 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamFuse: Adaptive Image Fusion with Diffusion Transformer
Paper and Code
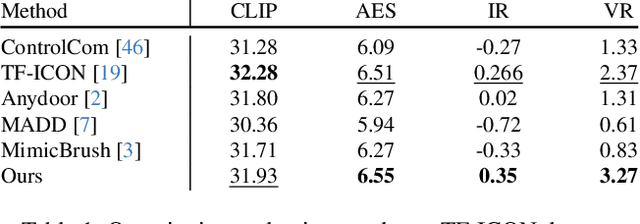
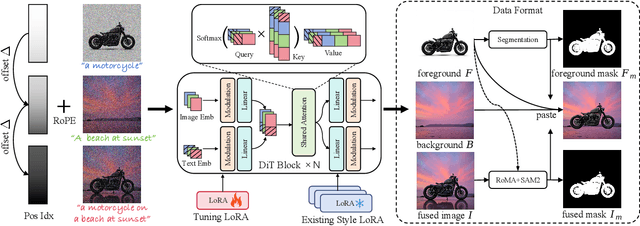
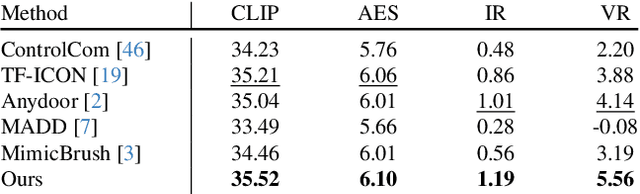
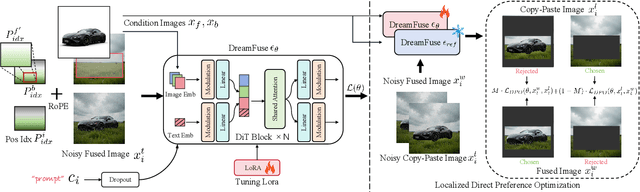
Image fusion seeks to seamlessly integrate foreground objects with background scenes, producing realistic and harmonious fused images. Unlike existing methods that directly insert objects into the background, adaptive and interactive fusion remains a challenging yet appealing task. It requires the foreground to adjust or interact with the background context, enabling more coherent integration. To address this, we propose an iterative human-in-the-loop data generation pipeline, which leverages limited initial data with diverse textual prompts to generate fusion datasets across various scenarios and interactions, including placement, holding, wearing, and style transfer. Building on this, we introduce DreamFuse, a novel approach based on the Diffusion Transformer (DiT) model, to generate consistent and harmonious fused images with both foreground and background information. DreamFuse employs a Positional Affine mechanism to inject the size and position of the foreground into the background, enabling effective foreground-background interaction through shared attention. Furthermore, we apply Localized Direct Preference Optimization guided by human feedback to refine DreamFuse, enhancing background consistency and foreground harmony. DreamFuse achieves harmonious fusion while generalizing to text-driven attribute editing of the fused results. Experimental results demonstrate that our method outperforms state-of-the-art approaches across multiple metrics.