 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamFuse: Adaptive Image Fusion with Diffusion Transformer
Apr 11, 2025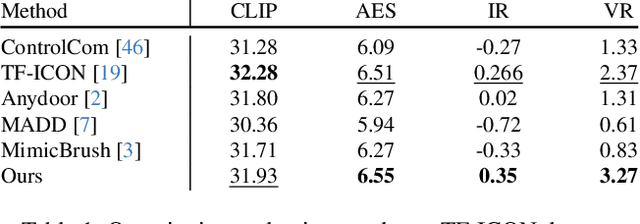
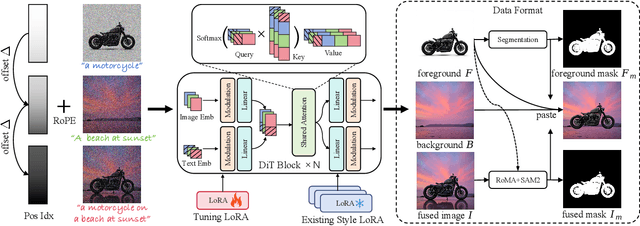
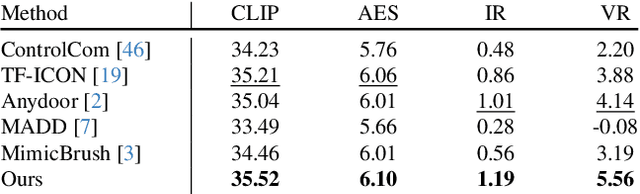
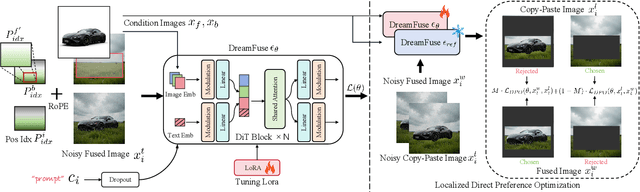
Image fusion seeks to seamlessly integrate foreground objects with background scenes, producing realistic and harmonious fused images. Unlike existing methods that directly insert objects into the background, adaptive and interactive fusion remains a challenging yet appealing task. It requires the foreground to adjust or interact with the background context, enabling more coherent integration. To address this, we propose an iterative human-in-the-loop data generation pipeline, which leverages limited initial data with diverse textual prompts to generate fusion datasets across various scenarios and interactions, including placement, holding, wearing, and style transfer. Building on this, we introduce DreamFuse, a novel approach based on the Diffusion Transformer (DiT) model, to generate consistent and harmonious fused images with both foreground and background information. DreamFuse employs a Positional Affine mechanism to inject the size and position of the foreground into the background, enabling effective foreground-background interaction through shared attention. Furthermore, we apply Localized Direct Preference Optimization guided by human feedback to refine DreamFuse, enhancing background consistency and foreground harmony. DreamFuse achieves harmonious fusion while generalizing to text-driven attribute editing of the fused results. Experimental results demonstrate that our method outperforms state-of-the-art approaches across multiple metrics.
DreamLayer: Simultaneous Multi-Layer Generation via Diffusion Mode
Mar 17, 2025



Text-driven image generation using diffusion models has recently gained significant attention. To enable more flexible image manipulation and editing, recent research has expanded from single image generation to transparent layer generation and multi-layer compositions. However, existing approaches often fail to provide a thorough exploration of multi-layer structures, leading to inconsistent inter-layer interactions, such as occlusion relationships, spatial layout, and shadowing. In this paper, we introduce DreamLayer, a novel framework that enables coherent text-driven generation of multiple image layers, by explicitly modeling the relationship between transparent foreground and background layers. DreamLayer incorporates three key components, i.e., Context-Aware Cross-Attention (CACA) for global-local information exchange, Layer-Shared Self-Attention (LSSA) for establishing robust inter-layer connections, and Information Retained Harmonization (IRH) for refining fusion details at the latent level. By leveraging a coherent full-image context, DreamLayer builds inter-layer connections through attention mechanisms and applies a harmonization step to achieve seamless layer fusion. To facilitate research in multi-layer generation, we construct a high-quality, diverse multi-layer dataset including 400k samples. Extensive experiments and user studies demonstrate that DreamLayer generates more coherent and well-aligned layers, with broad applicability, including latent-space image editing and image-to-layer decomposition.
FreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
Mar 30, 2023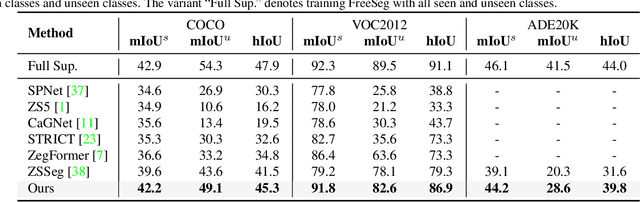
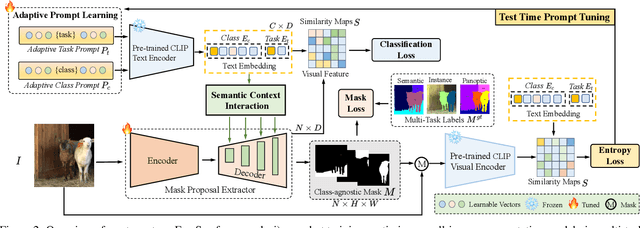
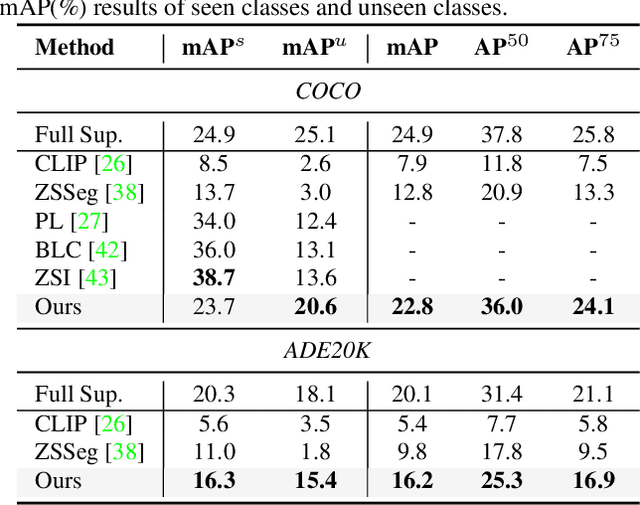
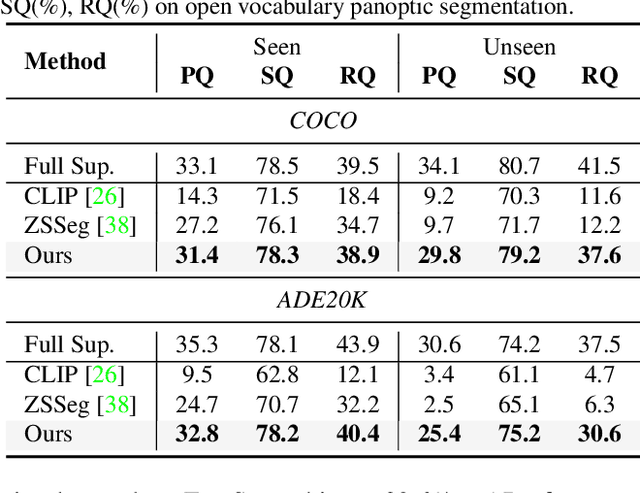
Recently, open-vocabulary learning has emerged to accomplish segmentation for arbitrary categories of text-based descriptions, which popularizes the segmentation system to more general-purpose application scenarios. However, existing methods devote to designing specialized architectures or parameters for specific segmentation tasks. These customized design paradigms lead to fragmentation between various segmentation tasks, thus hindering the uniformity of segmentation models. Hence in this paper, we propose FreeSeg, a generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation. FreeSeg optimizes an all-in-one network via one-shot training and employs the same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference procedure. Additionally, adaptive prompt learning facilitates the unified model to capture task-aware and category-sensitive concepts, improving model robustness in multi-task and varied scenarios. Extensive experimental results demonstrate that FreeSeg establishes new state-of-the-art results in performance and generalization on three segmentation tasks, which outperforms the best task-specific architectures by a large margin: 5.5% mIoU on semantic segmentation, 17.6% mAP on instance segmentation, 20.1% PQ on panoptic segmentation for the unseen class on COCO.
Unsupervised Domain Adaptive Salient Object Detection Through Uncertainty-Aware Pseudo-Label Learning
Feb 26, 2022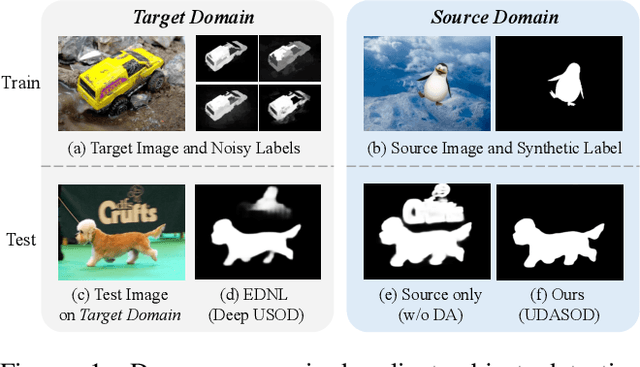
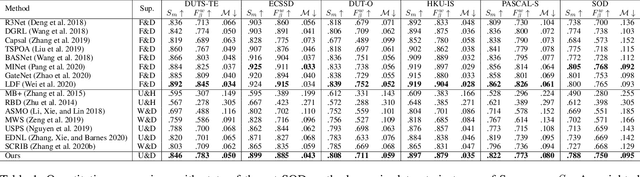


Recent advances in deep learning significantly boost the performance of salient object detection (SOD) at the expense of labeling larger-scale per-pixel annotations. To relieve the burden of labor-intensive labeling, deep unsupervised SOD methods have been proposed to exploit noisy labels generated by handcrafted saliency methods. However, it is still difficult to learn accurate saliency details from rough noisy labels. In this paper, we propose to learn saliency from synthetic but clean labels, which naturally has higher pixel-labeling quality without the effort of manual annotations. Specifically, we first construct a novel synthetic SOD dataset by a simple copy-paste strategy. Considering the large appearance differences between the synthetic and real-world scenarios, directly training with synthetic data will lead to performance degradation on real-world scenarios. To mitigate this problem, we propose a novel unsupervised domain adaptive SOD method to adapt between these two domains by uncertainty-aware self-training. Experimental results show that our proposed method outperforms the existing state-of-the-art deep unsupervised SOD methods on several benchmark datasets, and is even comparable to fully-supervised ones.
Semi-Supervised Video Salient Object Detection Using Pseudo-Labels
Aug 12, 2019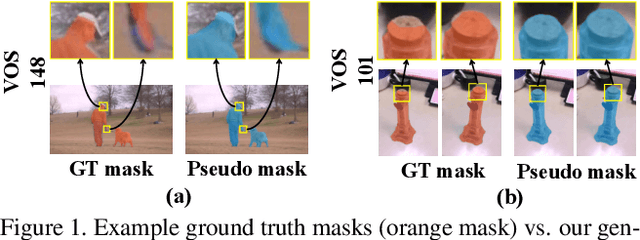

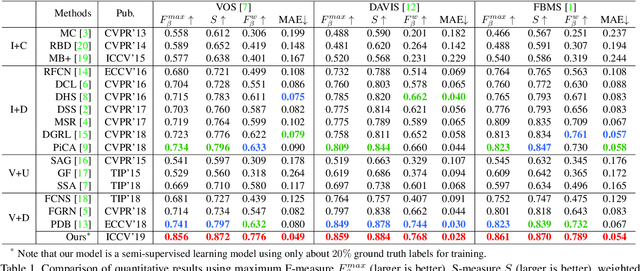
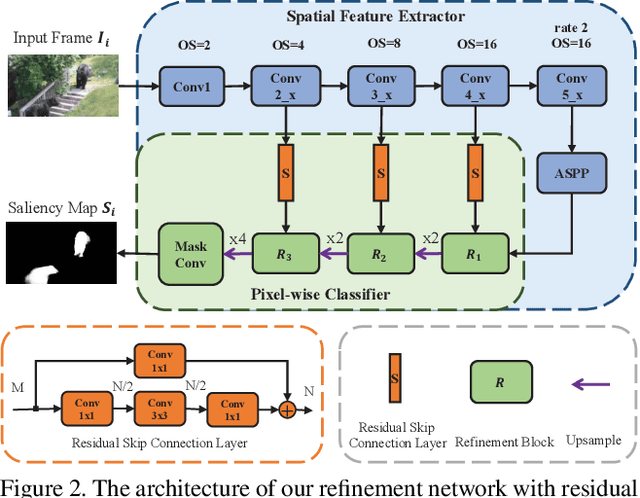
Deep learning-based video salient object detection has recently achieved great success with its performance significantly outperforming any other unsupervised methods. However, existing data-driven approaches heavily rely on a large quantity of pixel-wise annotated video frames to deliver such promising results. In this paper, we address the semi-supervised video salient object detection task using pseudo-labels. Specifically, we present an effective video saliency detector that consists of a spatial refinement network and a spatiotemporal module. Based on the same refinement network and motion information in terms of optical flow, we further propose a novel method for generating pixel-level pseudo-labels from sparsely annotated frames. By utilizing the generated pseudo-labels together with a part of manual annotations, our video saliency detector learns spatial and temporal cues for both contrast inference and coherence enhancement, thus producing accurate saliency maps. Experimental results demonstrate that our proposed semi-supervised method even greatly outperforms all the state-of-the-art fully supervised methods across three public benchmarks of VOS, DAVIS, and FBMS.