 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
Mar 30, 2023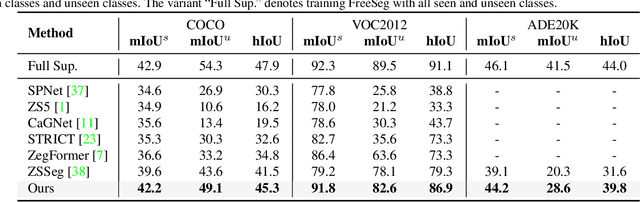
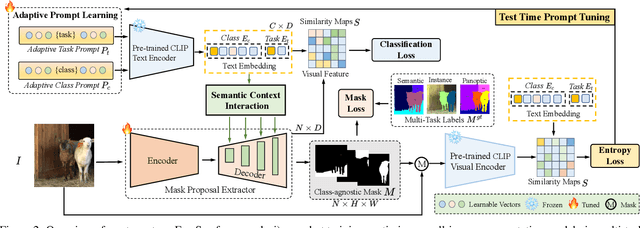
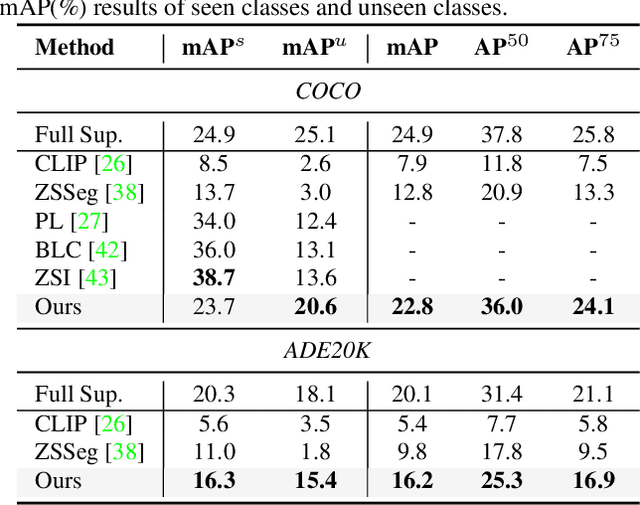
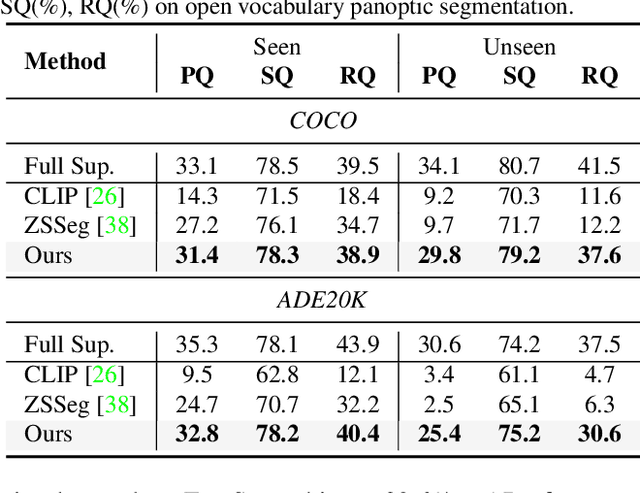
Recently, open-vocabulary learning has emerged to accomplish segmentation for arbitrary categories of text-based descriptions, which popularizes the segmentation system to more general-purpose application scenarios. However, existing methods devote to designing specialized architectures or parameters for specific segmentation tasks. These customized design paradigms lead to fragmentation between various segmentation tasks, thus hindering the uniformity of segmentation models. Hence in this paper, we propose FreeSeg, a generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation. FreeSeg optimizes an all-in-one network via one-shot training and employs the same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference procedure. Additionally, adaptive prompt learning facilitates the unified model to capture task-aware and category-sensitive concepts, improving model robustness in multi-task and varied scenarios. Extensive experimental results demonstrate that FreeSeg establishes new state-of-the-art results in performance and generalization on three segmentation tasks, which outperforms the best task-specific architectures by a large margin: 5.5% mIoU on semantic segmentation, 17.6% mAP on instance segmentation, 20.1% PQ on panoptic segmentation for the unseen class on COCO.