 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
Aug 28, 2025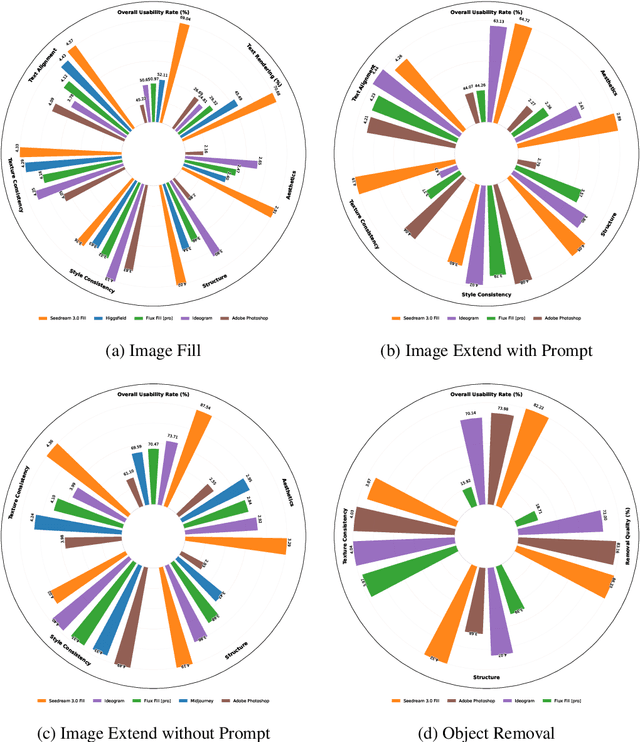

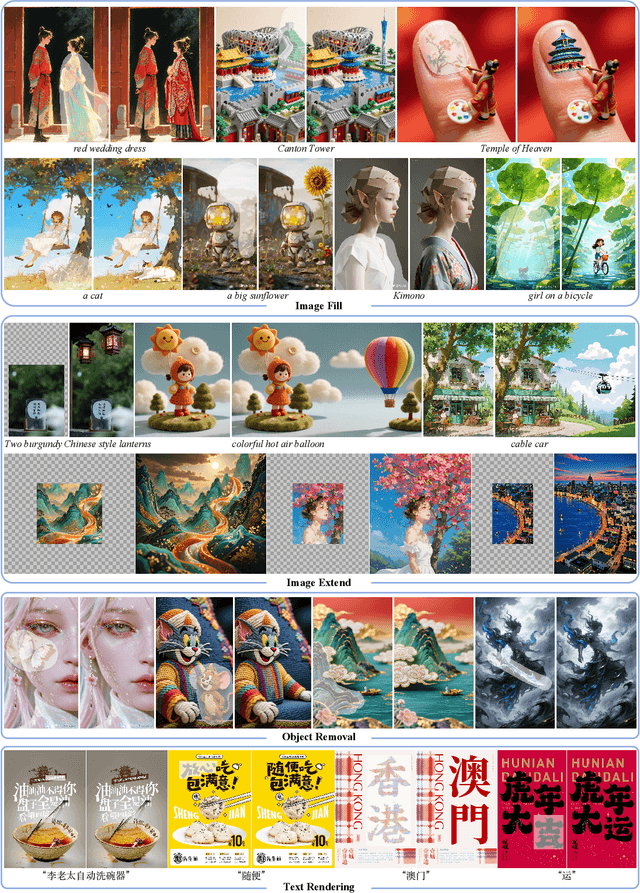
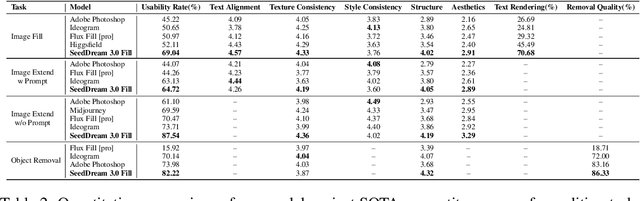
In this paper, we introduce OneReward, a unified reinforcement learning framework that enhances the model's generative capabilities across multiple tasks under different evaluation criteria using only \textit{One Reward} model. By employing a single vision-language model (VLM) as the generative reward model, which can distinguish the winner and loser for a given task and a given evaluation criterion, it can be effectively applied to multi-task generation models, particularly in contexts with varied data and diverse task objectives. We utilize OneReward for mask-guided image generation, which can be further divided into several sub-tasks such as image fill, image extend, object removal, and text rendering, involving a binary mask as the edit area. Although these domain-specific tasks share same conditioning paradigm, they differ significantly in underlying data distributions and evaluation metrics. Existing methods often rely on task-specific supervised fine-tuning (SFT), which limits generalization and training efficiency. Building on OneReward, we develop Seedream 3.0 Fill, a mask-guided generation model trained via multi-task reinforcement learning directly on a pre-trained base model, eliminating the need for task-specific SFT. Experimental results demonstrate that our unified edit model consistently outperforms both commercial and open-source competitors, such as Ideogram, Adobe Photoshop, and FLUX Fill [Pro], across multiple evaluation dimensions. Code and model are available at: https://one-reward.github.io
DreamLight: Towards Harmonious and Consistent Image Relighting
Jun 17, 2025We introduce a model named DreamLight for universal image relighting in this work, which can seamlessly composite subjects into a new background while maintaining aesthetic uniformity in terms of lighting and color tone. The background can be specified by natural images (image-based relighting) or generated from unlimited text prompts (text-based relighting). Existing studies primarily focus on image-based relighting, while with scant exploration into text-based scenarios. Some works employ intricate disentanglement pipeline designs relying on environment maps to provide relevant information, which grapples with the expensive data cost required for intrinsic decomposition and light source. Other methods take this task as an image translation problem and perform pixel-level transformation with autoencoder architecture. While these methods have achieved decent harmonization effects, they struggle to generate realistic and natural light interaction effects between the foreground and background. To alleviate these challenges, we reorganize the input data into a unified format and leverage the semantic prior provided by the pretrained diffusion model to facilitate the generation of natural results. Moreover, we propose a Position-Guided Light Adapter (PGLA) that condenses light information from different directions in the background into designed light query embeddings, and modulates the foreground with direction-biased masked attention. In addition, we present a post-processing module named Spectral Foreground Fixer (SFF) to adaptively reorganize different frequency components of subject and relighted background, which helps enhance the consistency of foreground appearance. Extensive comparisons and user study demonstrate that our DreamLight achieves remarkable relighting performance.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
LLMGA: Multimodal Large Language Model based Generation Assistant
Nov 27, 2023
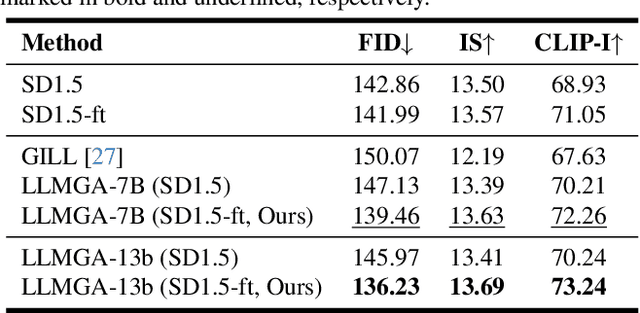
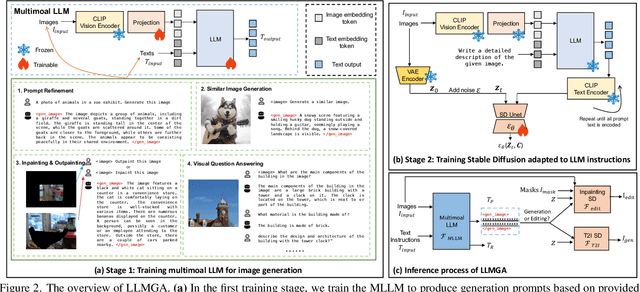

In this paper, we introduce a Multimodal Large Language Model-based Generation Assistant (LLMGA), leveraging the vast reservoir of knowledge and proficiency in reasoning, comprehension, and response inherent in Large Language Models (LLMs) to assist users in image generation and editing. Diverging from existing approaches where Multimodal Large Language Models (MLLMs) generate fixed-size embeddings to control Stable Diffusion (SD), our LLMGA provides a detailed language generation prompt for precise control over SD. This not only augments LLM context understanding but also reduces noise in generation prompts, yields images with more intricate and precise content, and elevates the interpretability of the network. To this end, we curate a comprehensive dataset comprising prompt refinement, similar image generation, inpainting $\&$ outpainting, and visual question answering. Moreover, we propose a two-stage training scheme. In the first stage, we train the MLLM to grasp the properties of image generation and editing, enabling it to generate detailed prompts. In the second stage, we optimize SD to align with the MLLM's generation prompts. Additionally, we propose a reference-based restoration network to alleviate texture, brightness, and contrast disparities between generated and preserved regions during image editing. Extensive results show that LLMGA has promising generative capabilities and can enable wider applications in an interactive manner.
DiffI2I: Efficient Diffusion Model for Image-to-Image Translation
Aug 26, 2023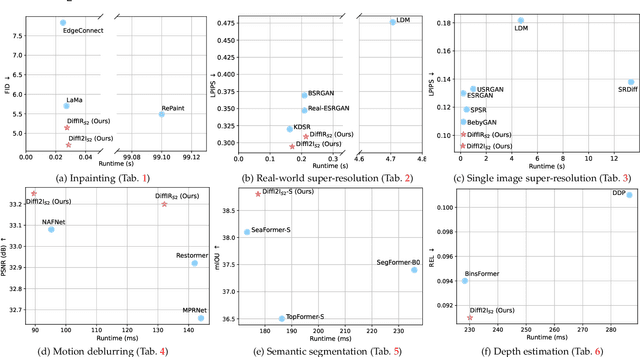
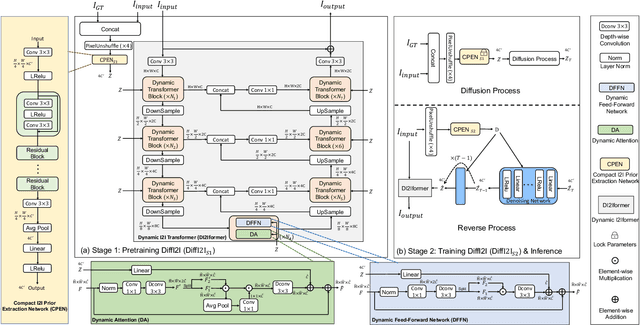

The Diffusion Model (DM) has emerged as the SOTA approach for image synthesis. However, the existing DM cannot perform well on some image-to-image translation (I2I) tasks. Different from image synthesis, some I2I tasks, such as super-resolution, require generating results in accordance with GT images. Traditional DMs for image synthesis require extensive iterations and large denoising models to estimate entire images, which gives their strong generative ability but also leads to artifacts and inefficiency for I2I. To tackle this challenge, we propose a simple, efficient, and powerful DM framework for I2I, called DiffI2I. Specifically, DiffI2I comprises three key components: a compact I2I prior extraction network (CPEN), a dynamic I2I transformer (DI2Iformer), and a denoising network. We train DiffI2I in two stages: pretraining and DM training. For pretraining, GT and input images are fed into CPEN$_{S1}$ to capture a compact I2I prior representation (IPR) guiding DI2Iformer. In the second stage, the DM is trained to only use the input images to estimate the same IRP as CPEN$_{S1}$. Compared to traditional DMs, the compact IPR enables DiffI2I to obtain more accurate outcomes and employ a lighter denoising network and fewer iterations. Through extensive experiments on various I2I tasks, we demonstrate that DiffI2I achieves SOTA performance while significantly reducing computational burdens.
DiffIR: Efficient Diffusion Model for Image Restoration
Mar 16, 2023



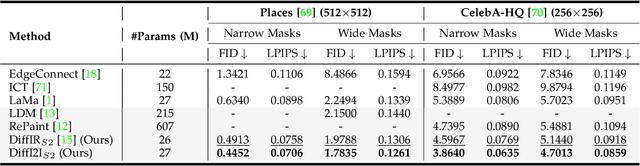
Diffusion model (DM) has achieved SOTA performance by modeling the image synthesis process into a sequential application of a denoising network. However, different from image synthesis generating each pixel from scratch, most pixels of image restoration (IR) are given. Thus, for IR, traditional DMs running massive iterations on a large model to estimate whole images or feature maps is inefficient. To address this issue, we propose an efficient DM for IR (DiffIR), which consists of a compact IR prior extraction network (CPEN), dynamic IR transformer (DIRformer), and denoising network. Specifically, DiffIR has two training stages: pretraining and training DM. In pretraining, we input ground-truth images into CPEN$_{S1}$ to capture a compact IR prior representation (IPR) to guide DIRformer. In the second stage, we train the DM to directly estimate the same IRP as pretrained CPEN$_{S1}$ only using LQ images. We observe that since the IPR is only a compact vector, DiffIR can use fewer iterations than traditional DM to obtain accurate estimations and generate more stable and realistic results. Since the iterations are few, our DiffIR can adopt a joint optimization of CPEN$_{S2}$, DIRformer, and denoising network, which can further reduce the estimation error influence. We conduct extensive experiments on several IR tasks and achieve SOTA performance while consuming less computational costs.
Human De-occlusion: Invisible Perception and Recovery for Humans
Mar 22, 2021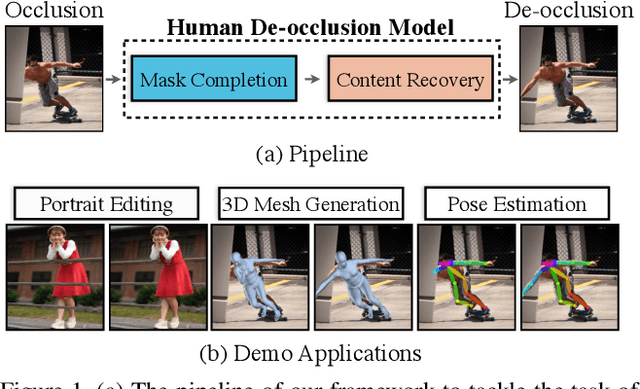
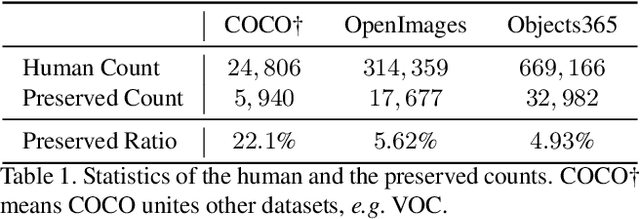
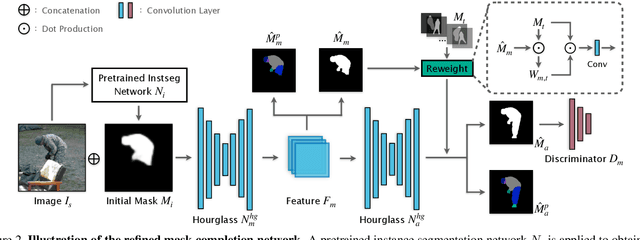
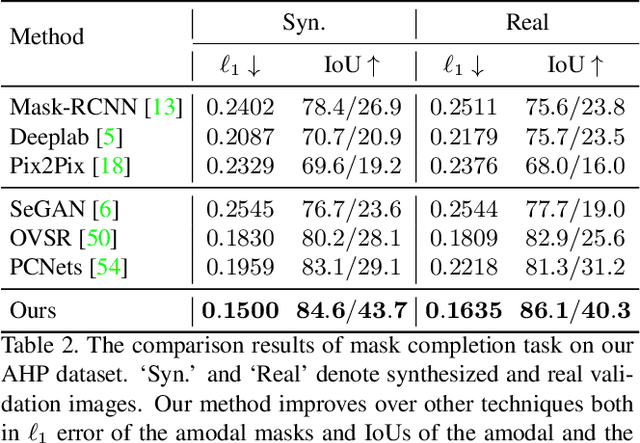
In this paper, we tackle the problem of human de-occlusion which reasons about occluded segmentation masks and invisible appearance content of humans. In particular, a two-stage framework is proposed to estimate the invisible portions and recover the content inside. For the stage of mask completion, a stacked network structure is devised to refine inaccurate masks from a general instance segmentation model and predict integrated masks simultaneously. Additionally, the guidance from human parsing and typical pose masks are leveraged to bring prior information. For the stage of content recovery, a novel parsing guided attention module is applied to isolate body parts and capture context information across multiple scales. Besides, an Amodal Human Perception dataset (AHP) is collected to settle the task of human de-occlusion. AHP has advantages of providing annotations from real-world scenes and the number of humans is comparatively larger than other amodal perception datasets. Based on this dataset, experiments demonstrate that our method performs over the state-of-the-art techniques in both tasks of mask completion and content recovery. Our AHP dataset is available at \url{https://sydney0zq.github.io/ahp/}.
Partially-Typed NER Datasets Integration: Connecting Practice to Theory
May 01, 2020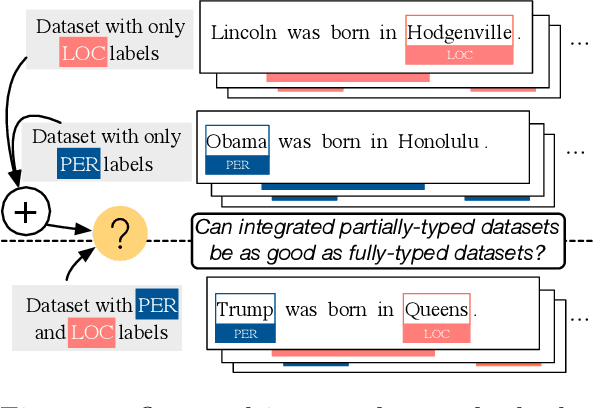
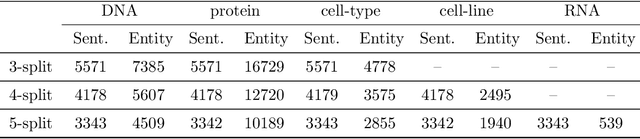


While typical named entity recognition (NER) models require the training set to be annotated with all target types, each available datasets may only cover a part of them. Instead of relying on fully-typed NER datasets, many efforts have been made to leverage multiple partially-typed ones for training and allow the resulting model to cover a full type set. However, there is neither guarantee on the quality of integrated datasets, nor guidance on the design of training algorithms. Here, we conduct a systematic analysis and comparison between partially-typed NER datasets and fully-typed ones, in both theoretical and empirical manner. Firstly, we derive a bound to establish that models trained with partially-typed annotations can reach a similar performance with the ones trained with fully-typed annotations, which also provides guidance on the algorithm design. Moreover, we conduct controlled experiments, which shows partially-typed datasets leads to similar performance with the model trained with the same amount of fully-typed annotations
Fast Top-k Area Topics Extraction with Knowledge Base
Dec 04, 2017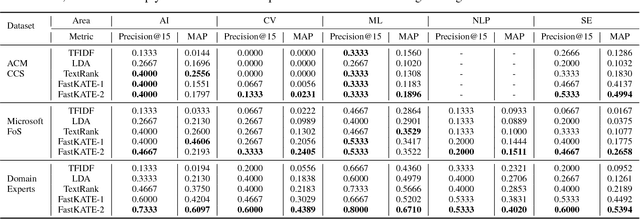
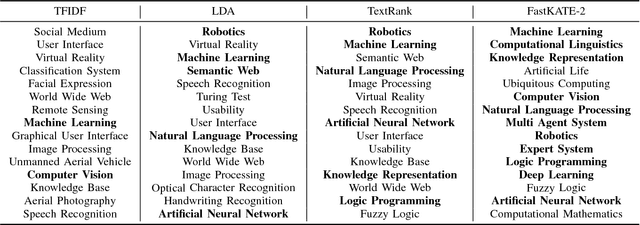
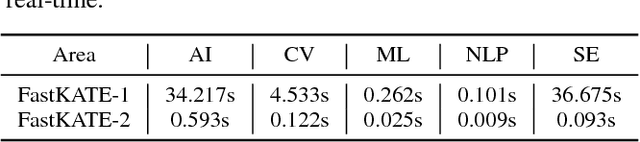
What are the most popular research topics in Artificial Intelligence (AI)? We formulate the problem as extracting top-$k$ topics that can best represent a given area with the help of knowledge base. We theoretically prove that the problem is NP-hard and propose an optimization model, FastKATE, to address this problem by combining both explicit and latent representations for each topic. We leverage a large-scale knowledge base (Wikipedia) to generate topic embeddings using neural networks and use this kind of representations to help capture the representativeness of topics for given areas. We develop a fast heuristic algorithm to efficiently solve the problem with a provable error bound. We evaluate the proposed model on three real-world datasets. Experimental results demonstrate our model's effectiveness, robustness, real-timeness (return results in $<1$s), and its superiority over several alternative methods.