 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018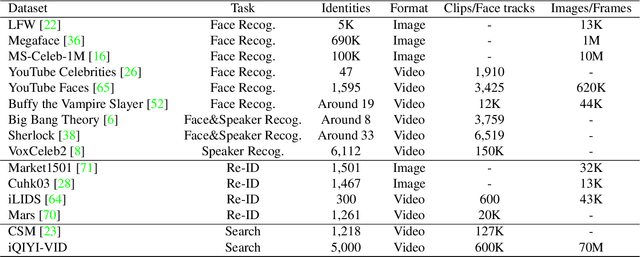

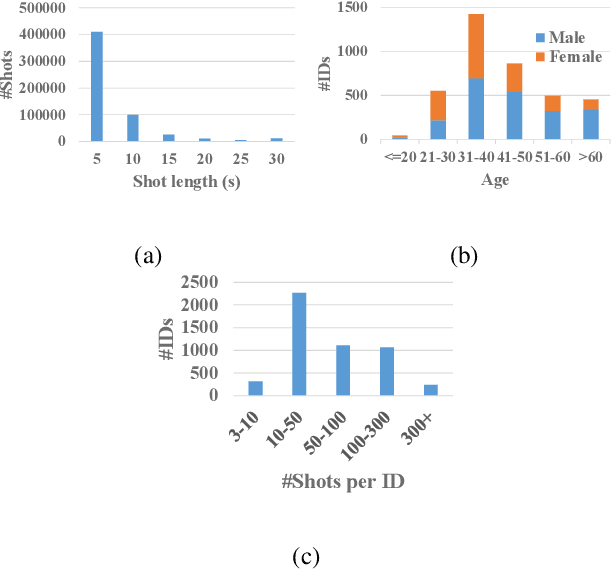
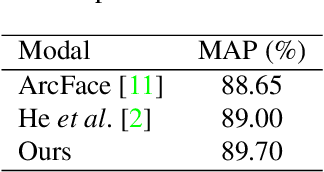
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.