 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
MMSRARec: Summarization and Retrieval Augumented Sequential Recommendation Based on Multimodal Large Language Model
Dec 24, 2025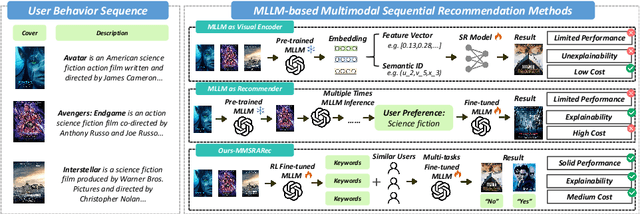



Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated significant potential in recommendation systems. However, the effective application of MLLMs to multimodal sequential recommendation remains unexplored: A) Existing methods primarily leverage the multimodal semantic understanding capabilities of pre-trained MLLMs to generate item embeddings or semantic IDs, thereby enhancing traditional recommendation models. These approaches generate item representations that exhibit limited interpretability, and pose challenges when transferring to language model-based recommendation systems. B) Other approaches convert user behavior sequence into image-text pairs and perform recommendation through multiple MLLM inference, incurring prohibitive computational and time costs. C) Current MLLM-based recommendation systems generally neglect the integration of collaborative signals. To address these limitations while balancing recommendation performance, interpretability, and computational cost, this paper proposes MultiModal Summarization-and-Retrieval-Augmented Sequential Recommendation. Specifically, we first employ MLLM to summarize items into concise keywords and fine-tune the model using rewards that incorporate summary length, information loss, and reconstruction difficulty, thereby enabling adaptive adjustment of the summarization policy. Inspired by retrieval-augmented generation, we then transform collaborative signals into corresponding keywords and integrate them as supplementary context. Finally, we apply supervised fine-tuning with multi-task learning to align the MLLM with the multimodal sequential recommendation. Extensive evaluations on common recommendation datasets demonstrate the effectiveness of MMSRARec, showcasing its capability to efficiently and interpretably understand user behavior histories and item information for accurate recommendations.
Animate Any Character in Any World
Dec 18, 2025Recent advances in world models have greatly enhanced interactive environment simulation. Existing methods mainly fall into two categories: (1) static world generation models, which construct 3D environments without active agents, and (2) controllable-entity models, which allow a single entity to perform limited actions in an otherwise uncontrollable environment. In this work, we introduce AniX, leveraging the realism and structural grounding of static world generation while extending controllable-entity models to support user-specified characters capable of performing open-ended actions. Users can provide a 3DGS scene and a character, then direct the character through natural language to perform diverse behaviors from basic locomotion to object-centric interactions while freely exploring the environment. AniX synthesizes temporally coherent video clips that preserve visual fidelity with the provided scene and character, formulated as a conditional autoregressive video generation problem. Built upon a pre-trained video generator, our training strategy significantly enhances motion dynamics while maintaining generalization across actions and characters. Our evaluation covers a broad range of aspects, including visual quality, character consistency, action controllability, and long-horizon coherence.
Why Did Apple Fall To The Ground: Evaluating Curiosity In Large Language Model
Oct 23, 2025Curiosity serves as a pivotal conduit for human beings to discover and learn new knowledge. Recent advancements of large language models (LLMs) in natural language processing have sparked discussions regarding whether these models possess capability of curiosity-driven learning akin to humans. In this paper, starting from the human curiosity assessment questionnaire Five-Dimensional Curiosity scale Revised (5DCR), we design a comprehensive evaluation framework that covers dimensions such as Information Seeking, Thrill Seeking, and Social Curiosity to assess the extent of curiosity exhibited by LLMs. The results demonstrate that LLMs exhibit a stronger thirst for knowledge than humans but still tend to make conservative choices when faced with uncertain environments. We further investigated the relationship between curiosity and thinking of LLMs, confirming that curious behaviors can enhance the model's reasoning and active learning abilities. These findings suggest that LLMs have the potential to exhibit curiosity similar to that of humans, providing experimental support for the future development of learning capabilities and innovative research in LLMs.
Real, Fake, or Manipulated? Detecting Machine-Influenced Text
Sep 18, 2025Large Language Model (LLMs) can be used to write or modify documents, presenting a challenge for understanding the intent behind their use. For example, benign uses may involve using LLM on a human-written document to improve its grammar or to translate it into another language. However, a document entirely produced by a LLM may be more likely to be used to spread misinformation than simple translation (\eg, from use by malicious actors or simply by hallucinating). Prior works in Machine Generated Text (MGT) detection mostly focus on simply identifying whether a document was human or machine written, ignoring these fine-grained uses. In this paper, we introduce a HiErarchical, length-RObust machine-influenced text detector (HERO), which learns to separate text samples of varying lengths from four primary types: human-written, machine-generated, machine-polished, and machine-translated. HERO accomplishes this by combining predictions from length-specialist models that have been trained with Subcategory Guidance. Specifically, for categories that are easily confused (\eg, different source languages), our Subcategory Guidance module encourages separation of the fine-grained categories, boosting performance. Extensive experiments across five LLMs and six domains demonstrate the benefits of our HERO, outperforming the state-of-the-art by 2.5-3 mAP on average.
OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
Aug 28, 2025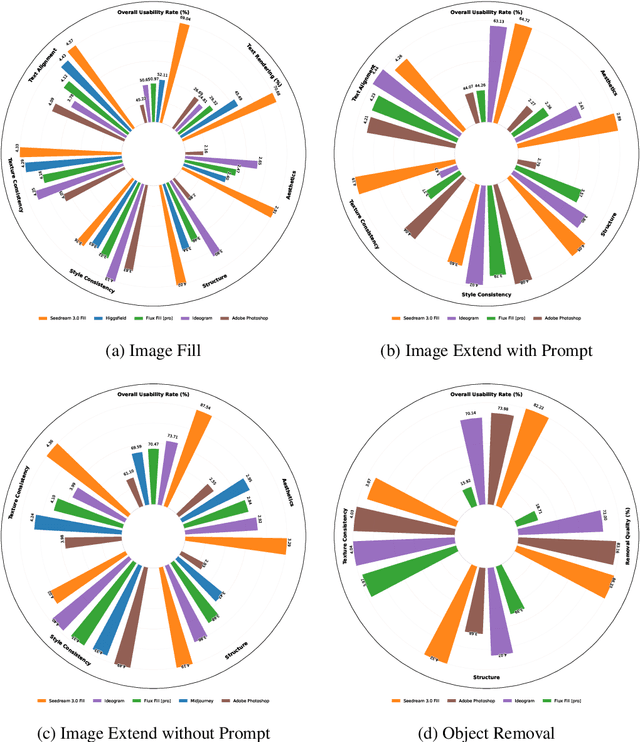

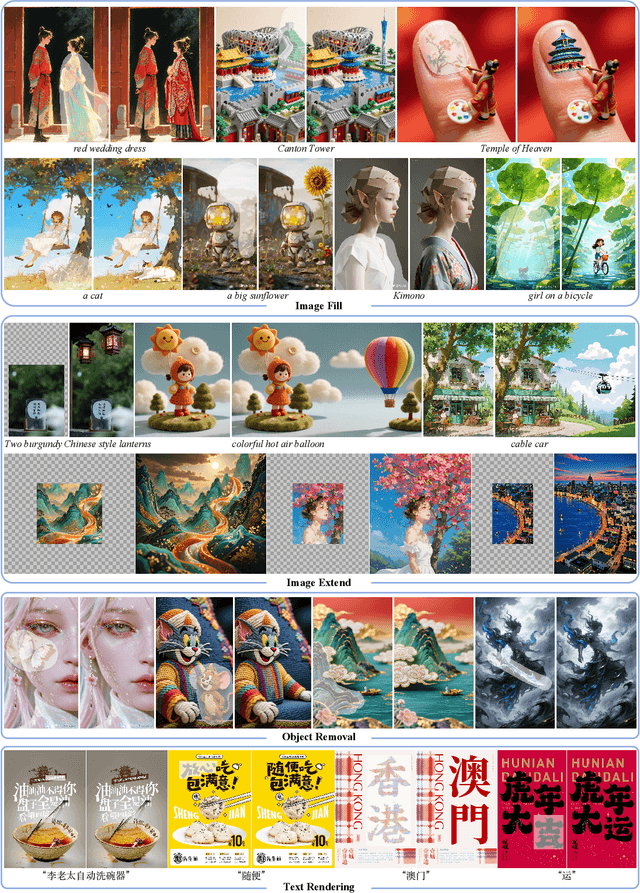
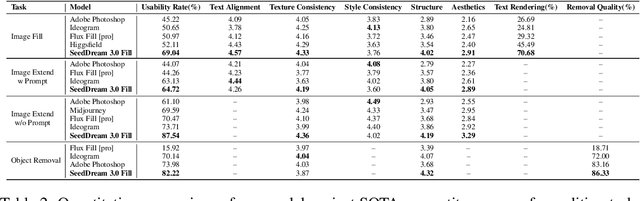
In this paper, we introduce OneReward, a unified reinforcement learning framework that enhances the model's generative capabilities across multiple tasks under different evaluation criteria using only \textit{One Reward} model. By employing a single vision-language model (VLM) as the generative reward model, which can distinguish the winner and loser for a given task and a given evaluation criterion, it can be effectively applied to multi-task generation models, particularly in contexts with varied data and diverse task objectives. We utilize OneReward for mask-guided image generation, which can be further divided into several sub-tasks such as image fill, image extend, object removal, and text rendering, involving a binary mask as the edit area. Although these domain-specific tasks share same conditioning paradigm, they differ significantly in underlying data distributions and evaluation metrics. Existing methods often rely on task-specific supervised fine-tuning (SFT), which limits generalization and training efficiency. Building on OneReward, we develop Seedream 3.0 Fill, a mask-guided generation model trained via multi-task reinforcement learning directly on a pre-trained base model, eliminating the need for task-specific SFT. Experimental results demonstrate that our unified edit model consistently outperforms both commercial and open-source competitors, such as Ideogram, Adobe Photoshop, and FLUX Fill [Pro], across multiple evaluation dimensions. Code and model are available at: https://one-reward.github.io
DreamVE: Unified Instruction-based Image and Video Editing
Aug 08, 2025Instruction-based editing holds vast potential due to its simple and efficient interactive editing format. However, instruction-based editing, particularly for video, has been constrained by limited training data, hindering its practical application. To this end, we introduce DreamVE, a unified model for instruction-based image and video editing. Specifically, We propose a two-stage training strategy: first image editing, then video editing. This offers two main benefits: (1) Image data scales more easily, and models are more efficient to train, providing useful priors for faster and better video editing training. (2) Unifying image and video generation is natural and aligns with current trends. Moreover, we present comprehensive training data synthesis pipelines, including collage-based and generative model-based data synthesis. The collage-based data synthesis combines foreground objects and backgrounds to generate diverse editing data, such as object manipulation, background changes, and text modifications. It can easily generate billions of accurate, consistent, realistic, and diverse editing pairs. We pretrain DreamVE on extensive collage-based data to achieve strong performance in key editing types and enhance generalization and transfer capabilities. However, collage-based data lacks some attribute editing cases, leading to a relative drop in performance. In contrast, the generative model-based pipeline, despite being hard to scale up, offers flexibility in handling attribute editing cases. Therefore, we use generative model-based data to further fine-tune DreamVE. Besides, we design an efficient and powerful editing framework for DreamVE. We build on the SOTA T2V model and use a token concatenation with early drop approach to inject source image guidance, ensuring strong consistency and editability. The codes and models will be released.
DreamLight: Towards Harmonious and Consistent Image Relighting
Jun 17, 2025We introduce a model named DreamLight for universal image relighting in this work, which can seamlessly composite subjects into a new background while maintaining aesthetic uniformity in terms of lighting and color tone. The background can be specified by natural images (image-based relighting) or generated from unlimited text prompts (text-based relighting). Existing studies primarily focus on image-based relighting, while with scant exploration into text-based scenarios. Some works employ intricate disentanglement pipeline designs relying on environment maps to provide relevant information, which grapples with the expensive data cost required for intrinsic decomposition and light source. Other methods take this task as an image translation problem and perform pixel-level transformation with autoencoder architecture. While these methods have achieved decent harmonization effects, they struggle to generate realistic and natural light interaction effects between the foreground and background. To alleviate these challenges, we reorganize the input data into a unified format and leverage the semantic prior provided by the pretrained diffusion model to facilitate the generation of natural results. Moreover, we propose a Position-Guided Light Adapter (PGLA) that condenses light information from different directions in the background into designed light query embeddings, and modulates the foreground with direction-biased masked attention. In addition, we present a post-processing module named Spectral Foreground Fixer (SFF) to adaptively reorganize different frequency components of subject and relighted background, which helps enhance the consistency of foreground appearance. Extensive comparisons and user study demonstrate that our DreamLight achieves remarkable relighting performance.
Private Transformer Inference in MLaaS: A Survey
May 15, 2025Transformer models have revolutionized AI, powering applications like content generation and sentiment analysis. However, their deployment in Machine Learning as a Service (MLaaS) raises significant privacy concerns, primarily due to the centralized processing of sensitive user data. Private Transformer Inference (PTI) offers a solution by utilizing cryptographic techniques such as secure multi-party computation and homomorphic encryption, enabling inference while preserving both user data and model privacy. This paper reviews recent PTI advancements, highlighting state-of-the-art solutions and challenges. We also introduce a structured taxonomy and evaluation framework for PTI, focusing on balancing resource efficiency with privacy and bridging the gap between high-performance inference and data privacy.