 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Features with Flow Infused Attention for Realistic Virtual Try-On
Dec 16, 2024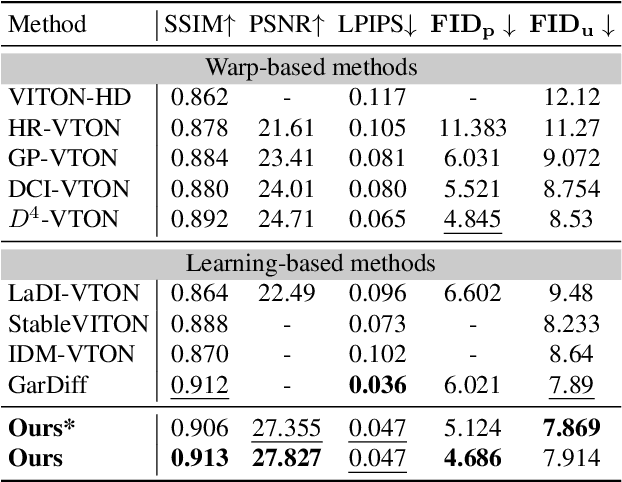
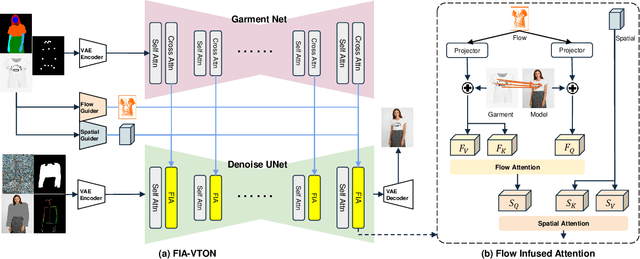
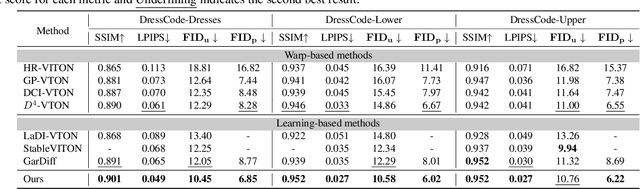

Image-based virtual try-on is challenging since the generated image should fit the garment to model images in various poses and keep the characteristics and details of the garment simultaneously. A popular research stream warps the garment image firstly to reduce the burden of the generation stage, which relies highly on the performance of the warping module. Other methods without explicit warping often lack sufficient guidance to fit the garment to the model images. In this paper, we propose FIA-VTON, which leverages the implicit warp feature by adopting a Flow Infused Attention module on virtual try-on. The dense warp flow map is projected as indirect guidance attention to enhance the feature map warping in the generation process implicitly, which is less sensitive to the warping estimation accuracy than an explicit warp of the garment image. To further enhance implicit warp guidance, we incorporate high-level spatial attention to complement the dense warp. Experimental results on the VTON-HD and DressCode dataset significantly outperform state-of-the-art methods, demonstrating that FIA-VTON is effective and robust for virtual try-on.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018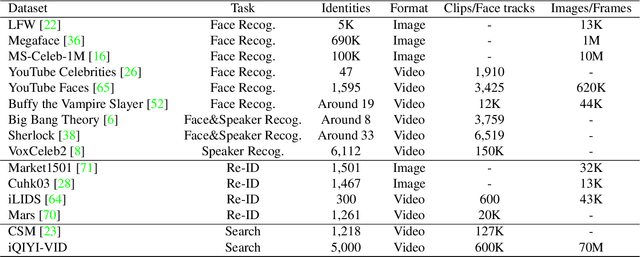

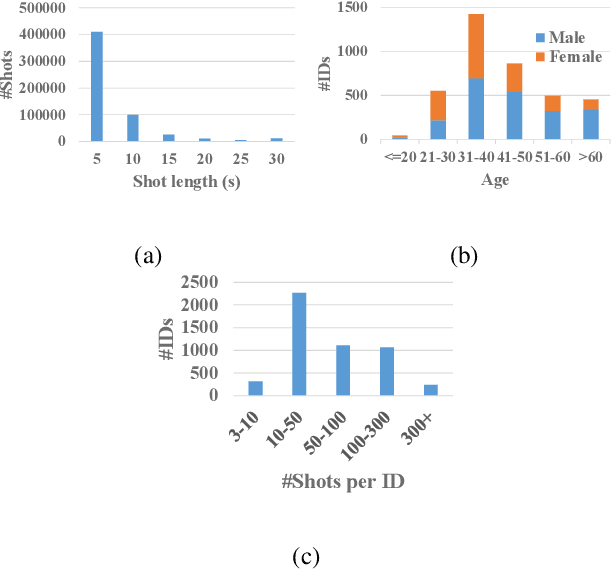
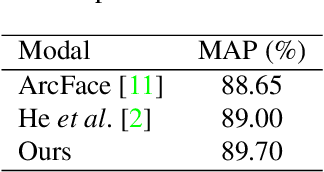
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.
Color naming guided intrinsic image decomposition
Oct 23, 2018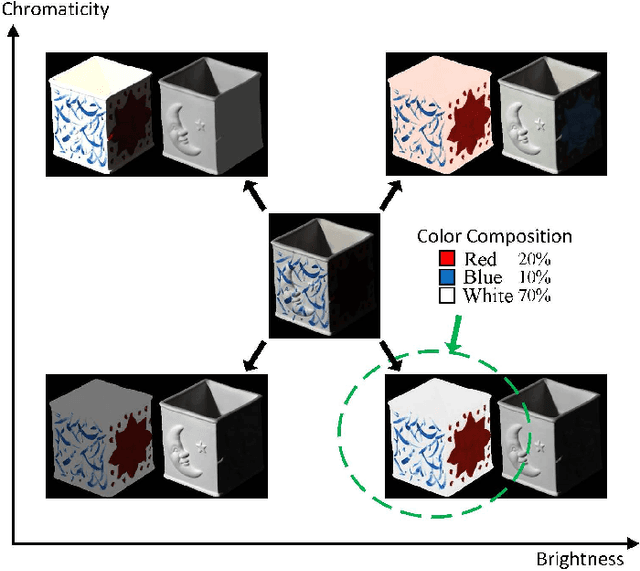
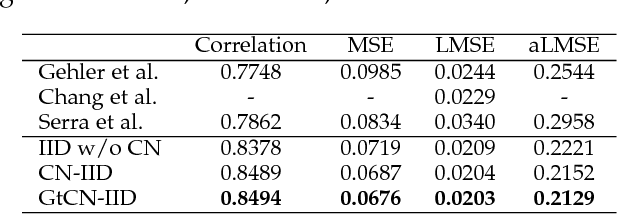
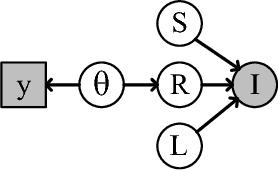
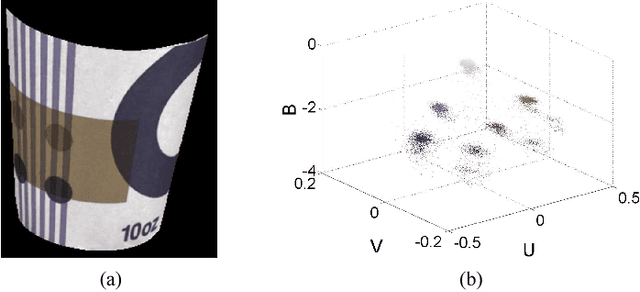
Intrinsic image decomposition is a severely under-constrained problem. User interactions can help to reduce the ambiguity of the decomposition considerably. The traditional way of user interaction is to draw scribbles that indicate regions with constant reflectance or shading. However the effect scopes of the scribbles are quite limited, so dozens of scribbles are often needed to rectify the whole decomposition, which is time consuming. In this paper we propose an efficient way of user interaction that users need only to annotate the color composition of the image. Color composition reveals the global distribution of reflectance, so it can help to adapt the whole decomposition directly. We build a generative model of the process that the albedo of the material produces both the reflectance through imaging and the color labels by color naming. Our model fuses effectively the physical properties of image formation and the top-down information from human color perception. Experimental results show that color naming can improve the performance of intrinsic image decomposition, especially in cleaning the shadows left in reflectance and solving the color constancy problem.
Consistency-aware Shading Orders Selective Fusion for Intrinsic Image Decomposition
Oct 23, 2018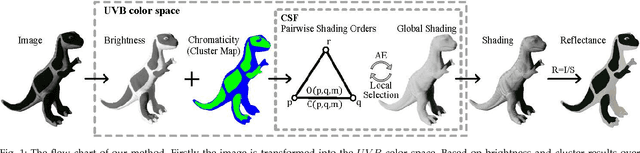
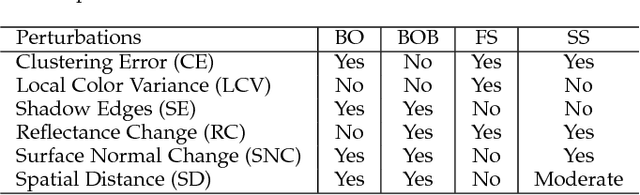
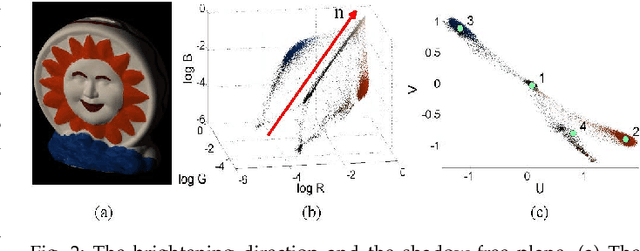
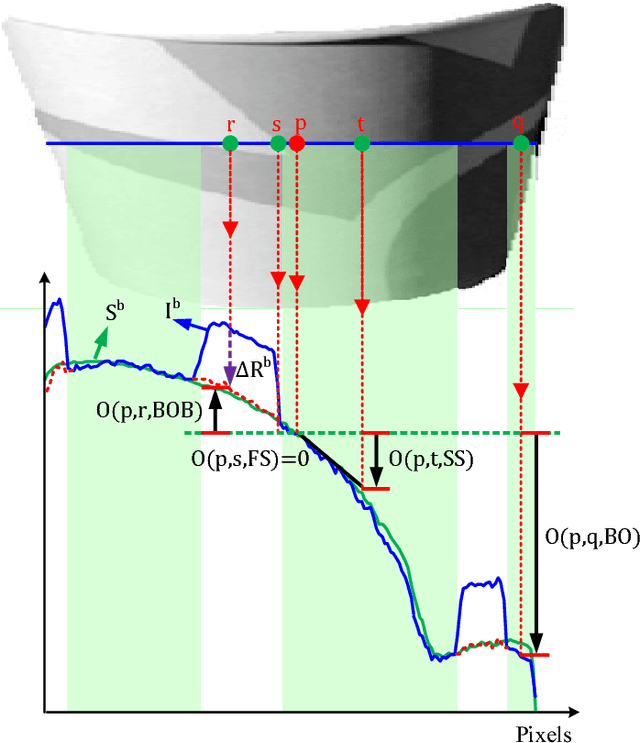
We address the problem of decomposing a single image into reflectance and shading. The difficulty comes from the fact that the components of image---the surface albedo, the direct illumination, and the ambient illumination---are coupled heavily in observed image. We propose to infer the shading by ordering pixels by their relative brightness, without knowing the absolute values of the image components beforehand. The pairwise shading orders are estimated in two ways: brightness order and low-order fittings of local shading field. The brightness order is a non-local measure, which can be applied to any pair of pixels including those whose reflectance and shading are both different. The low-order fittings are used for pixel pairs within local regions of smooth shading. Together, they can capture both global order structure and local variations of the shading. We propose a Consistency-aware Selective Fusion (CSF) to integrate the pairwise orders into a globally consistent order. The iterative selection process solves the conflicts between the pairwise orders obtained by different estimation methods. Inconsistent or unreliable pairwise orders will be automatically excluded from the fusion to avoid polluting the global order. Experiments on the MIT Intrinsic Image dataset show that the proposed model is effective at recovering the shading including deep shadows. Our model also works well on natural images from the IIW dataset, the UIUC Shadow dataset and the NYU-Depth dataset, where the colors of direct lights and ambient lights are quite different.