 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpower Sequence Labeling with Task-Aware Neural Language Model
Paper and Code
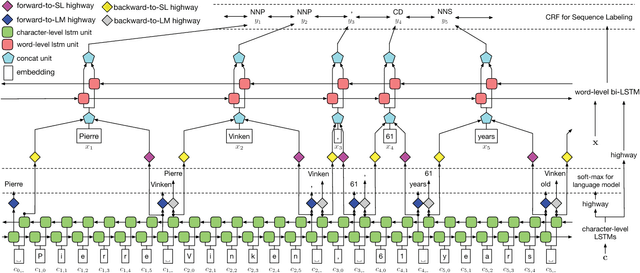

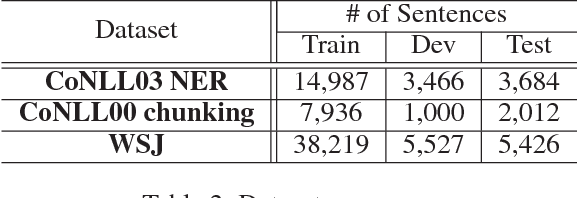
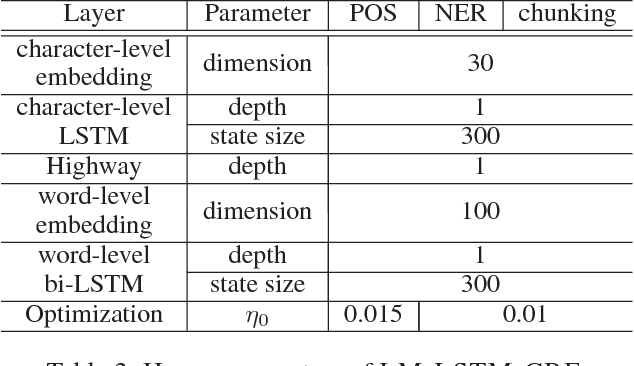
Linguistic sequence labeling is a general modeling approach that encompasses a variety of problems, such as part-of-speech tagging and named entity recognition. Recent advances in neural networks (NNs) make it possible to build reliable models without handcrafted features. However, in many cases, it is hard to obtain sufficient annotations to train these models. In this study, we develop a novel neural framework to extract abundant knowledge hidden in raw texts to empower the sequence labeling task. Besides word-level knowledge contained in pre-trained word embeddings, character-aware neural language models are incorporated to extract character-level knowledge. Transfer learning techniques are further adopted to mediate different components and guide the language model towards the key knowledge. Comparing to previous methods, these task-specific knowledge allows us to adopt a more concise model and conduct more efficient training. Different from most transfer learning methods, the proposed framework does not rely on any additional supervision. It extracts knowledge from self-contained order information of training sequences. Extensive experiments on benchmark datasets demonstrate the effectiveness of leveraging character-level knowledge and the efficiency of co-training. For example, on the CoNLL03 NER task, model training completes in about 6 hours on a single GPU, reaching F1 score of 91.71$\pm$0.10 without using any extra annotation.