 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Apr 02, 20263D indoor scene generation conditioned on short textual descriptions provides a promising avenue for interactive 3D environment construction without the need for labor-intensive layout specification. Despite recent progress in text-conditioned 3D scene generation, existing works suffer from poor physical plausibility and insufficient detail richness in such semantic condensation cases, largely due to their reliance on explicit semantic cues about compositional objects and their spatial relationships. This limitation highlights the need for enhanced 3D reasoning capabilities, particularly in terms of prior integration and spatial anchoring.Motivated by this, we propose SDesc3D, a short-text conditioned 3D indoor scene generation framework, that leverages multi-view structural priors and regional functionality implications to enable 3D layout reasoning under sparse textual guidance.Specifically, we introduce a Multi-view scene prior augmentation that enriches underspecified textual inputs with aggregated multi-view structural knowledge, shifting from inaccessible semantic relation cues to multi-view relational prior aggregation. Building on this, we design a Functionality-aware layout grounding, employing regional functionality grounding for implicit spatial anchors and conducting hierarchical layout reasoning to enhance scene organization and semantic plausibility.Furthermore, an Iterative reflection-rectification scheme is employed for progressive structural plausibility refinement via self-rectification.Extensive experiments show that our method outperforms existing approaches on short-text conditioned 3D indoor scene generation.Code will be publicly available.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
DreamFuse: Adaptive Image Fusion with Diffusion Transformer
Apr 11, 2025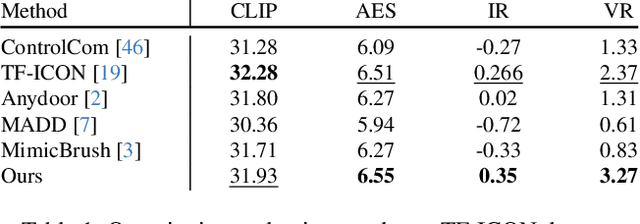
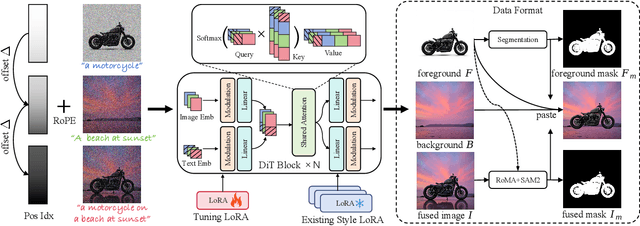
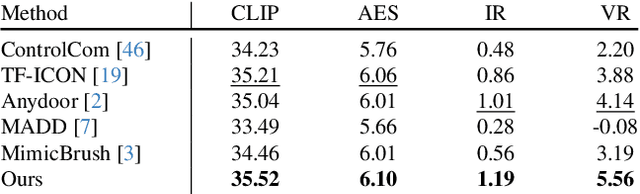
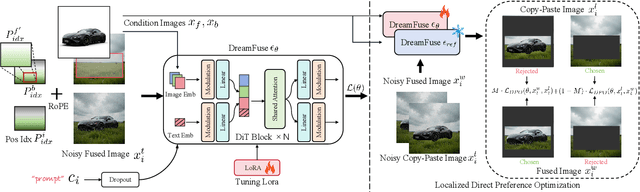
Image fusion seeks to seamlessly integrate foreground objects with background scenes, producing realistic and harmonious fused images. Unlike existing methods that directly insert objects into the background, adaptive and interactive fusion remains a challenging yet appealing task. It requires the foreground to adjust or interact with the background context, enabling more coherent integration. To address this, we propose an iterative human-in-the-loop data generation pipeline, which leverages limited initial data with diverse textual prompts to generate fusion datasets across various scenarios and interactions, including placement, holding, wearing, and style transfer. Building on this, we introduce DreamFuse, a novel approach based on the Diffusion Transformer (DiT) model, to generate consistent and harmonious fused images with both foreground and background information. DreamFuse employs a Positional Affine mechanism to inject the size and position of the foreground into the background, enabling effective foreground-background interaction through shared attention. Furthermore, we apply Localized Direct Preference Optimization guided by human feedback to refine DreamFuse, enhancing background consistency and foreground harmony. DreamFuse achieves harmonious fusion while generalizing to text-driven attribute editing of the fused results. Experimental results demonstrate that our method outperforms state-of-the-art approaches across multiple metrics.
DreamLayer: Simultaneous Multi-Layer Generation via Diffusion Mode
Mar 17, 2025



Text-driven image generation using diffusion models has recently gained significant attention. To enable more flexible image manipulation and editing, recent research has expanded from single image generation to transparent layer generation and multi-layer compositions. However, existing approaches often fail to provide a thorough exploration of multi-layer structures, leading to inconsistent inter-layer interactions, such as occlusion relationships, spatial layout, and shadowing. In this paper, we introduce DreamLayer, a novel framework that enables coherent text-driven generation of multiple image layers, by explicitly modeling the relationship between transparent foreground and background layers. DreamLayer incorporates three key components, i.e., Context-Aware Cross-Attention (CACA) for global-local information exchange, Layer-Shared Self-Attention (LSSA) for establishing robust inter-layer connections, and Information Retained Harmonization (IRH) for refining fusion details at the latent level. By leveraging a coherent full-image context, DreamLayer builds inter-layer connections through attention mechanisms and applies a harmonization step to achieve seamless layer fusion. To facilitate research in multi-layer generation, we construct a high-quality, diverse multi-layer dataset including 400k samples. Extensive experiments and user studies demonstrate that DreamLayer generates more coherent and well-aligned layers, with broad applicability, including latent-space image editing and image-to-layer decomposition.
UniCell: Universal Cell Nucleus Classification via Prompt Learning
Feb 20, 2024



The recognition of multi-class cell nuclei can significantly facilitate the process of histopathological diagnosis. Numerous pathological datasets are currently available, but their annotations are inconsistent. Most existing methods require individual training on each dataset to deduce the relevant labels and lack the use of common knowledge across datasets, consequently restricting the quality of recognition. In this paper, we propose a universal cell nucleus classification framework (UniCell), which employs a novel prompt learning mechanism to uniformly predict the corresponding categories of pathological images from different dataset domains. In particular, our framework adopts an end-to-end architecture for nuclei detection and classification, and utilizes flexible prediction heads for adapting various datasets. Moreover, we develop a Dynamic Prompt Module (DPM) that exploits the properties of multiple datasets to enhance features. The DPM first integrates the embeddings of datasets and semantic categories, and then employs the integrated prompts to refine image representations, efficiently harvesting the shared knowledge among the related cell types and data sources. Experimental results demonstrate that the proposed method effectively achieves the state-of-the-art results on four nucleus detection and classification benchmarks. Code and models are available at https://github.com/lhaof/UniCell
Prompt-based Grouping Transformer for Nucleus Detection and Classification
Oct 22, 2023Automatic nuclei detection and classification can produce effective information for disease diagnosis. Most existing methods classify nuclei independently or do not make full use of the semantic similarity between nuclei and their grouping features. In this paper, we propose a novel end-to-end nuclei detection and classification framework based on a grouping transformer-based classifier. The nuclei classifier learns and updates the representations of nuclei groups and categories via hierarchically grouping the nucleus embeddings. Then the cell types are predicted with the pairwise correlations between categorical embeddings and nucleus features. For the efficiency of the fully transformer-based framework, we take the nucleus group embeddings as the input prompts of backbone, which helps harvest grouping guided features by tuning only the prompts instead of the whole backbone. Experimental results show that the proposed method significantly outperforms the existing models on three datasets.
Affine-Consistent Transformer for Multi-Class Cell Nuclei Detection
Oct 22, 2023



Multi-class cell nuclei detection is a fundamental prerequisite in the diagnosis of histopathology. It is critical to efficiently locate and identify cells with diverse morphology and distributions in digital pathological images. Most existing methods take complex intermediate representations as learning targets and rely on inflexible post-refinements while paying less attention to various cell density and fields of view. In this paper, we propose a novel Affine-Consistent Transformer (AC-Former), which directly yields a sequence of nucleus positions and is trained collaboratively through two sub-networks, a global and a local network. The local branch learns to infer distorted input images of smaller scales while the global network outputs the large-scale predictions as extra supervision signals. We further introduce an Adaptive Affine Transformer (AAT) module, which can automatically learn the key spatial transformations to warp original images for local network training. The AAT module works by learning to capture the transformed image regions that are more valuable for training the model. Experimental results demonstrate that the proposed method significantly outperforms existing state-of-the-art algorithms on various benchmarks.
Myopia prediction for adolescents via time-aware deep learning
Sep 26, 2022
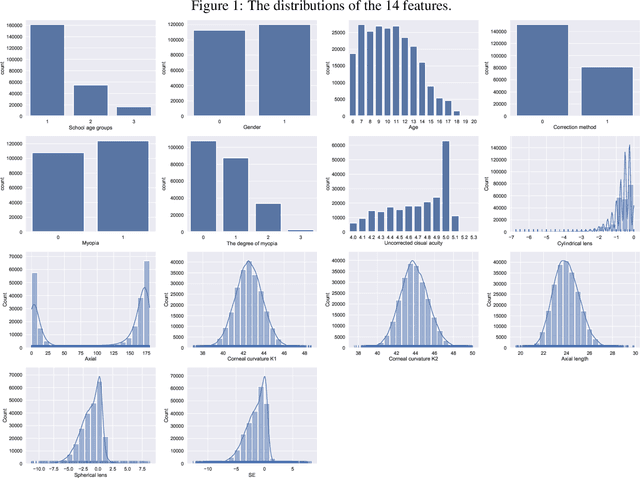

Background: Quantitative prediction of the adolescents' spherical equivalent based on their variable-length historical vision records. Methods: From October 2019 to March 2022, we examined binocular uncorrected visual acuity, axial length, corneal curvature, and axial of 75,172 eyes from 37,586 adolescents aged 6-20 years in Chengdu, China. 80\% samples consist of the training set and the remaining 20\% form the testing set. Time-Aware Long Short-Term Memory was used to quantitatively predict the adolescents' spherical equivalent within two and a half years. Result: The mean absolute prediction error on the testing set was 0.273-0.257 for spherical equivalent, ranging from 0.189-0.160 to 0.596-0.473 if we consider different lengths of historical records and different prediction durations. Conclusions: Time-Aware Long Short-Term Memory was applied to captured the temporal features in irregularly sampled time series, which is more in line with the characteristics of real data and thus has higher applicability, and helps to identify the progression of myopia earlier. The overall error 0.273 is much smaller than the criterion for clinically acceptable prediction, say 0.75.
View-Disentangled Transformer for Brain Lesion Detection
Sep 20, 2022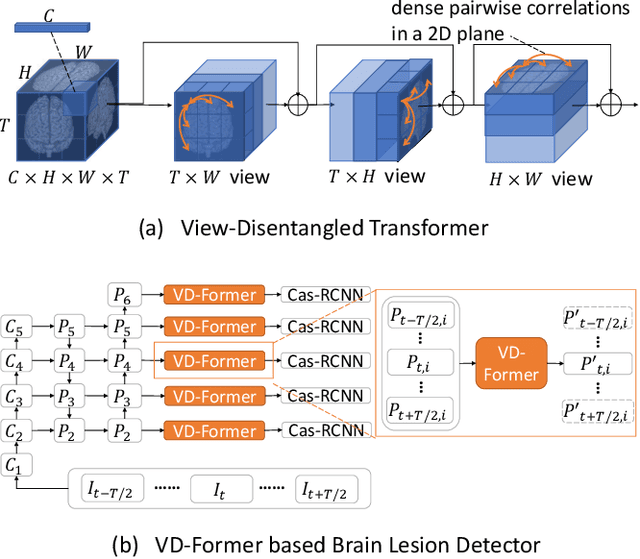
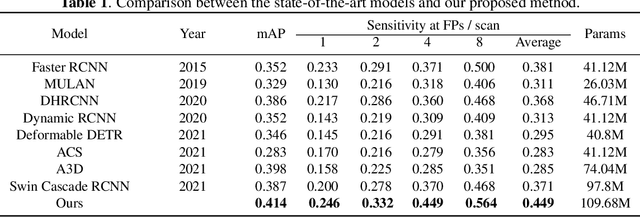

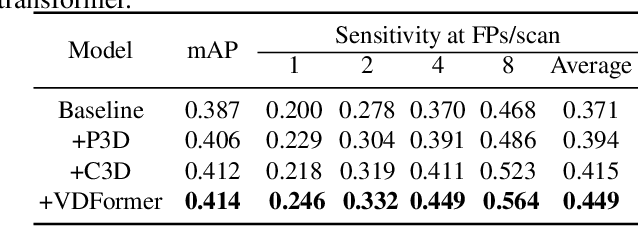
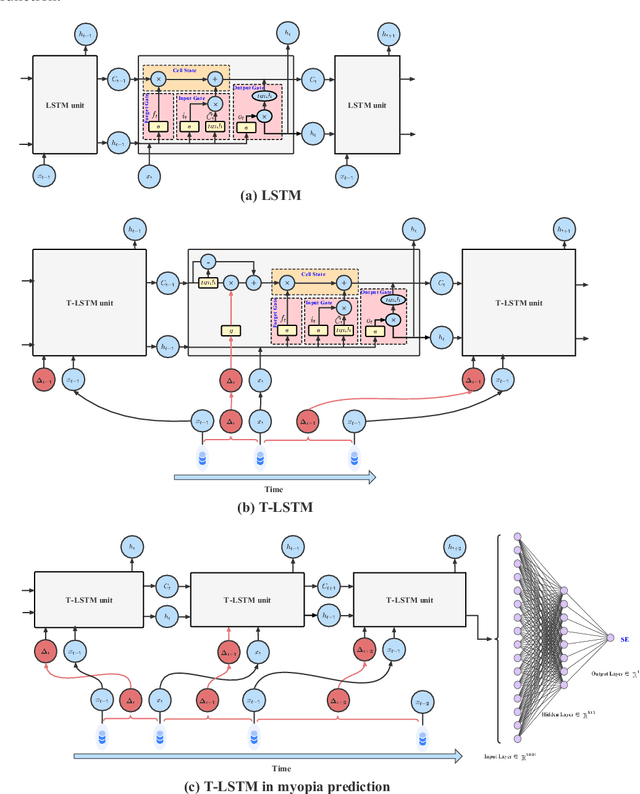
Deep neural networks (DNNs) have been widely adopted in brain lesion detection and segmentation. However, locating small lesions in 2D MRI slices is challenging, and requires to balance between the granularity of 3D context aggregation and the computational complexity. In this paper, we propose a novel view-disentangled transformer to enhance the extraction of MRI features for more accurate tumour detection. First, the proposed transformer harvests long-range correlation among different positions in a 3D brain scan. Second, the transformer models a stack of slice features as multiple 2D views and enhance these features view-by-view, which approximately achieves the 3D correlation computing in an efficient way. Third, we deploy the proposed transformer module in a transformer backbone, which can effectively detect the 2D regions surrounding brain lesions. The experimental results show that our proposed view-disentangled transformer performs well for brain lesion detection on a challenging brain MRI dataset.
Attentive Symmetric Autoencoder for Brain MRI Segmentation
Sep 19, 2022Self-supervised learning methods based on image patch reconstruction have witnessed great success in training auto-encoders, whose pre-trained weights can be transferred to fine-tune other downstream tasks of image understanding. However, existing methods seldom study the various importance of reconstructed patches and the symmetry of anatomical structures, when they are applied to 3D medical images. In this paper we propose a novel Attentive Symmetric Auto-encoder (ASA) based on Vision Transformer (ViT) for 3D brain MRI segmentation tasks. We conjecture that forcing the auto-encoder to recover informative image regions can harvest more discriminative representations, than to recover smooth image patches. Then we adopt a gradient based metric to estimate the importance of each image patch. In the pre-training stage, the proposed auto-encoder pays more attention to reconstruct the informative patches according to the gradient metrics. Moreover, we resort to the prior of brain structures and develop a Symmetric Position Encoding (SPE) method to better exploit the correlations between long-range but spatially symmetric regions to obtain effective features. Experimental results show that our proposed attentive symmetric auto-encoder outperforms the state-of-the-art self-supervised learning methods and medical image segmentation models on three brain MRI segmentation benchmarks.