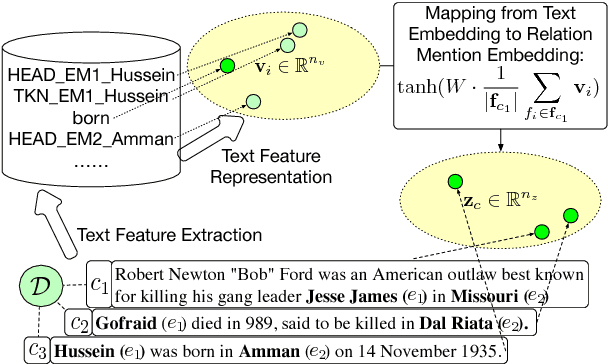

Relation extraction is a fundamental task in information extraction. Most existing methods have heavy reliance on annotations labeled by human experts, which are costly and time-consuming. To overcome this drawback, we propose a novel framework, REHession, to conduct relation extractor learning using annotations from heterogeneous information source, e.g., knowledge base and domain heuristics. These annotations, referred as heterogeneous supervision, often conflict with each other, which brings a new challenge to the original relation extraction task: how to infer the true label from noisy labels for a given instance. Identifying context information as the backbone of both relation extraction and true label discovery, we adopt embedding techniques to learn the distributed representations of context, which bridges all components with mutual enhancement in an iterative fashion. Extensive experimental results demonstrate the superiority of REHession over the state-of-the-art.
PReP: Path-Based Relevance from a Probabilistic Perspective in Heterogeneous Information Networks
Jun 05, 2017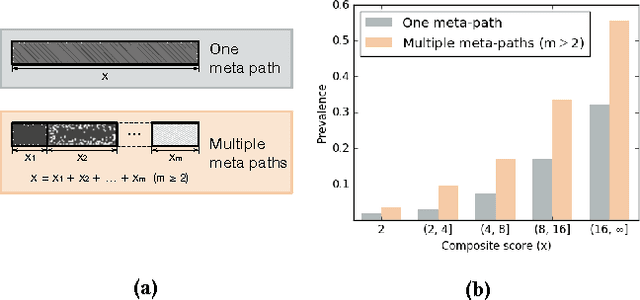
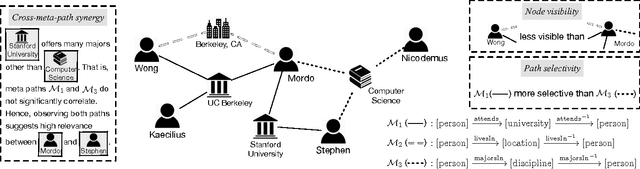

As a powerful representation paradigm for networked and multi-typed data, the heterogeneous information network (HIN) is ubiquitous. Meanwhile, defining proper relevance measures has always been a fundamental problem and of great pragmatic importance for network mining tasks. Inspired by our probabilistic interpretation of existing path-based relevance measures, we propose to study HIN relevance from a probabilistic perspective. We also identify, from real-world data, and propose to model cross-meta-path synergy, which is a characteristic important for defining path-based HIN relevance and has not been modeled by existing methods. A generative model is established to derive a novel path-based relevance measure, which is data-driven and tailored for each HIN. We develop an inference algorithm to find the maximum a posteriori (MAP) estimate of the model parameters, which entails non-trivial tricks. Experiments on two real-world datasets demonstrate the effectiveness of the proposed model and relevance measure.
Towards Faster Rates and Oracle Property for Low-Rank Matrix Estimation
Jul 06, 2015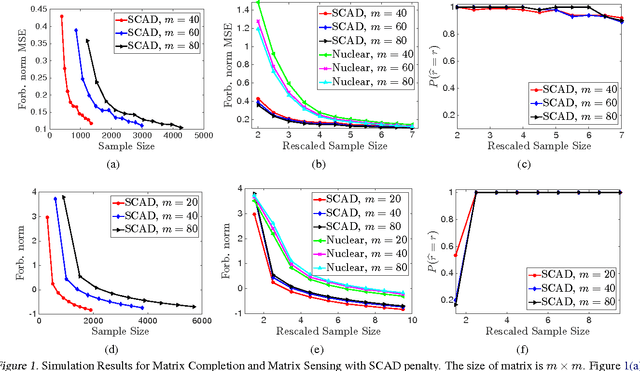
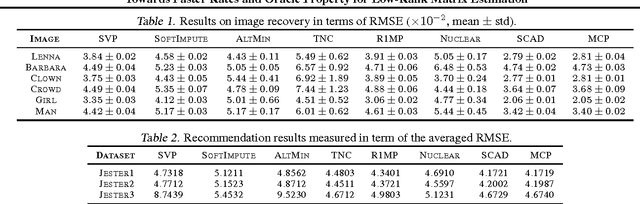
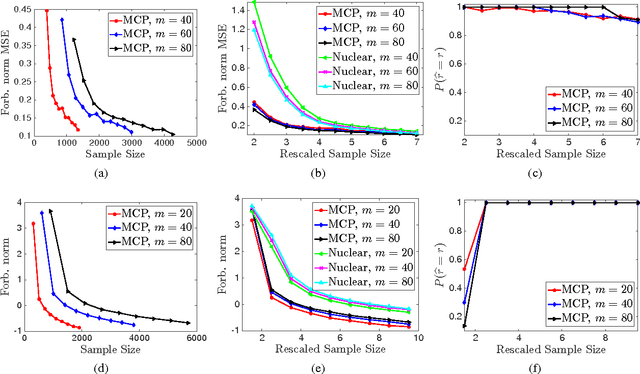
We present a unified framework for low-rank matrix estimation with nonconvex penalties. We first prove that the proposed estimator attains a faster statistical rate than the traditional low-rank matrix estimator with nuclear norm penalty. Moreover, we rigorously show that under a certain condition on the magnitude of the nonzero singular values, the proposed estimator enjoys oracle property (i.e., exactly recovers the true rank of the matrix), besides attaining a faster rate. As far as we know, this is the first work that establishes the theory of low-rank matrix estimation with nonconvex penalties, confirming the advantages of nonconvex penalties for matrix completion. Numerical experiments on both synthetic and real world datasets corroborate our theory.