 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockDance: Reuse Structurally Similar Spatio-Temporal Features to Accelerate Diffusion Transformers
Mar 20, 2025Diffusion models have demonstrated impressive generation capabilities, particularly with recent advancements leveraging transformer architectures to improve both visual and artistic quality. However, Diffusion Transformers (DiTs) continue to encounter challenges related to low inference speed, primarily due to the iterative denoising process. To address this issue, we propose BlockDance, a training-free approach that explores feature similarities at adjacent time steps to accelerate DiTs. Unlike previous feature-reuse methods that lack tailored reuse strategies for features at different scales, BlockDance prioritizes the identification of the most structurally similar features, referred to as Structurally Similar Spatio-Temporal (STSS) features. These features are primarily located within the structure-focused blocks of the transformer during the later stages of denoising. BlockDance caches and reuses these highly similar features to mitigate redundant computation, thereby accelerating DiTs while maximizing consistency with the generated results of the original model. Furthermore, considering the diversity of generated content and the varying distributions of redundant features, we introduce BlockDance-Ada, a lightweight decision-making network tailored for instance-specific acceleration. BlockDance-Ada dynamically allocates resources and provides superior content quality. Both BlockDance and BlockDance-Ada have proven effective across various generation tasks and models, achieving accelerations between 25% and 50% while maintaining generation quality.
CreatiLayout: Siamese Multimodal Diffusion Transformer for Creative Layout-to-Image Generation
Dec 05, 2024



Diffusion models have been recognized for their ability to generate images that are not only visually appealing but also of high artistic quality. As a result, Layout-to-Image (L2I) generation has been proposed to leverage region-specific positions and descriptions to enable more precise and controllable generation. However, previous methods primarily focus on UNet-based models (e.g., SD1.5 and SDXL), and limited effort has explored Multimodal Diffusion Transformers (MM-DiTs), which have demonstrated powerful image generation capabilities. Enabling MM-DiT for layout-to-image generation seems straightforward but is challenging due to the complexity of how layout is introduced, integrated, and balanced among multiple modalities. To this end, we explore various network variants to efficiently incorporate layout guidance into MM-DiT, and ultimately present SiamLayout. To Inherit the advantages of MM-DiT, we use a separate set of network weights to process the layout, treating it as equally important as the image and text modalities. Meanwhile, to alleviate the competition among modalities, we decouple the image-layout interaction into a siamese branch alongside the image-text one and fuse them in the later stage. Moreover, we contribute a large-scale layout dataset, named LayoutSAM, which includes 2.7 million image-text pairs and 10.7 million entities. Each entity is annotated with a bounding box and a detailed description. We further construct the LayoutSAM-Eval benchmark as a comprehensive tool for evaluating the L2I generation quality. Finally, we introduce the Layout Designer, which taps into the potential of large language models in layout planning, transforming them into experts in layout generation and optimization. Our code, model, and dataset will be available at https://creatilayout.github.io.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018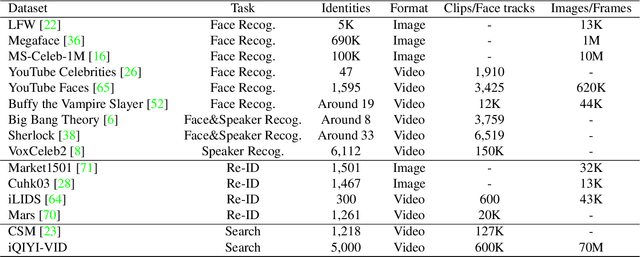

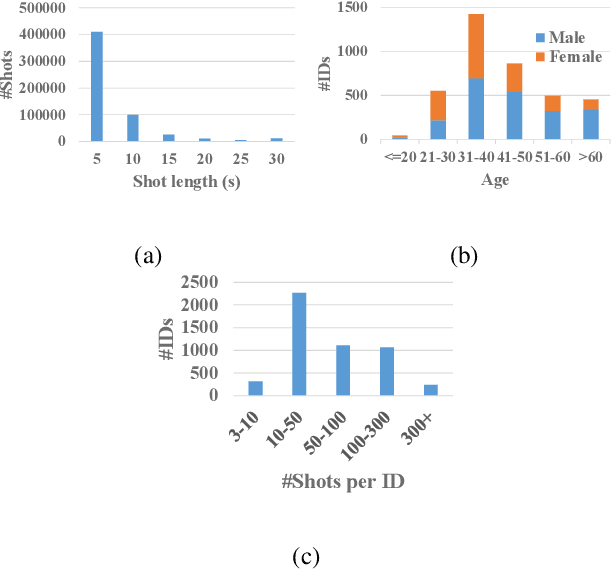
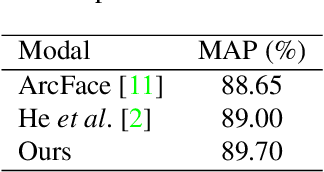
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.