 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
May 31, 2026With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
DriveVA: Video Action Models are Zero-Shot Drivers
Apr 05, 2026Generalization is a central challenge in autonomous driving, as real-world deployment requires robust performance under unseen scenarios, sensor domains, and environmental conditions. Recent world-model-based planning methods have shown strong capabilities in scene understanding and multi-modal future prediction, yet their generalization across datasets and sensor configurations remains limited. In addition, their loosely coupled planning paradigm often leads to poor video-trajectory consistency during visual imagination. To overcome these limitations, we propose DriveVA, a novel autonomous driving world model that jointly decodes future visual forecasts and action sequences in a shared latent generative process. DriveVA inherits rich priors on motion dynamics and physical plausibility from well-pretrained large-scale video generation models to capture continuous spatiotemporal evolution and causal interaction patterns. To this end, DriveVA employs a DiT-based decoder to jointly predict future action sequences (trajectories) and videos, enabling tighter alignment between planning and scene evolution. We also introduce a video continuation strategy to strengthen long-duration rollout consistency. DriveVA achieves an impressive closed-loop performance of 90.9 PDM score on the challenge NAVSIM. Extensive experiments also demonstrate the zero-shot capability and cross-domain generalization of DriveVA, which reduces average L2 error and collision rate by 78.9% and 83.3% on nuScenes and 52.5% and 52.4% on the Bench2drive built on CARLA v2 compared with the state-of-the-art world-model-based planner.
RegFormer++: An Efficient Large-Scale 3D LiDAR Point Registration Network with Projection-Aware 2D Transformer
Mar 15, 2026Although point cloud registration has achieved remarkable advances in object-level and indoor scenes, large-scale LiDAR registration methods has been rarely explored before. Challenges mainly arise from the huge point scale, complex point distribution, and numerous outliers within outdoor LiDAR scans. In addition, most existing registration works generally adopt a two-stage paradigm: They first find correspondences by extracting discriminative local descriptors and then leverage robust estimators (e.g. RANSAC) to filter outliers, which are highly dependent on well-designed descriptors and post-processing choices. To address these problems, we propose a novel end-to-end differential transformer network, termed RegFormer++, for large-scale point cloud alignment without requiring any further post-processing. Specifically, a hierarchical projection-aware 2D transformer with linear complexity is proposed to project raw LiDAR points onto a cylindrical surface and extract global point features, which can improve resilience to outliers due to long-range dependencies. Because we fill original 3D coordinates into 2D projected positions, our designed transformer can benefit from both high efficiency in 2D processing and accuracy from 3D geometric information. Furthermore, to effectively reduce wrong point matching, a Bijective Association Transformer (BAT) is designed, combining both cross attention and all-to-all point gathering. To improve training stability and robustness, a feature-transformed optimal transport module is also designed for regressing the final pose transformation. Extensive experiments on KITTI, NuScenes, and Argoverse datasets demonstrate that our model achieves state-of-the-art performance in terms of both accuracy and efficiency.
4DSTR: Advancing Generative 4D Gaussians with Spatial-Temporal Rectification for High-Quality and Consistent 4D Generation
Nov 10, 2025Remarkable advances in recent 2D image and 3D shape generation have induced a significant focus on dynamic 4D content generation. However, previous 4D generation methods commonly struggle to maintain spatial-temporal consistency and adapt poorly to rapid temporal variations, due to the lack of effective spatial-temporal modeling. To address these problems, we propose a novel 4D generation network called 4DSTR, which modulates generative 4D Gaussian Splatting with spatial-temporal rectification. Specifically, temporal correlation across generated 4D sequences is designed to rectify deformable scales and rotations and guarantee temporal consistency. Furthermore, an adaptive spatial densification and pruning strategy is proposed to address significant temporal variations by dynamically adding or deleting Gaussian points with the awareness of their pre-frame movements. Extensive experiments demonstrate that our 4DSTR achieves state-of-the-art performance in video-to-4D generation, excelling in reconstruction quality, spatial-temporal consistency, and adaptation to rapid temporal movements.
TopoLiDM: Topology-Aware LiDAR Diffusion Models for Interpretable and Realistic LiDAR Point Cloud Generation
Jul 30, 2025LiDAR scene generation is critical for mitigating real-world LiDAR data collection costs and enhancing the robustness of downstream perception tasks in autonomous driving. However, existing methods commonly struggle to capture geometric realism and global topological consistency. Recent LiDAR Diffusion Models (LiDMs) predominantly embed LiDAR points into the latent space for improved generation efficiency, which limits their interpretable ability to model detailed geometric structures and preserve global topological consistency. To address these challenges, we propose TopoLiDM, a novel framework that integrates graph neural networks (GNNs) with diffusion models under topological regularization for high-fidelity LiDAR generation. Our approach first trains a topological-preserving VAE to extract latent graph representations by graph construction and multiple graph convolutional layers. Then we freeze the VAE and generate novel latent topological graphs through the latent diffusion models. We also introduce 0-dimensional persistent homology (PH) constraints, ensuring the generated LiDAR scenes adhere to real-world global topological structures. Extensive experiments on the KITTI-360 dataset demonstrate TopoLiDM's superiority over state-of-the-art methods, achieving improvements of 22.6% lower Frechet Range Image Distance (FRID) and 9.2% lower Minimum Matching Distance (MMD). Notably, our model also enables fast generation speed with an average inference time of 1.68 samples/s, showcasing its scalability for real-world applications. We will release the related codes at https://github.com/IRMVLab/TopoLiDM.
Factual Serialization Enhancement: A Key Innovation for Chest X-ray Report Generation
May 15, 2024The automation of writing imaging reports is a valuable tool for alleviating the workload of radiologists. Crucial steps in this process involve the cross-modal alignment between medical images and reports, as well as the retrieval of similar historical cases. However, the presence of presentation-style vocabulary (e.g., sentence structure and grammar) in reports poses challenges for cross-modal alignment. Additionally, existing methods for similar historical cases retrieval face suboptimal performance owing to the modal gap issue. In response, this paper introduces a novel method, named Factual Serialization Enhancement (FSE), for chest X-ray report generation. FSE begins with the structural entities approach to eliminate presentation-style vocabulary in reports, providing specific input for our model. Then, uni-modal features are learned through cross-modal alignment between images and factual serialization in reports. Subsequently, we present a novel approach to retrieve similar historical cases from the training set, leveraging aligned image features. These features implicitly preserve semantic similarity with their corresponding reference reports, enabling us to calculate similarity solely among aligned features. This effectively eliminates the modal gap issue for knowledge retrieval without the requirement for disease labels. Finally, the cross-modal fusion network is employed to query valuable information from these cases, enriching image features and aiding the text decoder in generating high-quality reports. Experiments on MIMIC-CXR and IU X-ray datasets from both specific and general scenarios demonstrate the superiority of FSE over state-of-the-art approaches in both natural language generation and clinical efficacy metrics.
Tracing the Influence of Predecessors on Trajectory Prediction
Aug 10, 2023In real-world traffic scenarios, agents such as pedestrians and car drivers often observe neighboring agents who exhibit similar behavior as examples and then mimic their actions to some extent in their own behavior. This information can serve as prior knowledge for trajectory prediction, which is unfortunately largely overlooked in current trajectory prediction models. This paper introduces a novel Predecessor-and-Successor (PnS) method that incorporates a predecessor tracing module to model the influence of predecessors (identified from concurrent neighboring agents) on the successor (target agent) within the same scene. The method utilizes the moving patterns of these predecessors to guide the predictor in trajectory prediction. PnS effectively aligns the motion encodings of the successor with multiple potential predecessors in a probabilistic manner, facilitating the decoding process. We demonstrate the effectiveness of PnS by integrating it into a graph-based predictor for pedestrian trajectory prediction on the ETH/UCY datasets, resulting in a new state-of-the-art performance. Furthermore, we replace the HD map-based scene-context module with our PnS method in a transformer-based predictor for vehicle trajectory prediction on the nuScenes dataset, showing that the predictor maintains good prediction performance even without relying on any map information.
Reduced-Complexity Cross-Domain Iterative Detection for OTFS Modulation via Delay-Doppler Decoupling
Jul 03, 2023In this paper, a reduced-complexity cross-domain iterative detection for orthogonal time frequency space (OTFS) modulation is proposed, which exploits channel properties in both time and delay-Doppler domains. Specifically, we first show that in the time domain effective channel, the path delay only introduces interference among samples in adjacent time slots, while the Doppler becomes a phase term that does not affect the channel sparsity. This ``band-limited'' matrix structure motivates us to apply a reduced-size linear minimum mean square error (LMMSE) filter to eliminate the effect of delay in the time domain, while exploiting the cross-domain iteration for minimizing the effect of Doppler by noticing that the time and Doppler are a pair of Fourier dual. The state (MSE) evolution was derived and compared with bounds to verify the effectiveness of the proposed scheme. Simulation results demonstrate that the proposed scheme achieves almost the same error performance as the optimal detection, but only requires a reduced complexity.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.
GATraj: A Graph- and Attention-based Multi-Agent Trajectory Prediction Model
Sep 16, 2022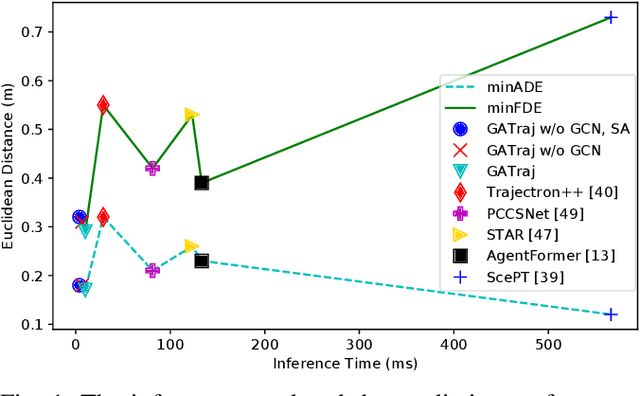

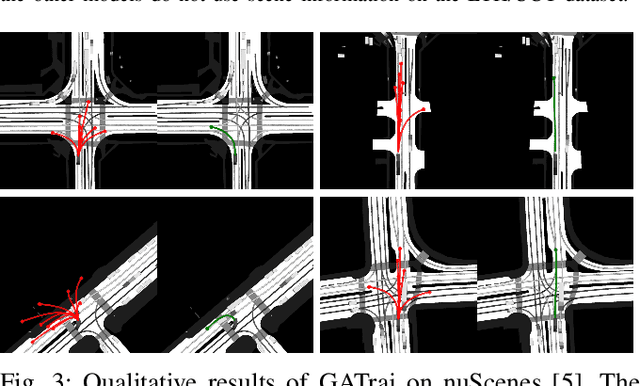
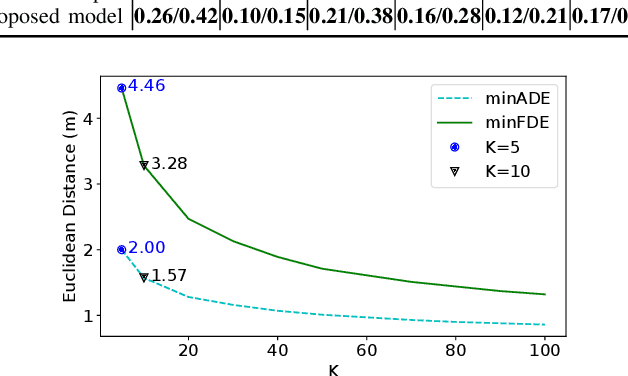
Trajectory prediction has been a long-standing problem in intelligent systems such as autonomous driving and robot navigation. Recent state-of-the-art models trained on large-scale benchmarks have been pushing the limit of performance rapidly, mainly focusing on improving prediction accuracy. However, those models put less emphasis on efficiency, which is critical for real-time applications. This paper proposes an attention-based graph model named GATraj with a much higher prediction speed. Spatial-temporal dynamics of agents, e.g., pedestrians or vehicles, are modeled by attention mechanisms. Interactions among agents are modeled by a graph convolutional network. We also implement a Laplacian mixture decoder to mitigate mode collapse and generate diverse multimodal predictions for each agent. Our model achieves performance on par with the state-of-the-art models at a much higher prediction speed tested on multiple open datasets.