 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamLayer: Simultaneous Multi-Layer Generation via Diffusion Mode
Mar 17, 2025



Text-driven image generation using diffusion models has recently gained significant attention. To enable more flexible image manipulation and editing, recent research has expanded from single image generation to transparent layer generation and multi-layer compositions. However, existing approaches often fail to provide a thorough exploration of multi-layer structures, leading to inconsistent inter-layer interactions, such as occlusion relationships, spatial layout, and shadowing. In this paper, we introduce DreamLayer, a novel framework that enables coherent text-driven generation of multiple image layers, by explicitly modeling the relationship between transparent foreground and background layers. DreamLayer incorporates three key components, i.e., Context-Aware Cross-Attention (CACA) for global-local information exchange, Layer-Shared Self-Attention (LSSA) for establishing robust inter-layer connections, and Information Retained Harmonization (IRH) for refining fusion details at the latent level. By leveraging a coherent full-image context, DreamLayer builds inter-layer connections through attention mechanisms and applies a harmonization step to achieve seamless layer fusion. To facilitate research in multi-layer generation, we construct a high-quality, diverse multi-layer dataset including 400k samples. Extensive experiments and user studies demonstrate that DreamLayer generates more coherent and well-aligned layers, with broad applicability, including latent-space image editing and image-to-layer decomposition.
Parallel Pre-trained Transformers (PPT) for Synthetic Data-based Instance Segmentation
Jun 22, 2022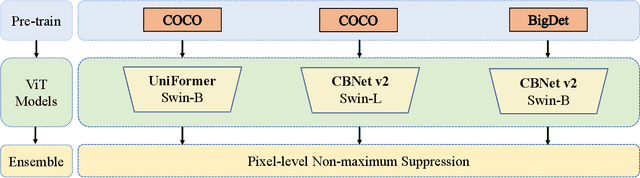


Recently, Synthetic data-based Instance Segmentation has become an exceedingly favorable optimization paradigm since it leverages simulation rendering and physics to generate high-quality image-annotation pairs. In this paper, we propose a Parallel Pre-trained Transformers (PPT) framework to accomplish the synthetic data-based Instance Segmentation task. Specifically, we leverage the off-the-shelf pre-trained vision Transformers to alleviate the gap between natural and synthetic data, which helps to provide good generalization in the downstream synthetic data scene with few samples. Swin-B-based CBNet V2, SwinL-based CBNet V2 and Swin-L-based Uniformer are employed for parallel feature learning, and the results of these three models are fused by pixel-level Non-maximum Suppression (NMS) algorithm to obtain more robust results. The experimental results reveal that PPT ranks first in the CVPR2022 AVA Accessibility Vision and Autonomy Challenge, with a 65.155% mAP.