 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffI2I: Efficient Diffusion Model for Image-to-Image Translation
Paper and Code
Aug 26, 2023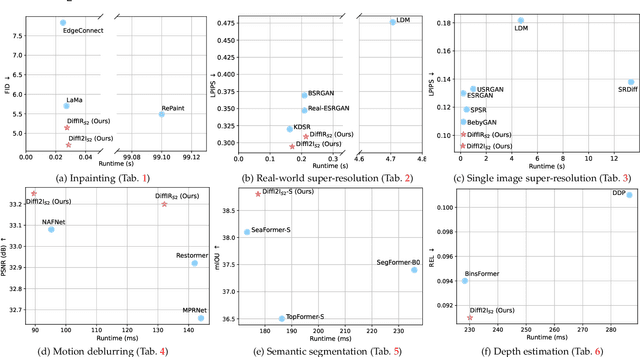
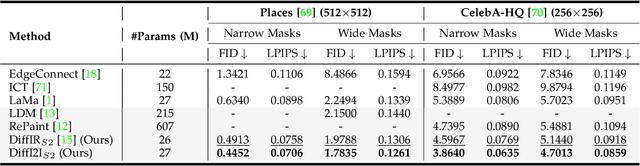
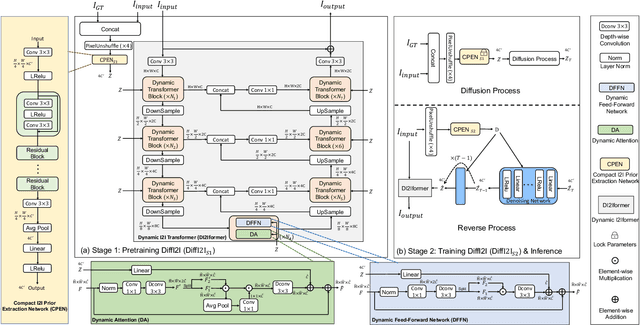

The Diffusion Model (DM) has emerged as the SOTA approach for image synthesis. However, the existing DM cannot perform well on some image-to-image translation (I2I) tasks. Different from image synthesis, some I2I tasks, such as super-resolution, require generating results in accordance with GT images. Traditional DMs for image synthesis require extensive iterations and large denoising models to estimate entire images, which gives their strong generative ability but also leads to artifacts and inefficiency for I2I. To tackle this challenge, we propose a simple, efficient, and powerful DM framework for I2I, called DiffI2I. Specifically, DiffI2I comprises three key components: a compact I2I prior extraction network (CPEN), a dynamic I2I transformer (DI2Iformer), and a denoising network. We train DiffI2I in two stages: pretraining and DM training. For pretraining, GT and input images are fed into CPEN$_{S1}$ to capture a compact I2I prior representation (IPR) guiding DI2Iformer. In the second stage, the DM is trained to only use the input images to estimate the same IRP as CPEN$_{S1}$. Compared to traditional DMs, the compact IPR enables DiffI2I to obtain more accurate outcomes and employ a lighter denoising network and fewer iterations. Through extensive experiments on various I2I tasks, we demonstrate that DiffI2I achieves SOTA performance while significantly reducing computational burdens.