 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially-Typed NER Datasets Integration: Connecting Practice to Theory
May 01, 2020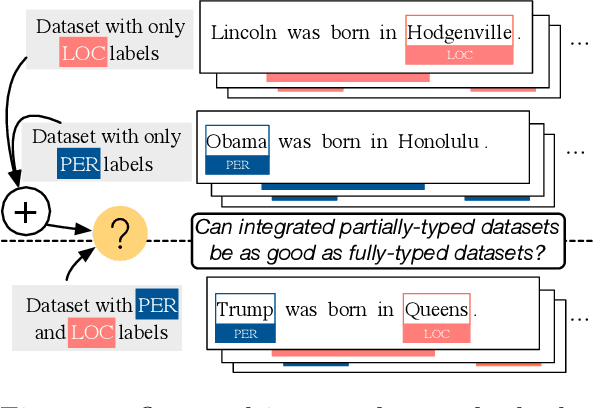
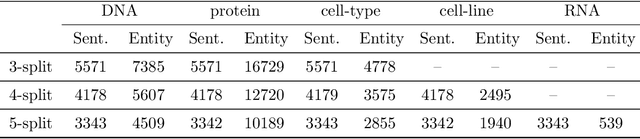


While typical named entity recognition (NER) models require the training set to be annotated with all target types, each available datasets may only cover a part of them. Instead of relying on fully-typed NER datasets, many efforts have been made to leverage multiple partially-typed ones for training and allow the resulting model to cover a full type set. However, there is neither guarantee on the quality of integrated datasets, nor guidance on the design of training algorithms. Here, we conduct a systematic analysis and comparison between partially-typed NER datasets and fully-typed ones, in both theoretical and empirical manner. Firstly, we derive a bound to establish that models trained with partially-typed annotations can reach a similar performance with the ones trained with fully-typed annotations, which also provides guidance on the algorithm design. Moreover, we conduct controlled experiments, which shows partially-typed datasets leads to similar performance with the model trained with the same amount of fully-typed annotations
pg-Causality: Identifying Spatiotemporal Causal Pathways for Air Pollutants with Urban Big Data
Apr 18, 2018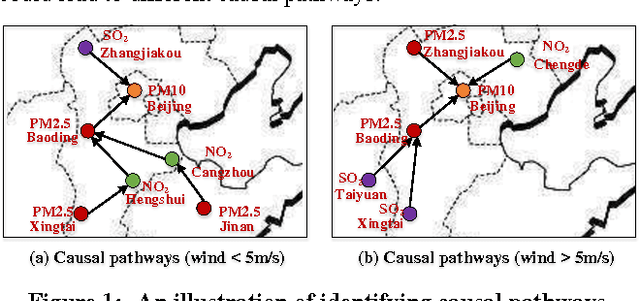

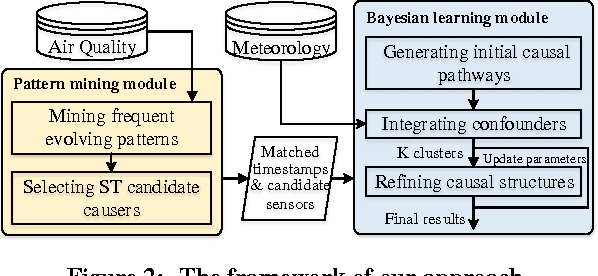
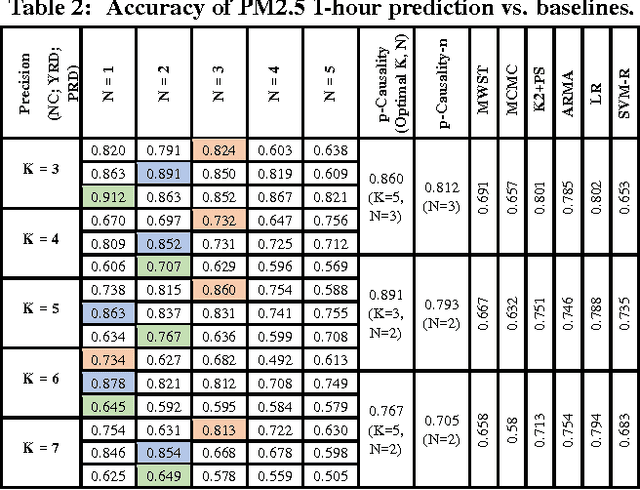
Many countries are suffering from severe air pollution. Understanding how different air pollutants accumulate and propagate is critical to making relevant public policies. In this paper, we use urban big data (air quality data and meteorological data) to identify the \emph{spatiotemporal (ST) causal pathways} for air pollutants. This problem is challenging because: (1) there are numerous noisy and low-pollution periods in the raw air quality data, which may lead to unreliable causality analysis, (2) for large-scale data in the ST space, the computational complexity of constructing a causal structure is very high, and (3) the \emph{ST causal pathways} are complex due to the interactions of multiple pollutants and the influence of environmental factors. Therefore, we present \emph{p-Causality}, a novel pattern-aided causality analysis approach that combines the strengths of \emph{pattern mining} and \emph{Bayesian learning} to efficiently and faithfully identify the \emph{ST causal pathways}. First, \emph{Pattern mining} helps suppress the noise by capturing frequent evolving patterns (FEPs) of each monitoring sensor, and greatly reduce the complexity by selecting the pattern-matched sensors as "causers". Then, \emph{Bayesian learning} carefully encodes the local and ST causal relations with a Gaussian Bayesian network (GBN)-based graphical model, which also integrates environmental influences to minimize biases in the final results. We evaluate our approach with three real-world data sets containing 982 air quality sensors, in three regions of China from 01-Jun-2013 to 19-Dec-2015. Results show that our approach outperforms the traditional causal structure learning methods in time efficiency, inference accuracy and interpretability.
Heterogeneous Supervision for Relation Extraction: A Representation Learning Approach
Aug 01, 2017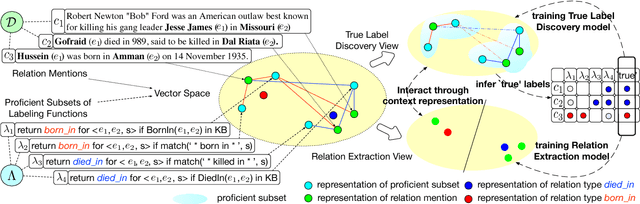

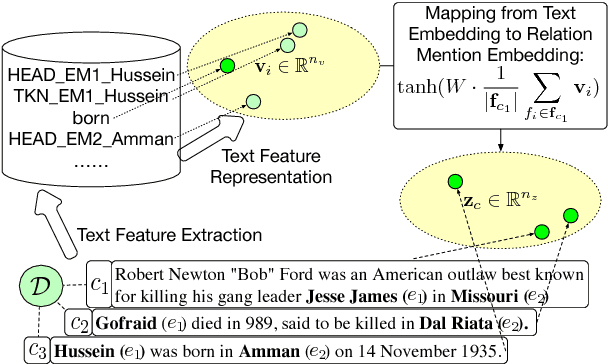

Relation extraction is a fundamental task in information extraction. Most existing methods have heavy reliance on annotations labeled by human experts, which are costly and time-consuming. To overcome this drawback, we propose a novel framework, REHession, to conduct relation extractor learning using annotations from heterogeneous information source, e.g., knowledge base and domain heuristics. These annotations, referred as heterogeneous supervision, often conflict with each other, which brings a new challenge to the original relation extraction task: how to infer the true label from noisy labels for a given instance. Identifying context information as the backbone of both relation extraction and true label discovery, we adopt embedding techniques to learn the distributed representations of context, which bridges all components with mutual enhancement in an iterative fashion. Extensive experimental results demonstrate the superiority of REHession over the state-of-the-art.